RM-R1:基于推理任务构建奖励模型
摘要:奖励建模对于通过人类反馈的强化学习使大型语言模型与人类偏好对齐至关重要。为了提供准确的奖励信号,奖励模型(RM)在分配分数或判断之前应该激发深度思考并进行可解释的推理。受最近在推理密集型任务中长链推理的进展启发,我们假设并通过验证表明,将推理能力整合到奖励建模中可以显著增强奖励模型的可解释性和性能。为此,我们引入了一种新的生成式奖励模型类别——推理奖励模型(REASRMS),它将奖励建模视为一项推理任务。我们提出了一个以推理为导向的训练流程,并训练了一系列REASRMS,例如RM-R1。RM-R1的特点是采用了评分标准链(CoR)机制——自动生成样本级别的聊天评分标准或数学/代码解决方案,并将候选回答与之进行对比评估。RM-R1的训练包括两个关键阶段:(1)高质量推理链的提炼;(2)带有可验证奖励的强化学习。在经验上,我们的模型在三个奖励模型基准测试中平均达到了最先进的性能,超过了更大规模的开源模型(例如INF-ORM-Llama3.1-70B)和专有模型(例如GPT-4o)高达4.9%。除了最终性能外,我们还进行了深入的经验分析,以了解成功训练REASRM的关键要素。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 推理蒸馏阶段
3.2 强化学习阶段
3.3 链状评分机制
编辑
四、实验结论
4.1 性能优势
4.2 关键组件有效性
4.3 可解释性提升
五、总结
一、背景动机
大模型在通过强化学习(RLHF)与人类偏好对齐的过程中,奖励模型(RM)至关重要,其核心在于提供准确的奖励信号,现有奖励模型存在显著缺陷
- 标量奖励模型(ScalarRM):虽直接有效,但决策过程不透明,缺乏中间推理步骤,难以处理需要深度推理的复杂偏好任务。
- 生成式奖励模型(GenRM):虽具备一定透明度,但推理往往停于表面,导致判断不可靠,性能欠佳。
基于上述缺陷,文章引入了一种新的生成式奖励模型类别——推理奖励模型(REASRMS),它将奖励建模视为一项推理任务。我们提出了一个以推理为导向的训练流程,并训练了一系列REASRMS。

二、核心贡献
1、提出推理奖励模型:首次将奖励建模定义为推理任务,通过引入长推理链增强模型对复杂输出的评估能力,显著提升可解释性与性能。
2、设计RM-R1模型与训练框架
- 推理蒸馏(Reasoning Distillation):利用高质量合成推理轨迹(如通过Claude-3、OpenAI-O3生成)对指令调优模型(如Qwen-2.5)进行蒸馏,赋予模型基础推理能力。
- 强化学习(RL):通过可验证奖励(RLVR)优化模型泛化能力,解决蒸馏阶段可能存在的过拟合问题。
3、链状评分机制:模型先判断任务类型(聊天/推理),对聊天任务生成评估标准(如同理心、心理安全),对推理任务(如数学、代码)则先自行解题再评估,实现任务感知的动态评估策略。
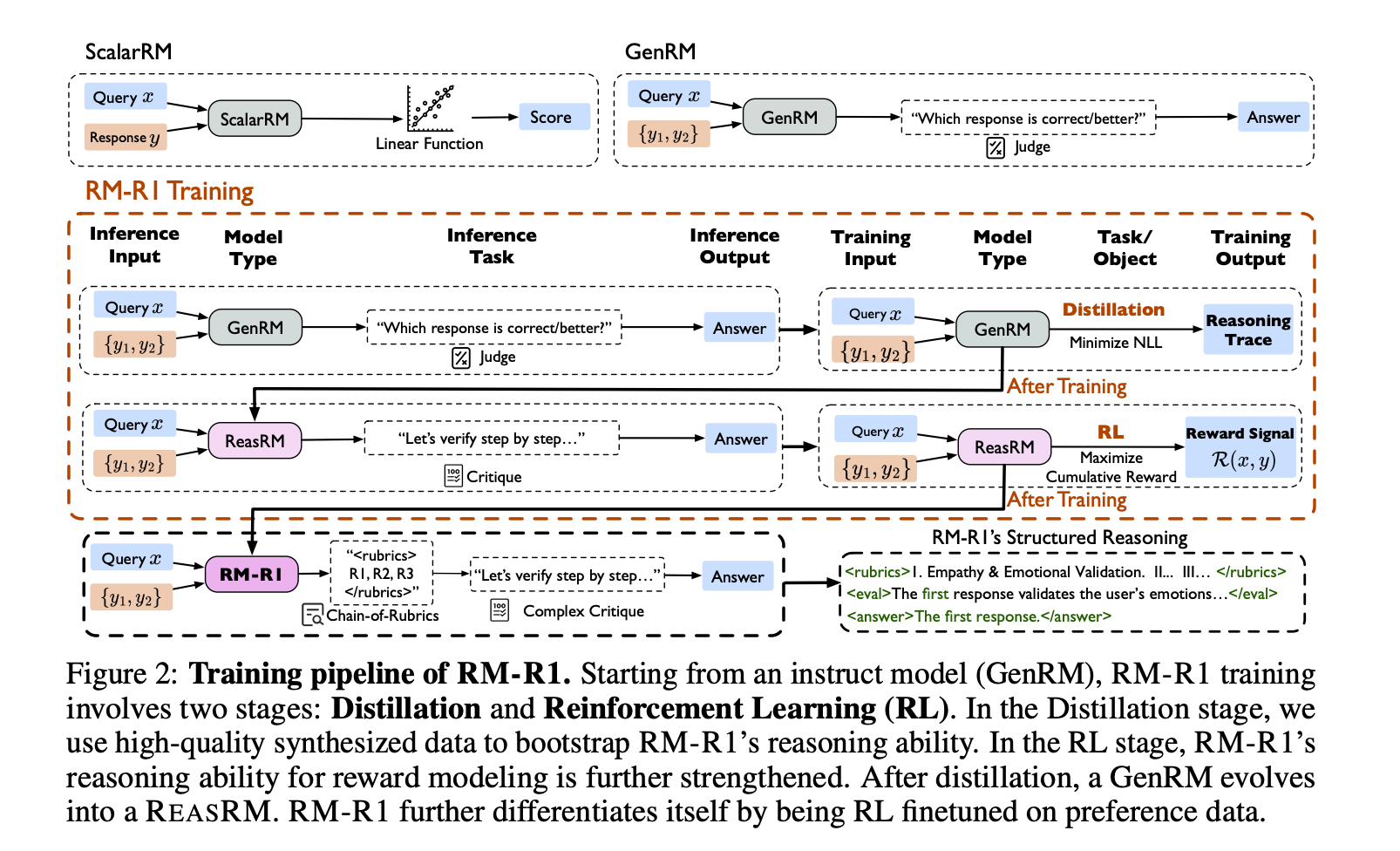
三、实现方法
3.1 推理蒸馏阶段
- 数据生成
- 使用Claude-3生成初始推理轨迹。
- 对约 25% 的错误轨迹(尤其是复杂聊天任务),使用 OpenAI-O3 基于正确标签 l 生成修正后的推理轨迹,确保逻辑一致性。
- 使用推理轨迹和标签构建包含推理过程与标签的蒸馏数据集。
- 训练目标:通过最小化负对数似然(NLL)损失,优化模型生成推理轨迹和正确标签的能力。
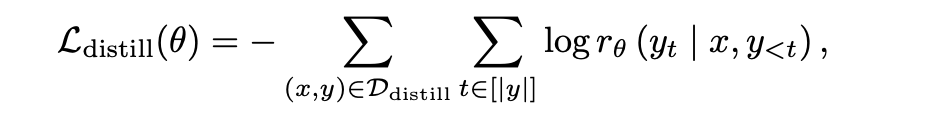
3.2 强化学习阶段
- 正确性奖励:仅基于预测标签是否正确(正确+1,错误-1),简化奖励信号以聚焦核心能力
- 优化算法:基于GRPO利用多样本平均奖励作为基线,提升训练稳定性。
3.3 链状评分机制
- 模型首先判断任务类型为 聊天(Chat) 或 推理(Reasoning),并执行不同评估逻辑。
聊天任务(如情感支持、安全问题)
1、生成任务特定评估标准(Rubrics),如 “同理心”“心理安全”“建设性指导”,并分配权重(如同理心 40%)。
2、基于 rubrics 对比响应,如分析候选响应是否符合情感支持目标。
推理任务(如数学、代码)
1、模型先自行解决问题,生成标准答案
<solution>...</solution>。2、基于正确性、完整性评估候选响应,如对比代码是否包含逻辑错误。
通过结构化提示引导模型生成可验证的推理轨迹。
- 聊天任务提示示例
<type>Chat</type> <rubric> <item>Empathy & Emotional Validation</item> (40%) <item>Psychological Safety / Non-Harm</item> (30%) <justify>情感类任务需优先确保用户心理安全...</justify> </rubric> <eval>对比响应A和B的同理心表达...</eval> - 推理任务提示示例
<type>Reasoning</type> <solution>计算步骤与正确答案...</solution> <eval>响应A的代码在第3行存在语法错误...</eval>

四、实验结论
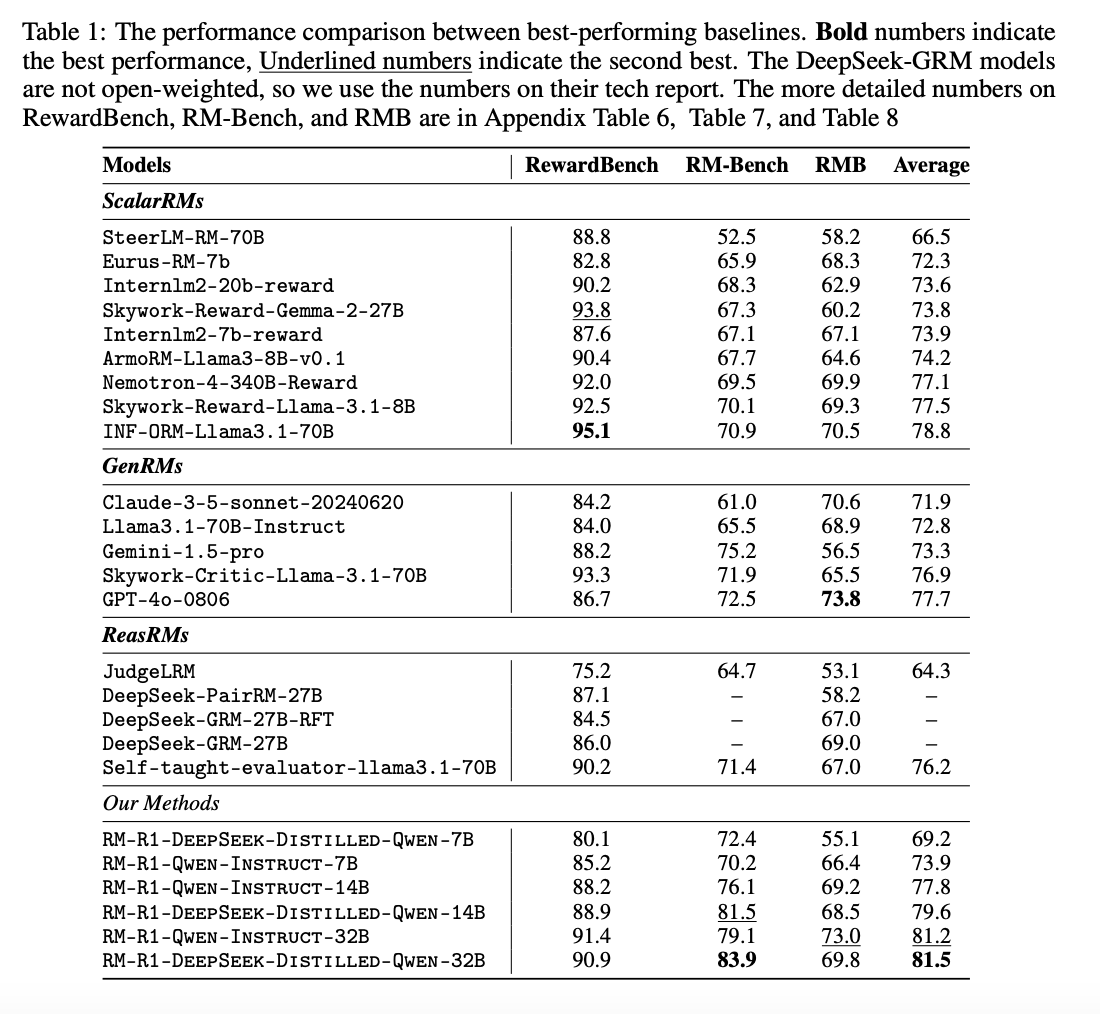
4.1 性能优势
- RM-R1 在三大基准上平均性能超越现有模型 4.9%,且参数量显著更小(如 32B 模型优于 70B/340B 模型)。
- 在推理密集型任务(如 RM-Bench 的数学、代码任务)中优势显著:32B 模型在数学任务中准确率达91.8%,远超基线模型(如 INF-ORM-Llama3.1-70B 的 65.6%)。
4.2 关键组件有效性
- 推理蒸馏:显著提升模型泛化能力,消融实验显示仅用8.7K蒸馏数据即可带来显著增益。
- 任务分类与CoR:显式区分任务类型可提升推理性能,结构化评分机制使判断更可靠。
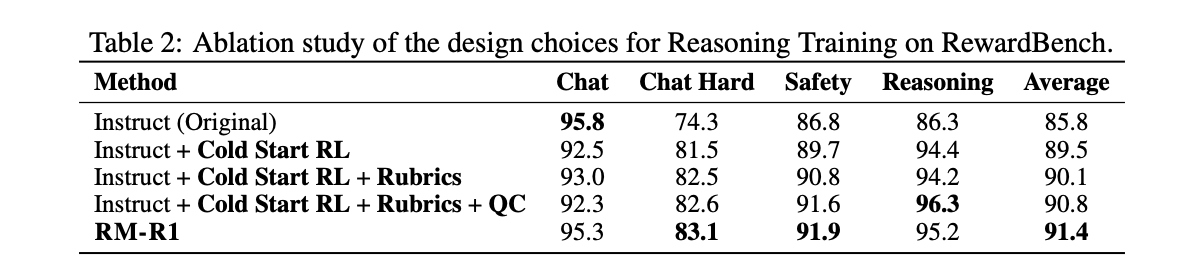
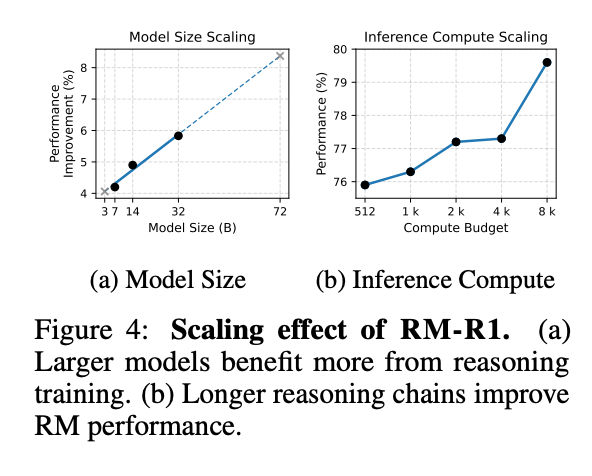
- 规模效应:模型性能随参数量(7B→32B)和推理计算量(512→8192 tokens)增长呈近线性提升,证明推理能力可通过规模扩展增强。
4.3 可解释性提升
- RM-R1生成的推理轨迹连贯且可验证,如在医疗问题中能优先关注信息准确性,而非表面特征(如响应长度),避免传统模型的浅层判断缺陷。

五、总结
本文提出将奖励建模与推理结合的全新范式,通过RM-R1模型与两阶段训练框架,实现了奖励模型在准确性与可解释性上的突破。实验表明,推理能力是提升奖励模型性能的关键,而结构化推理轨迹与任务感知评估策略是成功的核心。