关于Dify聊天对话名称无法自动生成的原因和解决方法
现状
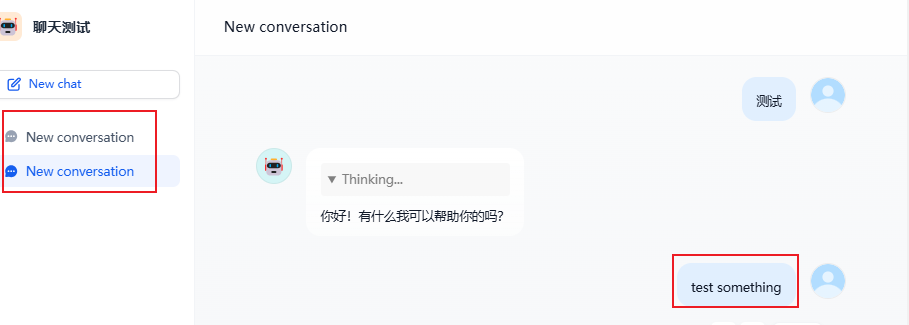
每次创建一个新对话时,聊天对话名称都是new conversation,或者明明问的是中文,聊天对话名称却是英文
原因
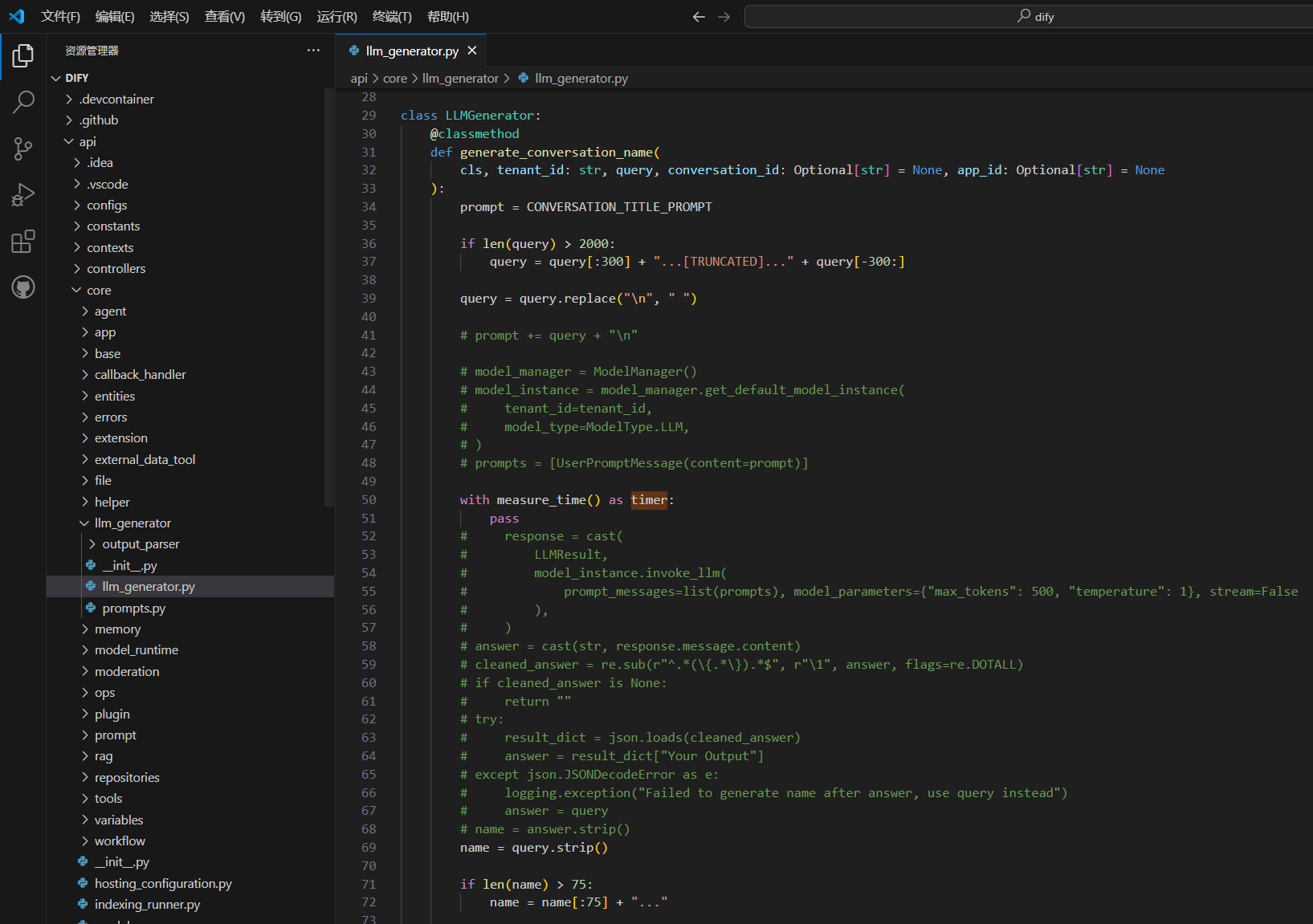
因为dify默认是调用设置的系统模型来对问题进行总结输出,但如果你的默认模型是推理模型,由于存在<think>标签,导致代码用正则匹配不到文本,所以导致每一个都是new conversation
解决方法
(1)更改系统默认模型为非推理模型就可以了。
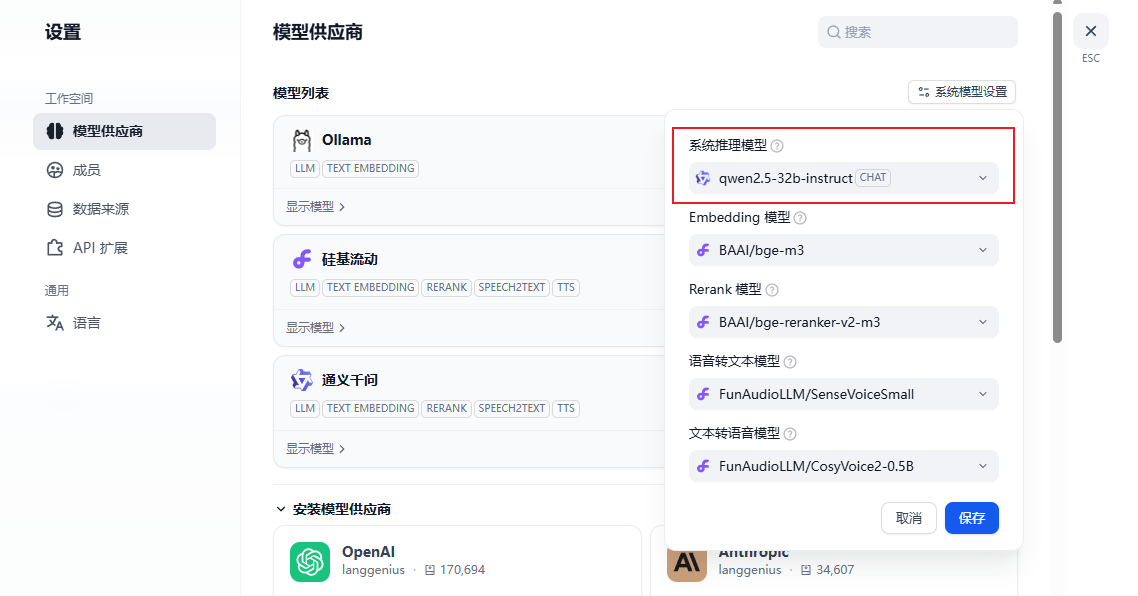
(2)如果你特别想用或者只能用推理模型作为系统模型也不是不可以,只需要在源码中修改正则匹配的逻辑就可以了
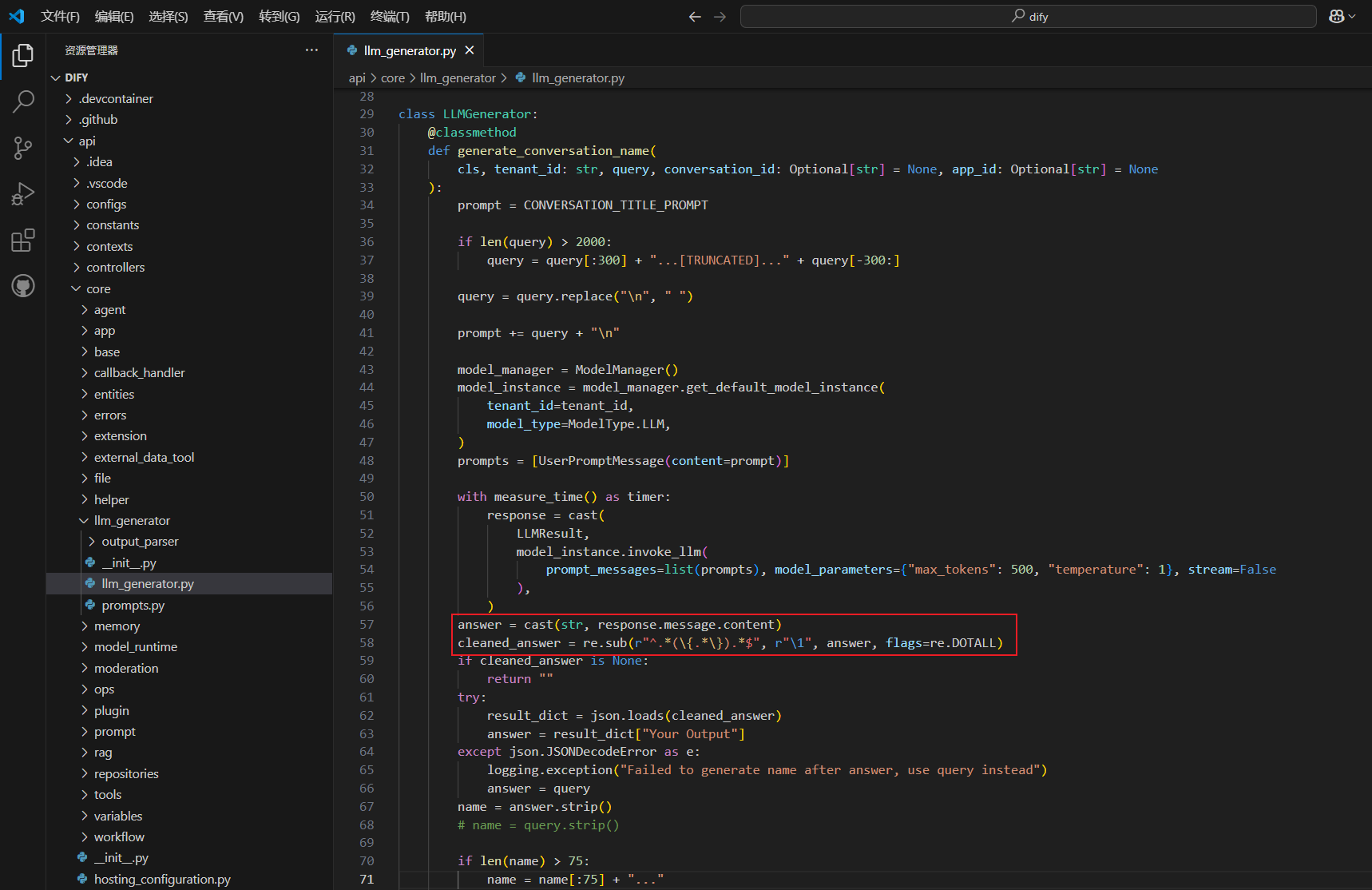
拓展
我更改为非推理模型后确实能够正常生成聊天对话名称了,但是还存在几个问题。
(1)我发现这个对话名称有时候会生成英文名称,但我提问的明明是中文。
(2)通过大模型生成的名称其实对于自己的使用来说并没有想象的方便,不如直接以第一个问题作为聊天名称来的方便。
关于第一个问题,一开始从源码入手,发现大模型对于生成对话名称也是有提示词的,并且提示词还是英文
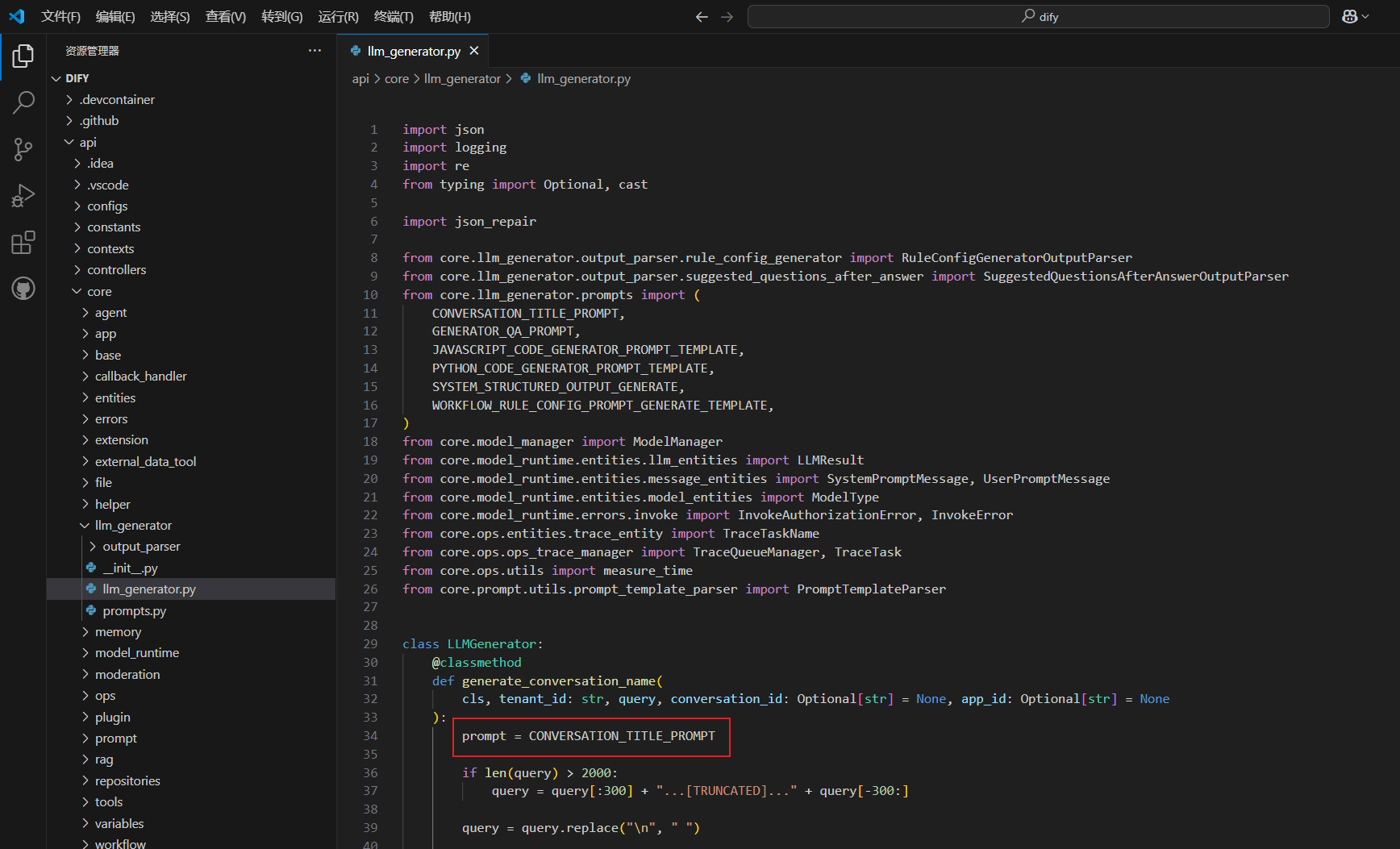
于是我对提示词进行翻译,然后对docker中的文件进行修改,但是名称生成的效果也不是很好,最后才发现是设置的系统默认模型太拉跨,导致对于提示词的理解也不够,生成的不行,建议大家能够8B及以上的非推理模型作为系统默认模型。
解决完第一个问题后能够正常生成聊天名称了,可总觉得总结后的名称看起来怪怪的,不如直接以第一个问题作为对话名称,于是我对题目生成的函数进行修改,并且也减少了对大模型资源的消耗
经过上面的步骤,你就可以自定义你想要对话名称了,是不是非常简单!