中国森林地上和地下植被碳储量数据集(2002~2021)
- 时间分辨率:年
- 空间分辨率:0.05° - 0.1°
- 共享方式:开放获取
- 数据大小:896.68 MB
- 数据时间范围:2002-01-01 — 2021-12-31
- 元数据更新时间:2023-02-28
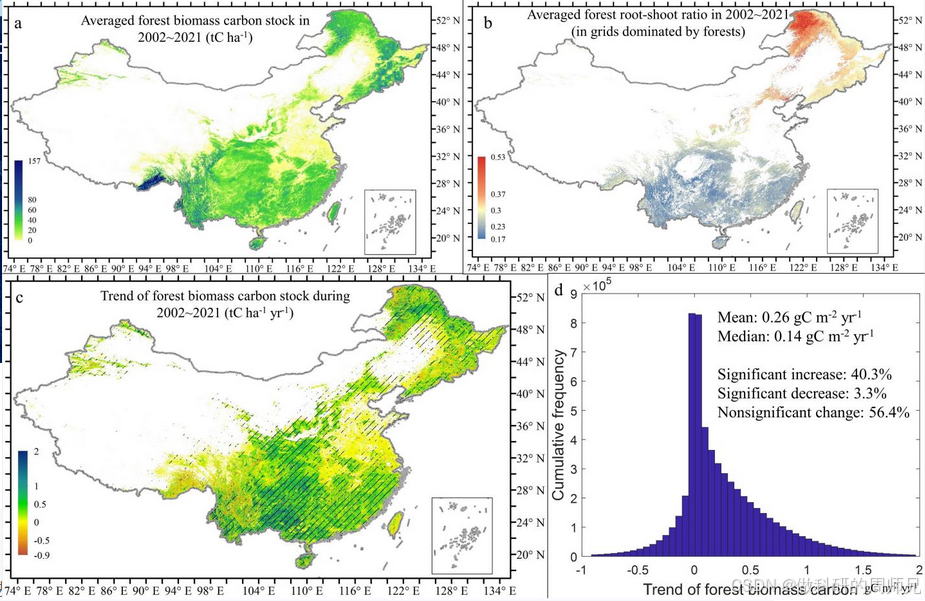
数据集摘要
为准确定量近20年气候变化与人类活动(生态恢复等)对中国森林碳储量的影响,一套高质量的中国长时间序列森林碳储量数据集是很有必要的。通过采用回归与机器学习算法融合高分辨率主动微波遥感、长时间序列的被动微波与光学遥感信息,并参考大量地面样地实测数据,我们发展了一套时空连续的近20年中国森林地上和地下植被碳储量数据。通过与已有数据的对比,发现本数据集可更准确地反映中国森林植被碳储量的空间格局以及年际变化情况。数据的空间分辨率为1/120度(约1km)。
数据文件命名方式和使用方法
AGBC: 地上植被碳储量 BGBC: 地下植被碳储量 文件命名: AGBC或BGBC+ Y + 年份。如文件'AGBCY2002' 代表2002年地上植被碳储量
本数据要求的引用方式
数据的引用
陈永喆, 冯晓明, 傅伯杰. (2023). 中国森林地上和地下植被碳储量数据集(2002~2021). 国家青藏高原科学数据中心. https://doi.org/10.5194/essd-15-897-2023.
Chen, Y., Feng, X., Fu, B. (2023). Above- and belowground forest biomass carbon pool in China during 2002~2021. National Tibetan Plateau / Third Pole Environment Data Center. https://doi.org/10.5194/essd-15-897-2023.
(下载引用: RIS格式 RIS英文格式 Bibtex格式 Bibtex英文格式 )