牛客小白月赛113
前言:这场的E题补的我头皮都发麻了。
A. 2025
题目大意:一个仅有‘-’‘*’组成的字符串,初始有一个sum = 1, 从左到右依次遍历字符串,遇到-就让sum--;遇到*就让sum*= 2,问sum有没有可能大于等于2025。
code:
#include <iostream>using namespace std;int main()
{string s; cin >> s;int sum = 1;for(auto ch : s){if(ch == '-') sum--;else sum *= 2;if(sum >= 2025){cout << "YES" << endl;return 0;}}cout << "NO" << endl;return 0;
}B. 好字符串
题目大于:一个仅有小写字母组成的字符串s,下标从1开始,执行下面列至多操作一次:选择一个位置删除该位置的字符,剩下的字符按照原来的顺序从后依次拼接,问是否可以使得任意两个相邻的位置的字符不同。
【解题】:我们发现需要删除的是两个相邻字符相同的情况,我们可以从从前往后遍历统计相邻字符数就行。
code:
#include <iostream>
using namespace std;
int main()
{int n; cin >> n;string s; cin >> s;int cnt = 0;for(int i = 1; i < s.size(); i++){if(s[i] == s[i - 1]) cnt++;}if(cnt <= 1) cout << "YES" << endl;else cout << "NO" << endl;return 0;
}C. 连续数组
题目大意:
给你 q 个数组,其中第 i 个数组中的元素个数为 ki。现在我们需要将这些数组全部组合成一个新的数组 A,但要保证每个数在原来的数组中的相对顺序不变,如果可以通过一些组合方式,使得新数组 A 为连续数组,则我们认为其为好数组。问是否可以组成连续数组。
【解题】:不难发现:要组成连续数组且在原数组位置不变前提需要每个数组的元素必须升序;
并且不能有相同的元素,换句话说最小值到最小值加元素个数减1的数都要出现;剩下的情况都是合法的。
code:
#include <iostream>
#include <unordered_map>
#include <vector>
using namespace std;
const int N = 1e5 + 10;
int q;int main()
{cin >> q;unordered_map<int, int> mp;int mina = 0x3f3f3f3f;int cnt = 0;while(q--){int k; cin >> k;cnt += k;int pre = 0;for(int i = 1; i <= k; i++){int x; cin >> x;if(x <= pre){cout << "NO" << endl;return 0;}mp[x]++;pre = x;mina = min(mina, x);}}for(int i = mina; i <= mina + cnt - 1; i++){if(!mp.count(i)){cout << "NO" << endl;return 0;}}cout << "YES" << endl;return 0;
}D. mex
题目大意:给一个长度为n的数组a,问执行下面操作多少次可以使得数组的元素都相同?
- 使所有a中的元素变为max(ai - mex(a), 0)。
mex(a) 指a数组中没有出现的最小非负整数。
【解题】:
- 对于初始元素全相同的情况不需要操作直接输出0就行;
- 如果数组中没有出现0就是无解;
- 除了该元素最终减到0,它与其余数的差值不变;
- 像0 1 2 3 4 这样的数组可以一次消除;
- 对于0 5 6 7 8 这样的数组可以通过5 - 0 - 1次操作变为0 1 2 3 4;
所有我们最终只需要统计非连续两数的差值减一就行的和cnt(注意如果两元素相同要跳过),最后还要操作一次把所有的数变为0,最后答案就是cnt + 1。
code:
#include <iostream>
#include <unordered_map>
#include <algorithm>
using namespace std;typedef long long LL;
const int N = 1e5 + 10;
int n;
LL a[N];
unordered_map<int, int> mp;
int main()
{cin >> n;for(int i = 1; i <= n; i++) {cin >> a[i];mp[a[i]]++;}if(mp.size() == 1) {cout << 0 << endl;return 0;}else if(!mp.count(0)){cout << -1 << endl;return 0;} else{sort(a + 1, a + 1 + n);LL cnt = 0;// a[1] = 0for(int i = 1; i <= n; i++){if(a[i] == 0 || a[i] == a[i - 1]) continue;cnt += a[i] - a[i - 1] - 1;}cout << cnt + 1 << endl;}return 0;
}
// 8
// 0 0 3 4 5 8 10 11 12 15E. 可划分数组
题目大意:一段区间的每一个元素都至少有一个除自己之外的元素与自己不互质称这样的区间是一个合法区间。给定一个数组,你需要尽可能多的划分合法区间。
【解题】:
因为划分的区间必须是连续的,我们可以对合法区间进行合并,因而想到用区间dp解决这道问题。
定义状态表示:dp[l][r]:从l,r区间内可划分最大段数。
状态转移:枚举l,r内的所有断点i,在保证区间合法的情况下合并断点左右区间:
数据范围n最大为1e3,上述做法的时间复杂度为O(n^3)。
考虑优化:对于一段l,r
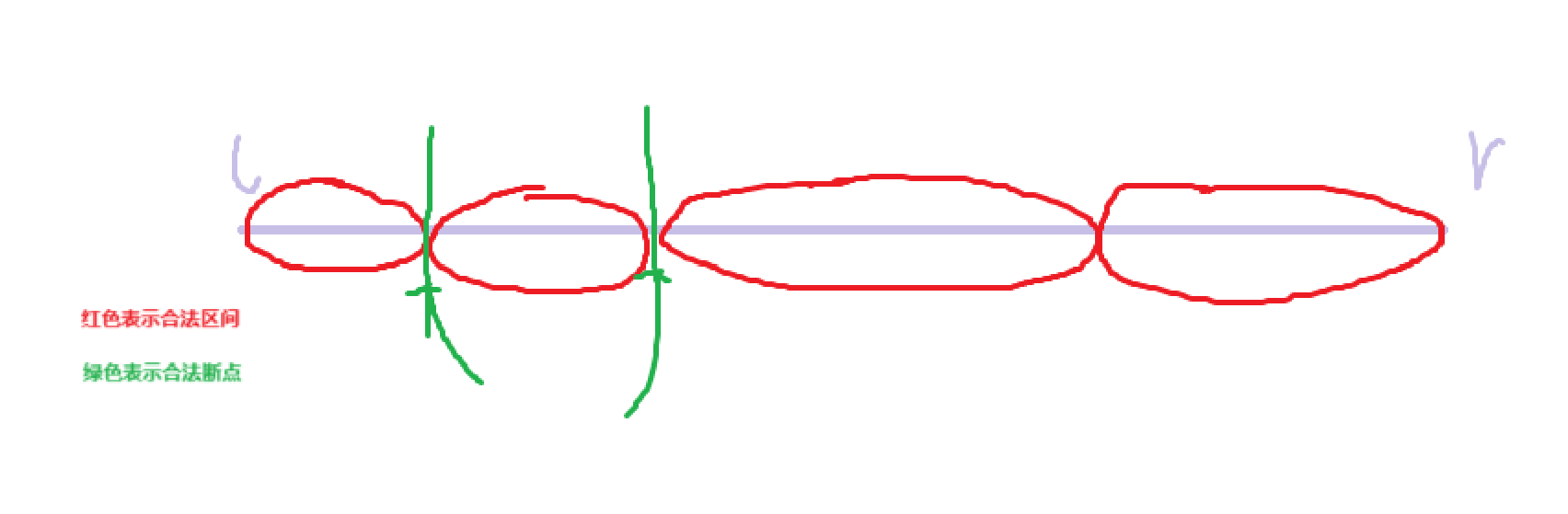
发现对于所有的合法断点其实统计的区间是一样的,存在重复计算的情况,不妨把 dp[i+1][r] 恒定设为1(0的情况不合法,>1的情况和1相同)。
原转移方程变为:
需要满足下列两个条件:
- 区间(l,i)合法;
- 区间(i + 1, r)合法,且(i + 1, r)区间仅可划分成一个合法区间。
然后我们发现状态的转移只与i有关,与 l 无关了, 因此考虑把第一维删除,让 l 恒为 1。
- 优化后的状态表示:dp[r] 表示:从1 - r区间的最大合法段数。
- 优化后的状态转移:
- (1, i)区间合法;(i + 1, r)区间合法且仅有一个区间。
- dp[n] 即为答案。
枚举r和i的时间复杂度就已经是O(n^2),因为我们只能用O(1) or O(logn) 的时间去判断两段区间是否合法。
预处理两个数组:
- pre[i]表示:第 i 个数前面第一个与它不互质数的位置;
- suf[i]表示:第 i 个数后面第一个与它不互质数的位置。预处理的时间复杂度为O(n^2)。
合法区间需要满足:
根据上述数组判断合法区间的条件转化为:
根据析取的性质我们进一步优化:
根据>=的数学性质进一步优化:
因此对两端区间合法行的判断我们采取下面方法:
- 预处理维护(1,i)的合法性。
- 从后往前枚举i,维护minp(pre[i]的最小值)从而判断(i + 1,r)的合法性。
这样我们就成功把判断区间所有元素是否满足存在一个数使它俩不互质。
最后一点代码需要注意事项:
- 我们从左到右枚举 r,i 需要满足
r - 2 - 2 + 1 >= 1 ,所以 r 从 4 开始枚举;
总体的时间复杂度为:O(n^2 logn)
code:
#include <iostream>
#include <vector>
#include <unordered_map>
#include <cstring>
#include <cmath>
using namespace std;
typedef long long LL;
typedef pair<int, int> PII;
#define endl '\n'
const int N = 2e3 + 10;
const int INF = 0x3f3f3f3f;
int a[N];
int n;
int dp[N];
int suf[N], pre[N];
int gcd(int a, int b)
{return b == 0 ? a : gcd(b, a % b);
}void solve()
{cin >> n;for(int i = 1; i <= n; i++) cin >> a[i];// 预处理 pre suf数组for(int i = 1; i <= n; i++){for(int j = i - 1; j >= 1; j--){if(gcd(a[i], a[j]) != 1) {pre[i] = j;break;}}suf[i] = n + 1;for(int j = i + 1; j <= n; j++){if(gcd(a[i], a[j]) != 1) {suf[i] = j;break;}}}// 预处理(1,i)区间的合法性for(int i = 2; i <= n; i++){dp[i] = 1;for(int j = 1; j <= i; j++){if(!(pre[j] >= 1 || suf[j] <= i)){dp[i] = 0;break;}}}// 判断(i + 1, r)区间的合法性 + 状态转移for(int r = 4; r <= n; r++){int minp = suf[r] > r ? pre[r] : INF; for(int i = r - 1 - 1; i >= 2; i--){if(suf[i + 1] > r) minp = min(minp, pre[i + 1]);if(minp >= i + 1 && dp[i] != 0) dp[r] = max(dp[r], dp[i] + 1);}}cout << (dp[n] == 0 ? -1 : dp[n]) << endl;
}int main()
{ios::sync_with_stdio(0), cin.tie(0), cout.tie(0);int T = 1; // cin >> T;while(T--){solve();}return 0;
}
累了F后面补,敬请期待QAQ。