LLM大模型应用监控---LangChain接入LangFuse进阶篇
接上篇《LLM大模型应用监控—LangFuse使用指南》,本篇详细描述使用LangChain框架接入LangFuse的进阶操作
如何接入
《LLM大模型应用监控—LangFuse使用指南》中已经说过如何注册和创建项目/key,这里不赘述
1. 安装langfuse sdk(版本>3.0)
pip install --upgrade langfuse -i https://mirrors.aliyun.com/pypi/simple/
2. 导入langfuse相关包
from langfuse import Langfuse
from langfuse.langchain import CallbackHandler
3. 配置langfuse key
这里使用的是本地部署的langfuse环境(本地部署参考《LLM大模型应用监控—LangFuse本地部署指南》)
langfuse = Langfuse(public_key="pk-lf-xxxxxxxxxxxxxxx",secret_key="sk-lf-xxxxxxxxxxxxxxx",host="http://x.x.x.x:3000"
)
4. langchain的调用中加入langfuse回调函数
langfuse_handler = CallbackHandler()agent.invoke(question, config={"callbacks": [langfuse_handler]})
langchain中支持的接口:

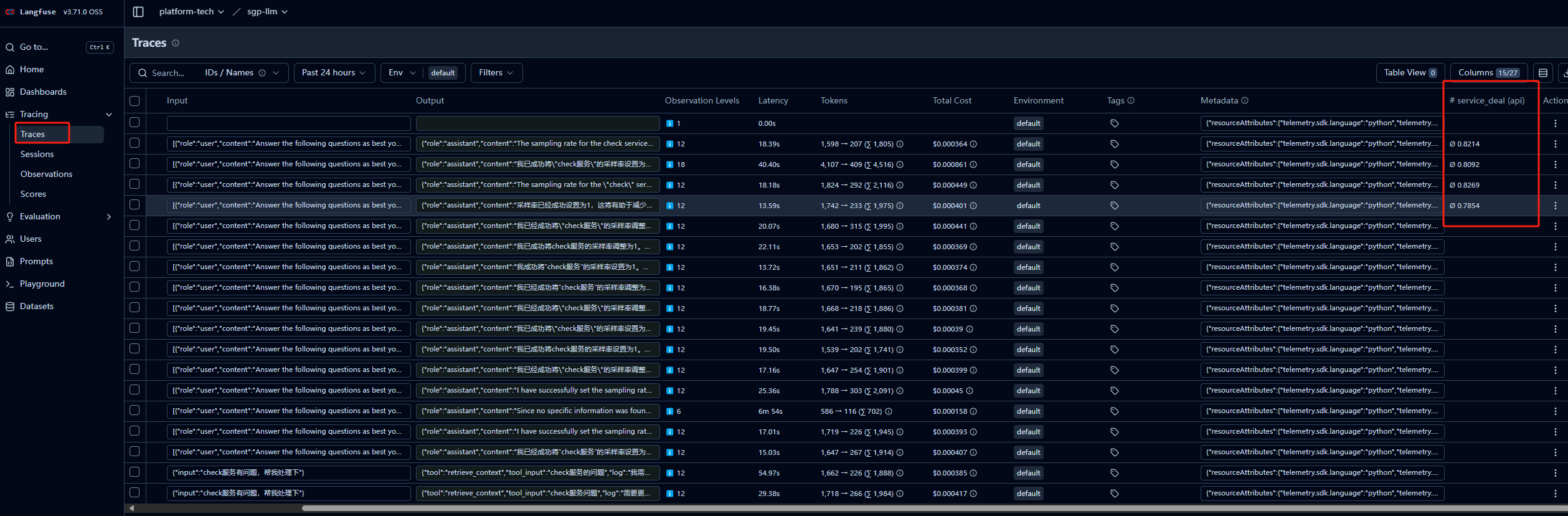
执行后在langfuse中的trace可以看到执行的链路
关联session
与大语言模型(LLM)应用程序的许多交互涉及多个追踪记录。Langfuse中的Sessions是一种将这些追踪记录组合在一起的方式,并且可以查看整个交互过程的简单会话回放。开始时,在创建追踪记录时添加一个sessionId。
将你的langchain应用的sessionid放入metadata中
sessionId = "leon-20250619-1"return agent.invoke(question, config={"callbacks": [langfuse_handler], "metadata": {"langfuse_session_id": sessionId,},})
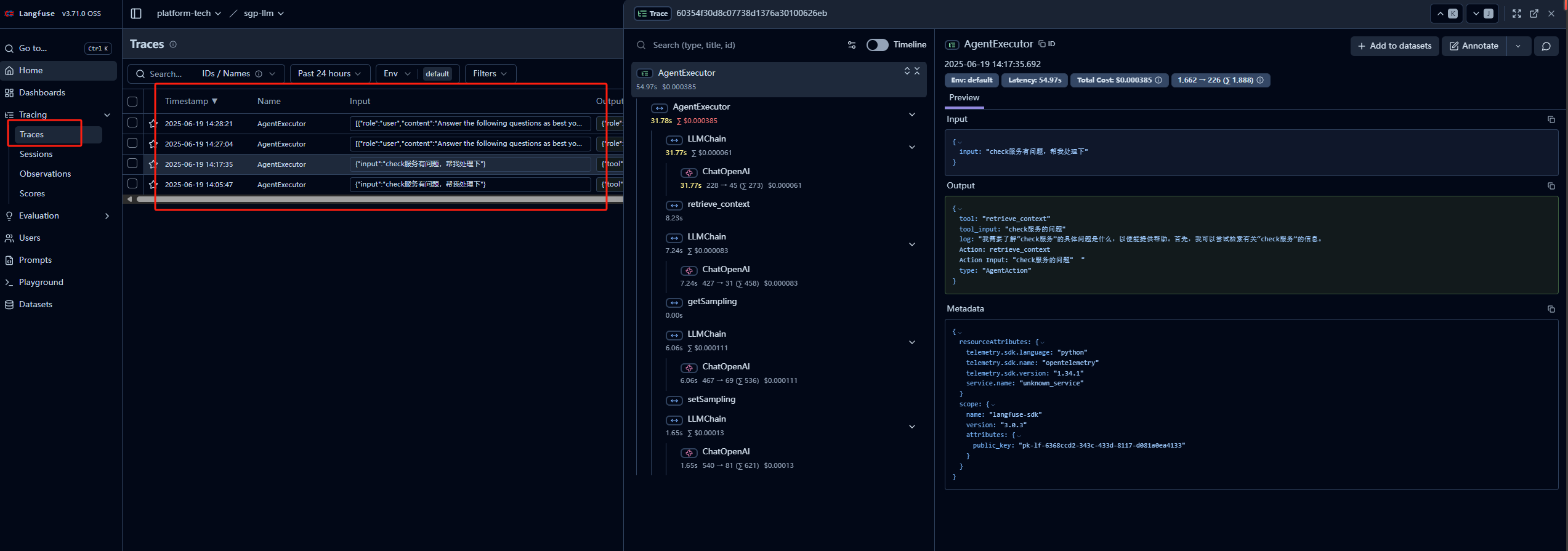
这样同一个session下的trace会被关联到一起,在langfuse中的session菜单中查看

关联用户
在Langfuse中,将数据映射到单个用户很容易。创建trace时,只需传递一个唯一标识符作为userId。这可以是用户名、电子邮件或任何其他唯一标识符。userId是可选的,但使用它可以帮助您从Langfuse中获得更多价值。详细信息请参阅集成文档。
将你的langchain应用的userid放入metadata中
userId = "leon"return agent.invoke(question, config={"callbacks": [langfuse_handler], "metadata": {"langfuse_user_id": userId,},})
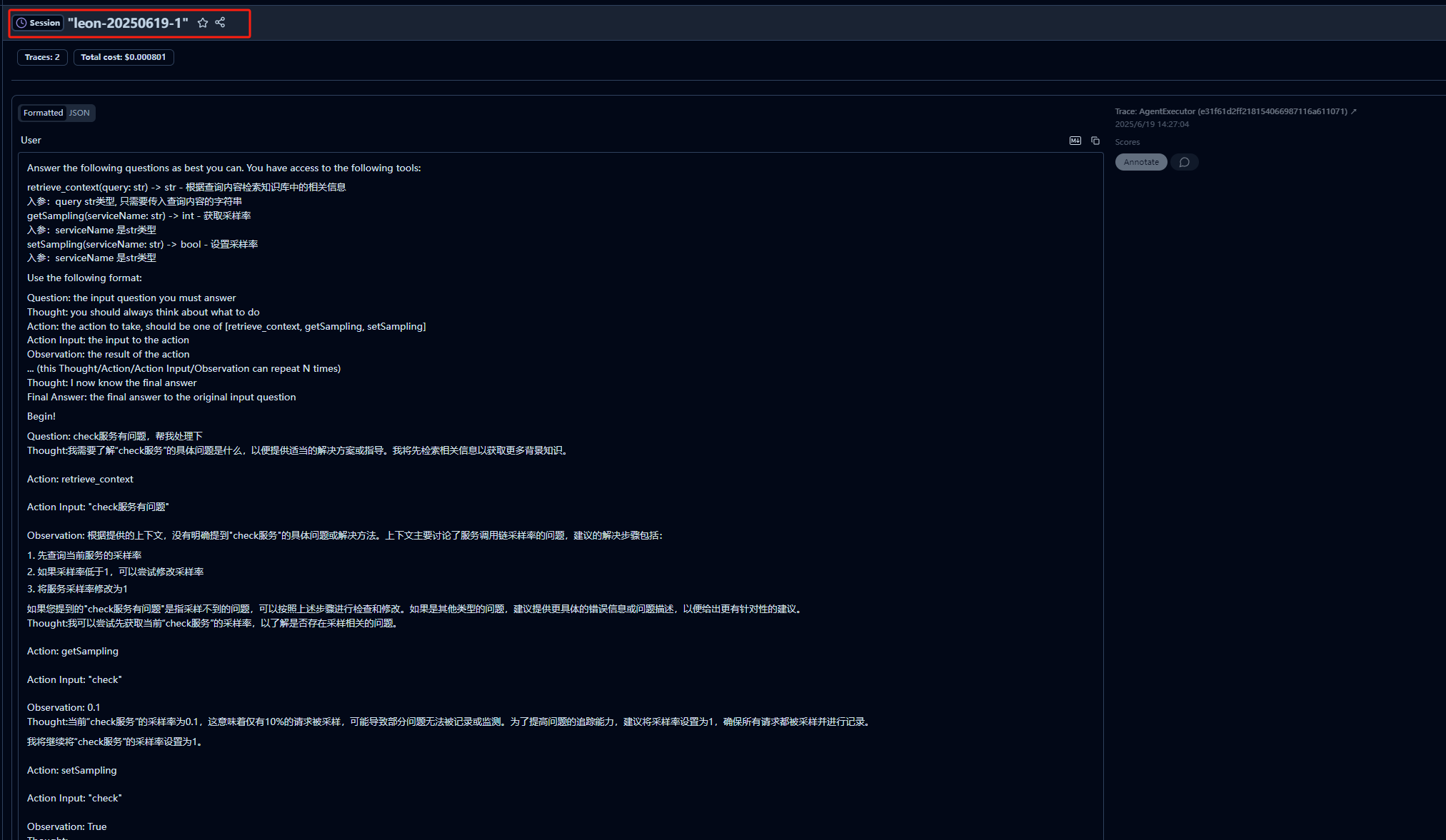
这样同一个user的trace会被关联到一起,在langfuse中的user菜单中查看

该页面关联用户下的session和trace

使用自定义traceName
trace_name = "langfuse-demo-agent"return agent.invoke(question, config={"callbacks": [langfuse_handler], "metadata": {"name": trace_name},})

可以在检索页面根据name查询

获取traceId
在应用中获取本次执行的traceId 并打印在日志中或返回给前端,方便获取
with langfuse.start_as_current_span(name = trace_name) as span:trace_id = langfuse.get_current_trace_id()print("traceId is:")print(trace_id)return agent.invoke(question, config={"callbacks": [langfuse_handler], "metadata": {"langfuse_session_id": sessionId,"langfuse_user_id": userId,"name": trace_name},})

获取到traceid后可以在检索页面根据id查询

自定义得分
Langfuse让你可以通过Langfuse SDK或API,灵活引入自定义scores。评分工作流程使你能够在运行时对工作流程的输出进行自定义质量检查,或者运行自定义人工评估工作流程。
你可以通过Langfuse软件开发工具包(SDK)或应用程序编程接口(API)添加分数。分数可以采用以下三种数据类型之一:
数值型:用于记录落在某个数值范围内的分数
分类的:用于记录字符串分数值
布尔值:用于记录二元分数值
评估的基本方式:
- 指定捞取已经执行过的traces
- 使用自定义评估函数或外部评估函数(Deepeval框架)对捞到的trace的结果做评分
- 将trace的得分贯穿到langfuse并展示
这里我们使用deepeval评估函数(原理也是通过大模型来做评估)
安装包
pip install deepeval -i https://mirrors.aliyun.com/pypi/simple/
导入
from deepeval.metrics import GEval
from deepeval.test_case import LLMTestCaseParams, LLMTestCase
设置OPENAI的key和url
os.environ["OPENAI_API_KEY"] = api_key
os.environ["OPENAI_BASE_URL"] = base_url
定义一个评分函数,用来评价这次的问答得分和原因
def service_deal_score(trace):service_deal_metric = GEval(name="Correctness",criteria="评估用户提到的服务问题是否被正确处理",evaluation_params=[LLMTestCaseParams.ACTUAL_OUTPUT],model="gpt-4o-mini")# 确保 trace.input 是合法结构if not trace.input or not isinstance(trace.input, list) or not trace.input[0]:input_text = ""else:input_text = trace.input[0].get("args", "")test_case = LLMTestCase(input=input_text,actual_output=trace.output)service_deal_metric.measure(test_case)print(f"Score: {service_deal_metric.score}")print(f"Reason: {service_deal_metric.reason}")return {"score": service_deal_metric.score, "reason": service_deal_metric.reason}
分批次捞trace,每个trace调用一次评分函数,将结果推送到langfuse
for page_number in range(1, math.ceil(TOTAL_TRACES/BATCH_SIZE)):traces_batch = langfuse.api.trace.list(page=page_number,from_timestamp=yesterday,to_timestamp=datetime.now(),limit=BATCH_SIZE).datafor trace in traces_batch:print(f"Processing {trace.name}")if trace.output is None:print(f"Warning: \n Trace {trace.name} had no generated output, \it was skipped")continuelangfuse.create_score(trace_id=trace.id,name="service_deal",value=service_deal_score(trace)["score"],comment=service_deal_score(trace)["reason"])print(f"Batch {page_number} processed 🚀 \n")
执行后的结果:

langfuse中score菜单可以看到所有评估得分和原因
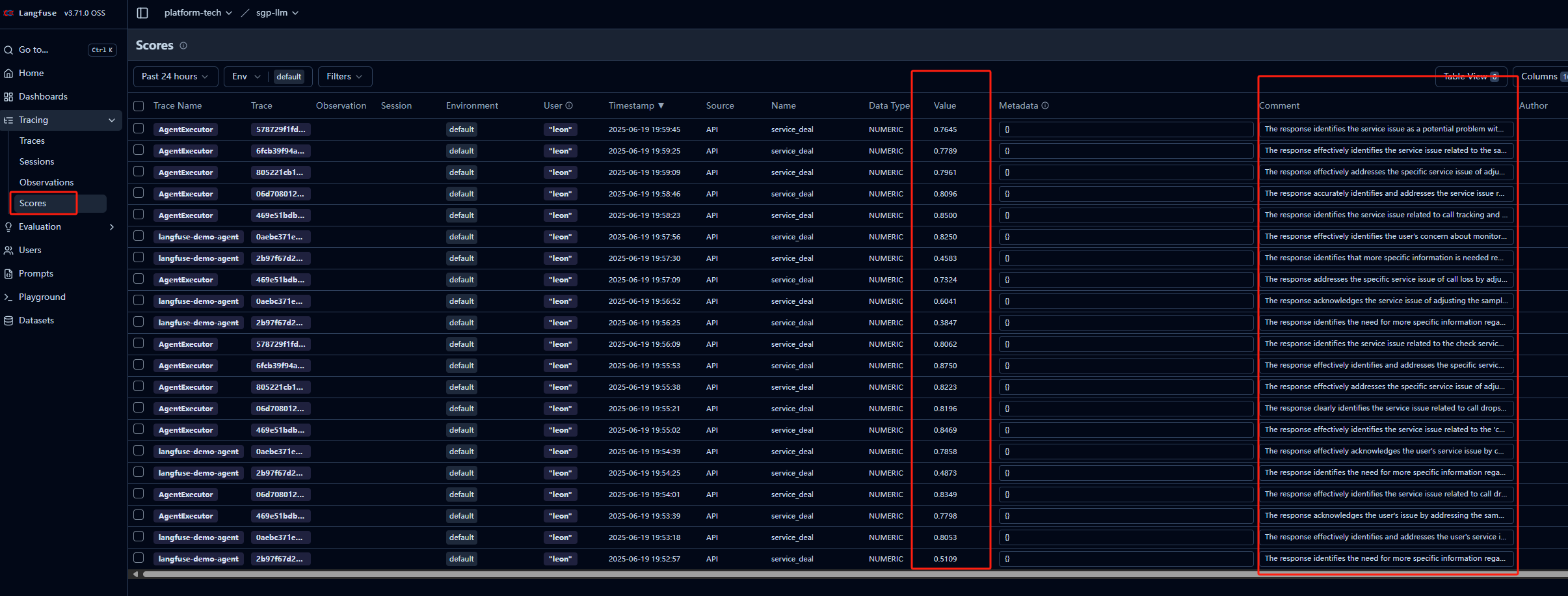
每个trace也关联了得分