网络编程及原理(五)
目录
一 . TCP 的核心机制:可靠传输
二 . 确认应答
为什么网络中会存在后发先至呢?
解决办法:
三 . 超时重传
TCP 是如何对抗丢包的呢?
超时重传的时间设定
OKK,今天咱们继续来学习网络编程及原理。
一 . TCP 的核心机制:可靠传输
首先我们得知道,“ 可靠传输 ” 并不能做到 100% 送达,毕竟网络传输这一块,存在太多的不必要因素,我们只能尽可能的保证数据能达到对方,那么为了完成这一过程,我们就需要做两件事:
1 . 能感知到对方是否收到
2 . 如果发现对方没有收到,就要进行重试
那么怎样才能感知到对方有没有收到呢?这就涉及到了我们 TCP 的核心机制:
二 . 确认应答
如何感知对方到底收没收到我们发出的消息呢?这不是一个很高深的技术问题,非常朴素。靠的就是对方的回应,咱们发送数据过去,对方收到了,就需要回应我们一声,当我们成功收到了对方的回应,那此时就感知到了对方已经收到信息了。
那么对方返回给我们的这一条消息,就被称为我们的 “ 应答报文(acknowledge,简称 ack)”
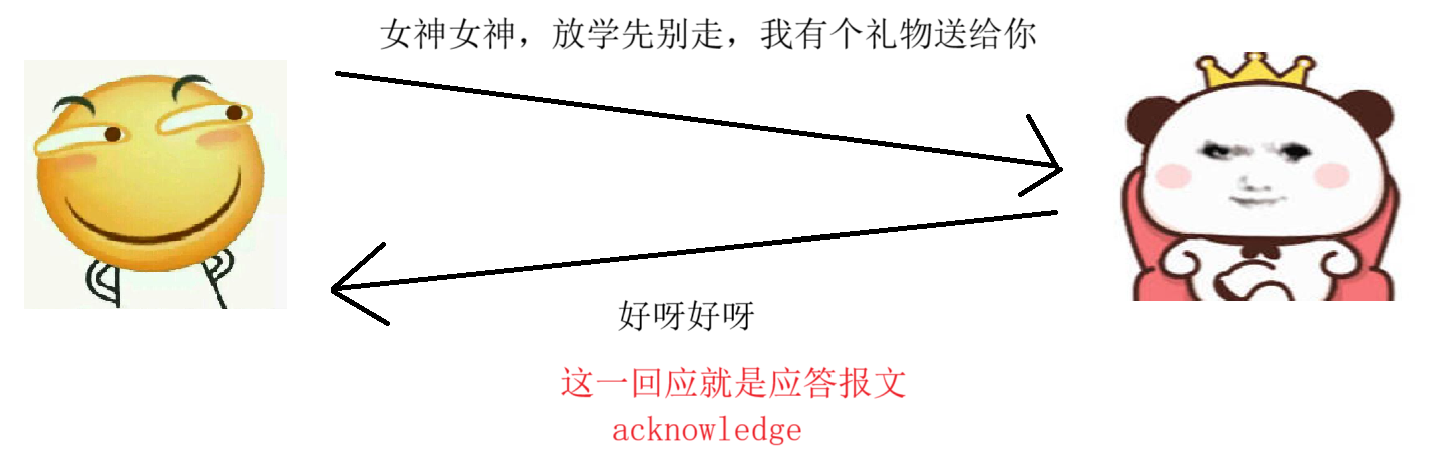
但是,上述这一应答报文的机制还存在问题,就是当我们发送多条消息的时候,可能存在歧义:
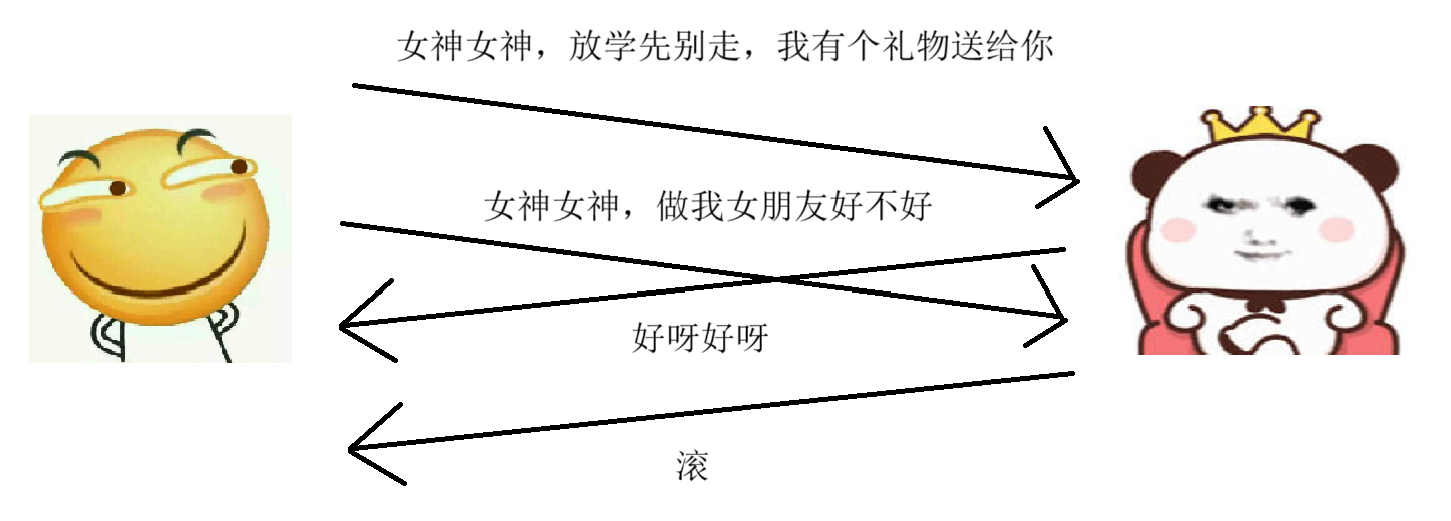
但其实这种情况,还不足以让我们产生歧义,因为我们默认的是按照顺序来处理信息的嘛,我们就知道第一个回答对应我们的第一句话,第二个回答对应我们的第二句话。
但是,我们多次提到过了,在我们的网络传输中有很多不确定因素会影响到我们的传输,这就导致存在一种情况:后发先至
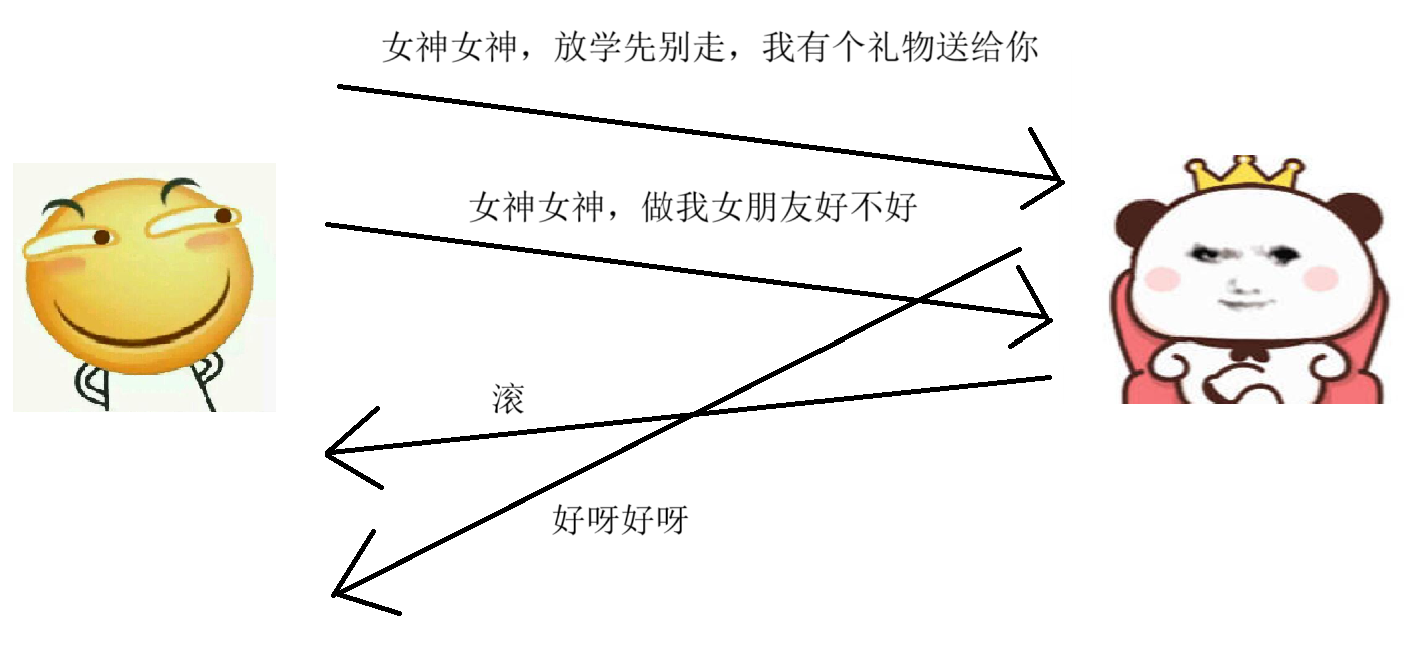
大家看,这种情况是不是就可能会产生歧义啦,哎,女神不愿意收我的礼物,但是愿意做我女朋友,嗯嗯,不拜金,是个好女孩,哈哈哈。
为什么网络中会存在后发先至呢?
这就涉及到很久很久以前,久远到我们 “ 互联网的源头 ”,互联网的研究是为了用来防御核打击的,因为我们传输数据如果只走一条固定的线路的话,这样子被打击摧毁了,那就完了,整个通信系统就崩溃了,这时再想要拿捏你那还不是瓮中捉鳖。所以我们网络传输数据的线路是有很多很多条的,且每次发消息,这条数据会走哪条道路是随机的,这样子就保证了不可能一次性把所有线路都摧毁完。因此由于线路不同,每条线路的过程也大小不一,这就存在了 “ 后发先至 ” 这种情形。
解决办法:
这种后发先至的情形是客观情况,无法改变,那我们是不是就对这种 “ 隐患 ” 束手无策呢?那当然不是啦,只要思想不滑坡,办法总比困难多嘛。在 TCP 中就用了一种方法来解决这个问题,也不是大家想象的那种多么高大上的复杂的技术,就是:编号
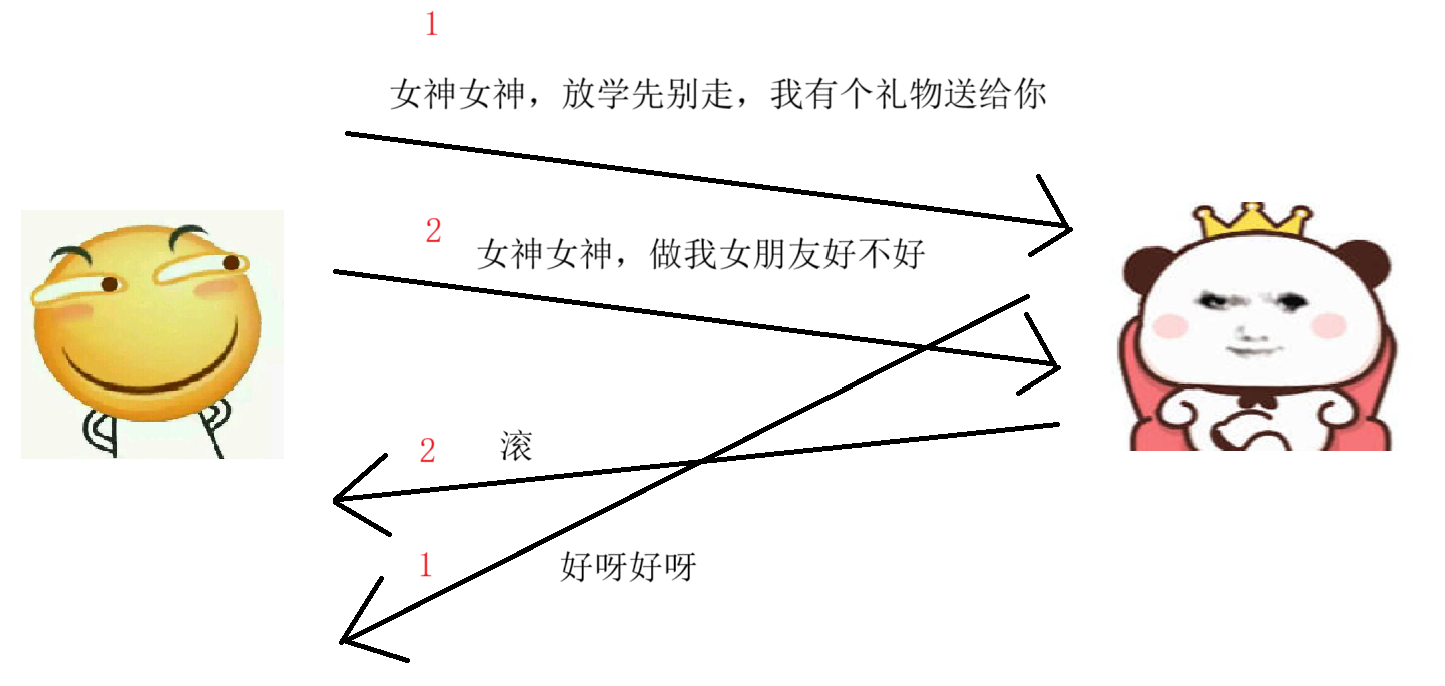
就像这样,即使在传输过程中因为一些不可抗力的因素导致顺序出现差错,但是我们从收到的应答报文还是能很轻松的看出哪一条是针对哪一条的答复,这样就很简单的就解决了这个问题嘛。
事实上,由于 TCP 是面向字节流的,所以实际上的编号并不是 “ 第一条 ”、“ 第二条 ” . . . 这样的,而是“ 第一个字节 ”、“ 第二个字节 ” . . .
每一个字节都有一个独立的编号,字节与字节之间是连续且递增的。这种按照字节编号的机制我们就称之为 “ TCP 的序号 ”,在应答报文中,针对之前收到的数据进行应对的编号,我们就将其称之为 “ TCP 的应答序号 ”。
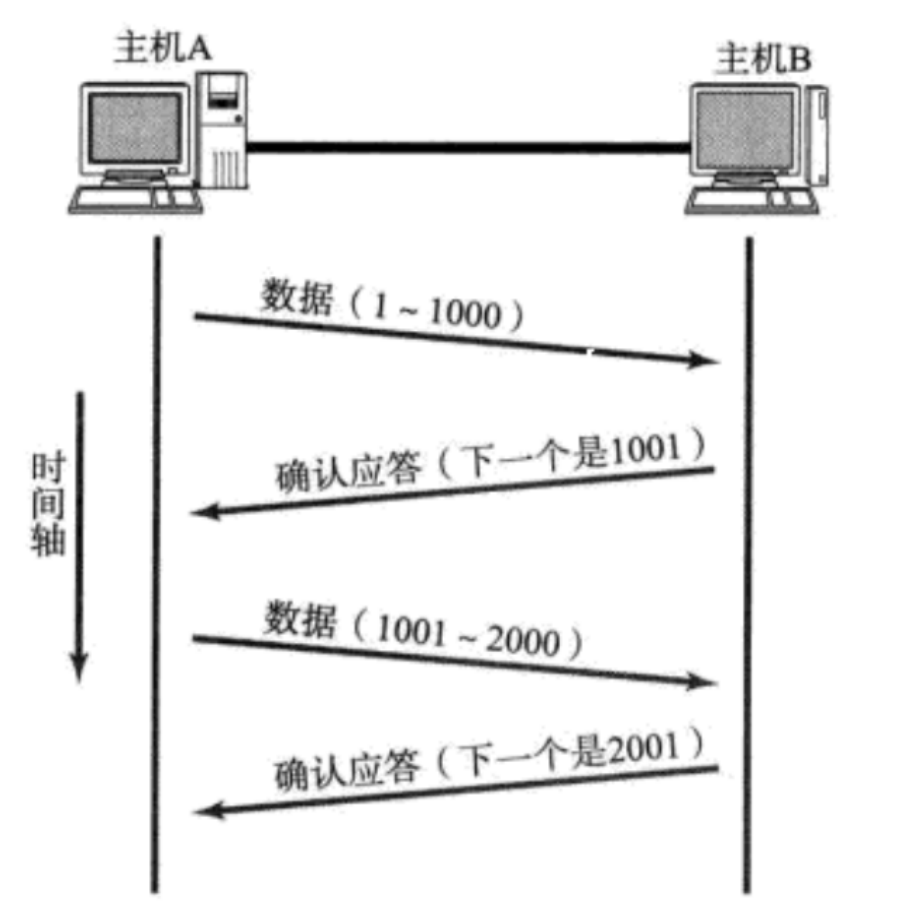
TCP 中的序列号是按照字节来表示的,我们的确认序号就是收到数据的最后一个数据的下一位,表示在这个字节之前的所有数据都收到了。
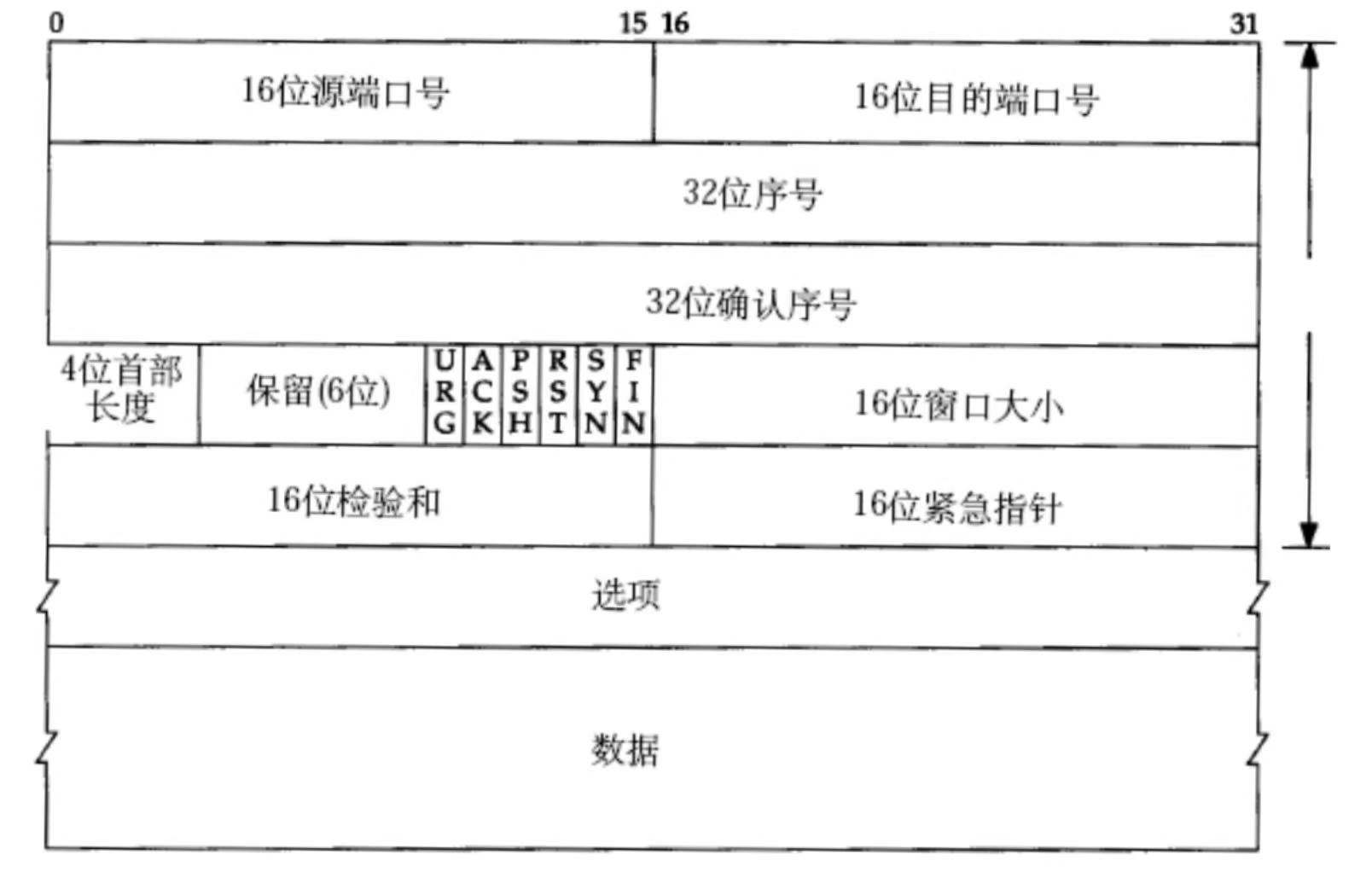
值得注意的是,在我们 TCP 的六个标志位的第二个:ACK,这个标志位是会变化的,用来确定我们的报文类型,对于普通报文,ACK 就是 0 ;对于应答报文,ACK 就是 1 。如果是普通报文,序号是有效的,确认序号是无效的;如果是应答报文,序号与确认序号都是有效的。
这里我们再来看一种后发先至的情况:
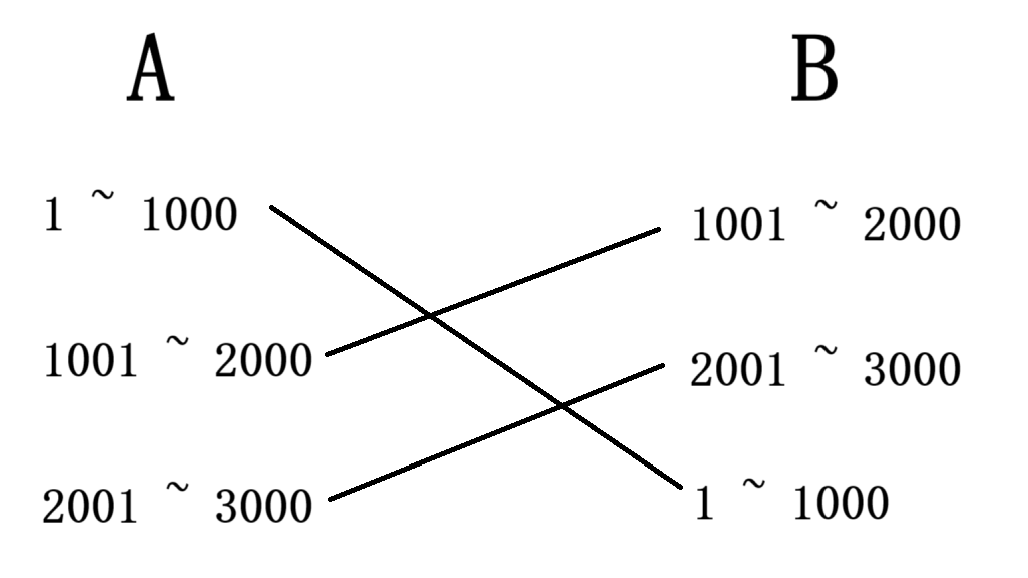
我们的数第一个发送的数据最后一个到,当我们 B 接受到第一个数据 1001 ~ 2000 时会是怎样的情形呢?前面说过,我们 TCP 传输数据的字节是连续且递增的,所以当我们接受方这边调用 read 如果发现没有数据时(本质上就是 InputStream . read),就会阻塞等待,虽然我们 1001 ~ 2000 的数据到了,但没有起始数据,还是会继续阻塞等待,直到 1 ~ 1000 这段数据到了之后,我们接受方这边就会结束阻塞,重新洗牌,将这些数据调整为正确的顺序,再发送应答报文。
从这一点我们可以感受到,在我们接收方 B 这里,是有一段内存空间,作为 “ 接收缓冲区 ” 的。
三 . 超时重传
我们已经不止一次的提到过了,在网络传输的过程中有很多不确定因素,很容易出错,发生我们所谓的 “ 丢包 ” ,产生丢包的原因有很多种,例如:
(1)数据在传输的过程中,发生了 bit 翻转,收到这个数据的接收方 / 中间的路由器这些在计算校验和的时候发现校验和对不上了。
(2)数据传输到某个节点(路由器 / 交换机),这个节点负载太高了(比如某个路由器 单位时间内只能转发 N 个包,但是现在是网络高峰期,突破阈值了),后续传输过来的数据就可能直接被丢弃掉了。
发生丢包是完全随机不可预测的。
TCP 是如何对抗丢包的呢?
TCP 能做到的就是,感知到数据丢包的时候,再重新传一次。
如何检测是否丢包呢?这就是靠我们的 “ 应答报文 ” 来区分了,成功收到应答报文,说明数据没有丢包,反之,没收到应答报文,就证明丢包了。
那么怎样才算没收到呢?数据的网络传输是需要消耗时间的,在我们发送方发送完数据之后,会给出一个时间限制,如果在这个时间限制之内,没有收到 ACK ,就视为丢包了。
丢包有两种情况:
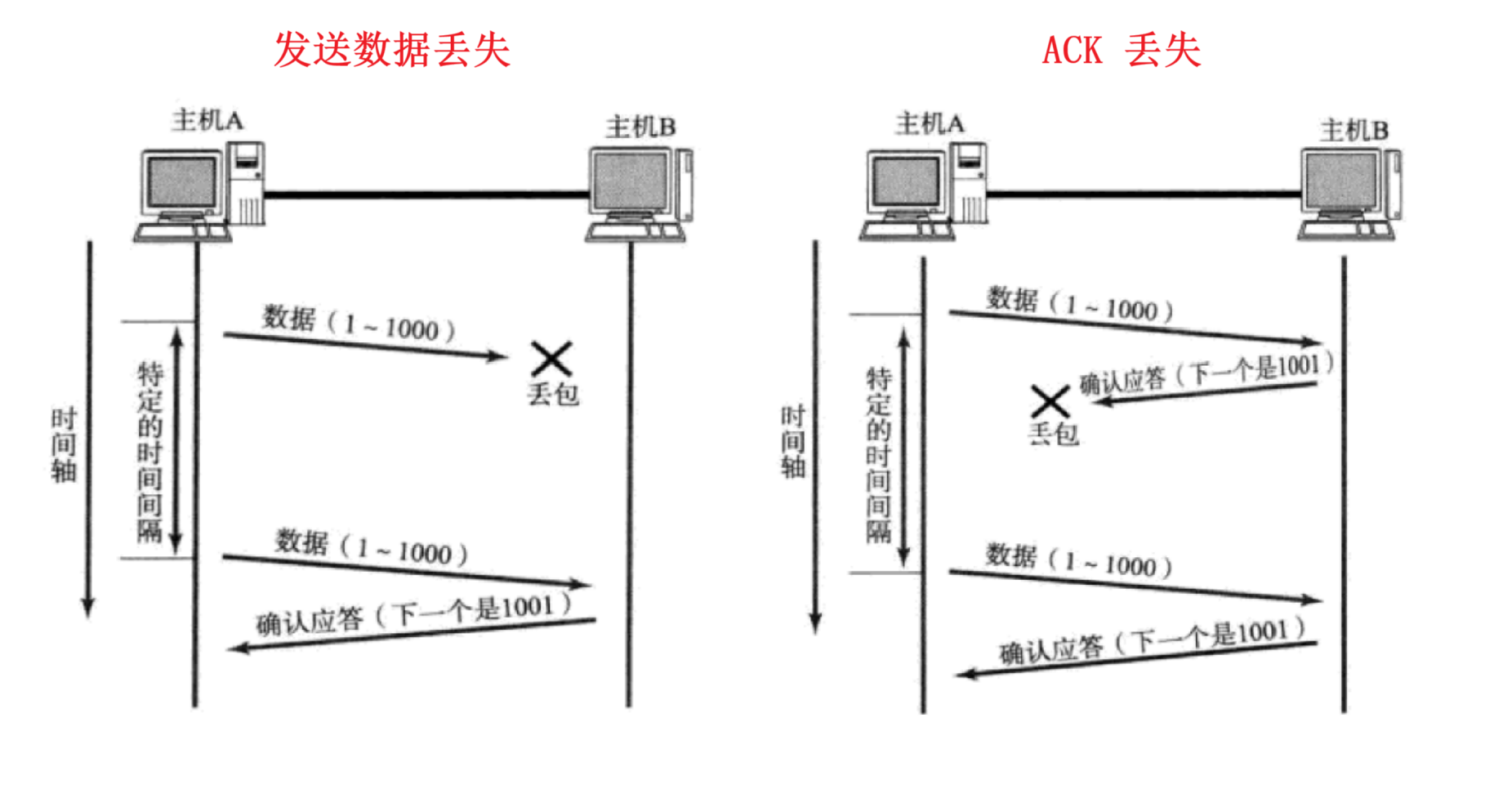
第一种没什么好说的是吧,那么针对第二种我们已经有一份数据了,再传过来一份一模一样的数据,我们该怎么办呢?都接收了有没有什么影响呢?
可能有的小伙伴觉得没什么影响是吧,一模一样的数据,能有什么呢?但是,我们想一下,如果是一种 “ 扣款操作 ” 呢?那因为这个丢包问题就要扣我们两次款,我只吃了一碗粉,你硬要我给两碗粉钱,这怎么行呢?

所以针对这种情况我们怎么办呢?前面我们说到过,接受方有一个缓冲区,收到的数据先进入缓冲区等待阻塞,如果此时我们再收到了一份一模一样的数据,且我们的没份数据都是有编号的,就像一张车票,当我们这份数据拿着这张车票在缓冲区找到了他的位置时,发现它的 “ 位置上 ” 已经有一份一模一样的数据了,这时候就会直接遵循 “ 先来后到 ” ,直接把这个新的数据给丢弃掉。这就是去重操作,确保应用程序调用 read 读出来的数据是唯一的,不可重复的。
超时重传的时间设定
超时重传的时间设定是动态的,并不是我们想的那样固定的。
比如:发送方第一次超时重传时间的时间是 t1 ,在重传之后 t1 时间内,仍然没有收到 ACK ,还会第二次重传,第二次时间就是 t2 。且 t2 > t1 ,每多重传一次,时间间隔就会变大,也就是重传的频率就会减低。
重传并不会无休无止的进行,当重传达到一定次数之后,TCP 就不会尝试重传了,它会认为这个链接已经挂掉了,这个时候它会尝试进行 “ 重置 / 复位连接 ” ,发送一个特殊数据包:“ 复位报文 ”,如果这会儿网络恢复了,复位报文就会重新连接,我们的数据通信就可以正常进行。如果网络还是有很严重的问题,复位报文也没有得到回应,此时 TCP 就会单方面放弃连接了。
连接就是通信双方各自保存的对方的信息,当发送方释放掉之前保存的接收方的信息,这个链接也就挂掉了。
OKK,今天就讲到这里吧,主要就说了 TCP 的可靠性传输的两种核心机制:确认应答和超时重传,这两点很重要,是保证 TCP 可靠性传输的最核心的机制,大家一定要牢记!好了,就这样吧,咱们下期再见咯,与诸君共勉!!