学习笔记(23): 机器学习之数据预处理Pandas和转换成张量格式[1]
学习笔记(23): 机器学习之数据预处理Pandas和转换成张量格式[1]
学习机器学习,需要学习如何预处理原始数据,这里用到pandas,将原始数据转换为张量格式的数据。
1、安装pandas
pip install pandas
2、写入和读取数据
>>创建一个人工数据集,并存储在CSV(逗号分隔值)文件 ../../data/house_tiny.csv中。 以其他格式存储的数据也可以通过类似的方式进行处理。 下面我们将数据集按行写入CSV文件中。
2.1、代码
import os
import pandas as pd#向上两级目录,然后进入data目录
os.makedirs(os.path.join('..','..','data'),exist_ok=True)
data_file =os.path.join('..','..','data','house_tiny.csv')
#写入csv数据
with open(data_file,'w') as f:f.write('NumRoos,Alley,Price\n') #列名f.write('NA,Pave,127500\n') # 每行表示一个数据样本f.write('2,NA,106000\n') # 每行表示一个数据样本f.write('4,NA,178100\n')f.write('NA,NA,140000\n')#从csv读取数据
data = pd.read_csv(data_file)
print(data)>>从创建的CSV文件中加载原始数据集,我们导入pandas包并调用read_csv函数。该数据集有四行三列。其中每行描述了房间数量(“NumRooms”)、巷子类型(“Alley”)和房屋价格(“Price”)。
2.2、执行结果
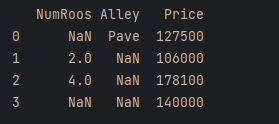
3、处理缺失值(插值法)
“NaN”项代表缺失值。 为了处理缺失的数据,典型的方法包括插值法和删除法, 其中插值法用一个替代值弥补缺失值,而删除法则直接忽略缺失值。 在这里,我们将考虑插值法。
3.1、NumRoos缺失值处理
3.1.1、代码
# 处理缺失值
inputs, outputs = data.iloc[:, 0:2], data.iloc[:, 2]
# 转换 NumRoos 列为数值类型(将 'NA' 转为 NaN)
inputs['NumRoos'] = pd.to_numeric(inputs['NumRoos'], errors='coerce')
# 用均值填充 NumRoos 列的缺失值
inputs['NumRoos'] = inputs['NumRoos'].fillna(inputs['NumRoos'].mean())
print("\n均值填充后的数据:")
print(inputs)通过位置索引iloc,我们将data分成inputs和outputs, 其中前者为data的前两列,而后者为data的最后一列。 对于inputs中缺少的数值,我们用同一列的均值替换“NaN”项。
3.1.2、执行结果
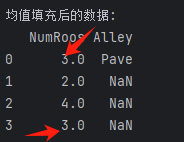
这段代码解释:
类型转换:
inputs['NumRoos'] = pd.to_numeric(inputs['NumRoos'], errors='coerce')
将 NumRoos 列从 object 类型转为数值类型
errors='coerce' 会把无法转换的 'NA' 转为 NaN
均值填充:
inputs['NumRoos'] = inputs['NumRoos'].fillna(inputs['NumRoos'].mean())
此时 NumRoos 是数值类型,mean() 能正确计算均值(3.0)
3.2、Alley字段缺失值处理
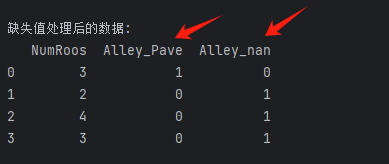
对于inputs中的类别值或离散值,我们将“NaN”视为一个类别。 由于“巷子类型”(“Alley”)列只接受两种类型的类别值“Pave”和“NaN”, pandas可以自动将此列转换为两列“Alley_Pave”和“Alley_nan”。 巷子类型为“Pave”的行会将“Alley_Pave”的值设置为1,“Alley_nan”的值设置为0。 缺少巷子类型的行会将“Alley_Pave”和“Alley_nan”分别设置为0和1。
inputs = pd.get_dummies(inputs, dummy_na=True)
- 自动处理分类变量
Alleydummy_na=True会为缺失值创建单独的列
3.2.1、代码
# 对Alley变量进行缺失值处理
inputs = pd.get_dummies(inputs, dummy_na=True)
# 检查数据类型
# print(inputs.dtypes)
# 将所有布尔列转换为整数类型(True → 1, False → 0)
inputs = inputs.astype(int)
print("\n缺失值处理后的数据:")
print(inputs)3.2.2、执行结果
这样的数据就可以直接用于机器学习模型(如线性回归、决策树等)了。
4、转换为张量格式
现在inputs和outputs中的所有条目都是数值类型,它们可以转换为张量格式。
4.1、代码
import torch
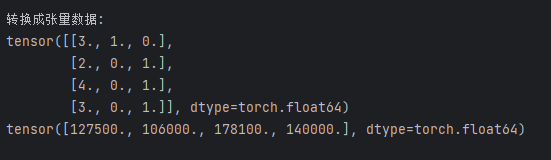
print("\n转换成张量数据:")
x = torch.tensor(inputs.to_numpy(dtype=float))
print(x)
y = torch.tensor(outputs.to_numpy(dtype=float))
print(y)4.2、执行结果
-
pandas软件包是Python中常用的数据分析工具中,pandas可以与张量兼容。 -
用
pandas处理缺失的数据时,我们可根据情况选择用插值法和删除法。