强化学习鱼书(10)——更多深度强化学习的算法
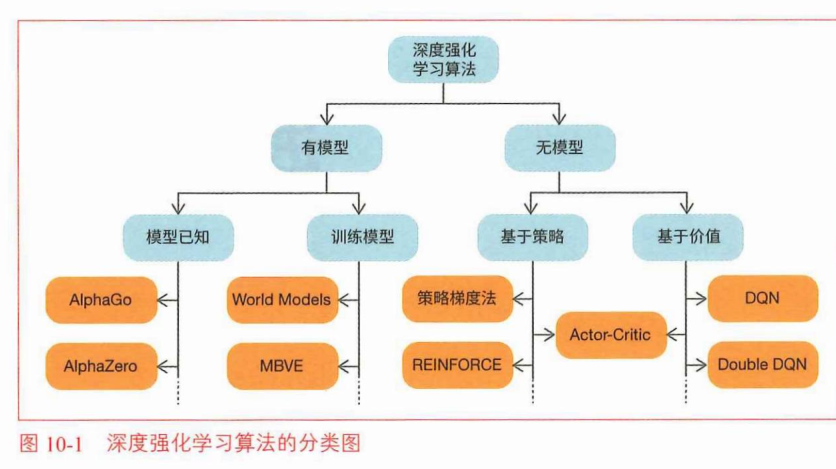
:是否使用环境模型(状态迁移函数P(s’|s,a)和奖
励函数r(s,a,V))。不使用环境模型的方法叫作无模型(model-free)的方法,使用环境模型的方法叫作有模型(model-based)的方法。
模型的方法可以分为两种,一种是提供了环境模型的方法,另一种是训练环境模型的方法。
- 如果提供了环境模型,那么智能代理可以通过规划(planning)来解决问题,而不采取任何行动。
- 如果没有提供环境模型,则可以考虑根据从环境中获得的经验来训练环境模型(行动-奖励-策略/价值优化)。训练的环境模型除了可以用于规划之外,还可以用于评估和改进策略。
策略梯度法的改进算法
A3C
A3C是 Asynchronous Advantage Actor-Critic 的缩写。
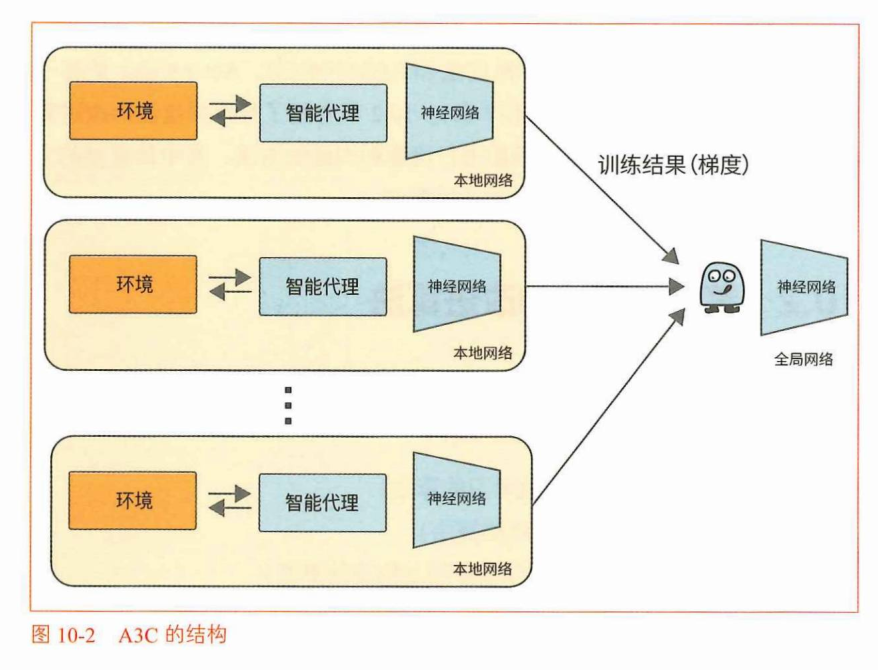
本地网络在各自的环境中独立进行训练。然后它们会将作为训练结果的梯度发送到全局网络。全局网络使用来自多个本地网络的梯度异步更新权重参数。这样,在更新全局网络的权重参数的同时,可以定期同步全局网络和本地网络的权重参数。
多个智能代理的并行运行,可以不依赖于经验回放而减少数据的相关性。
另外,A3C的Actor-Critic将共享神经网络的权重。(需要多个环境并行同时运行)
A2C是同步更新参数的方法,它不采取异步更新参数的方式。(多了采样过程)
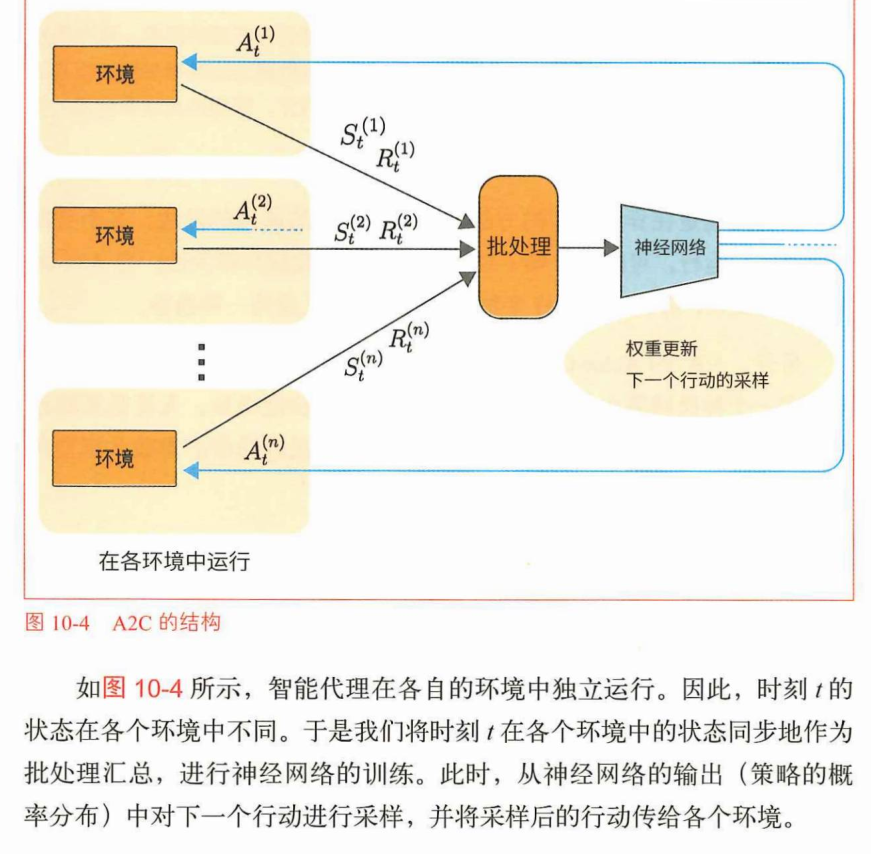
更详细的说明
https://zhuanlan.zhihu.com/p/65068744
DDPG
DDPG 是 Deep Deterministic Policy Gradient (深度确定性策略梯度法)的缩写。从名字就能想到它的含义,它是针对连续行动空间问题而设计的算法。神经网络可以将行动作为连续值直接输出
回顾DQN:
- 经验回放:取出一个batch的数据
- 目标网络:一个表示Q函数的原始网络(这个网络叫作qnet),再准备了一个具有相同结构的网络计算TD目标的值(这个网络叫作qnet_target),定期与qnet的权重同步,在其余的时间里保持权重参数固定。
DDPG:

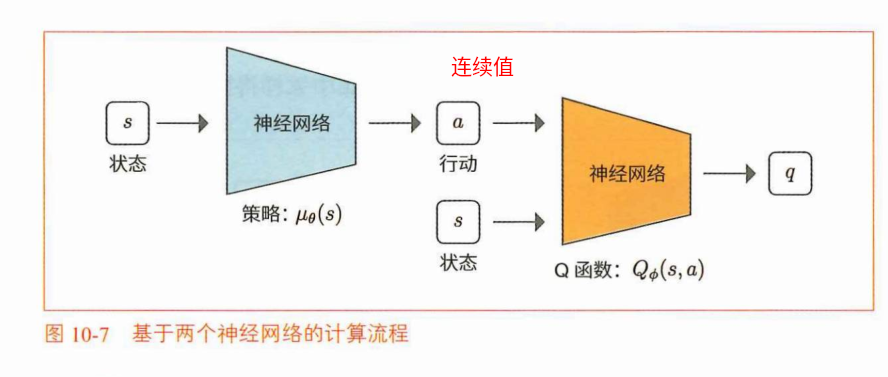
(1)中输出的行动a是连续值,该值可直接作为Q的输入。这样就能通过两个神经网络进行反向传播了。通过反向传播可以求梯度▽q(这里的是Q函数的输出)。这样就能使用梯度▽q更新参数了。
(2)是在DQN中进行的Q学习
更详细的说明
https://zhuanlan.zhihu.com/p/111257402
TRPO 和 PPO
https://zhuanlan.zhihu.com/p/111049450
DQN的改进算法
分类 DQN
DQN在Q学习中要训练的是由Q函数这个期望值所表示
的值。进一步扩展这个思路,不要训练Q函数这个期望值,而要训练“分布”。这个思路叫:分布强化学习(distributional reinforcement learning)。分布强化学习将训练收益Zpai(s,a)的概率分布。
Noisy Network
DQN根据s-greedy算法选择行动。也就是说,DQN会以e的概率随机选择行动,以1-e的概率选择贪婪的行动(函数值最大的行动)。在实践中,我们常常要进行“调度设置” (schedule setting),即随着回合的发展,逐渐降低e的值
代替e:Noisy Network:
在输出侧的全连接层中使用有噪声的全连接层。在有噪声的全连接层中,权重会被建模为正态分布的均值和方差,并在每次前向传播时从正态分布对权重进行采样。
Rainbow
Ape-X/R2D2/NGU
在多个运行环境中进行训练的做法也被称为“分布式强化学习”