基于protobuf + iceoryx实现共享内存上的零拷贝
1 true zero copy的简单理解
天选打工人们应该都点过外卖,外卖的流程大概是这个样子:
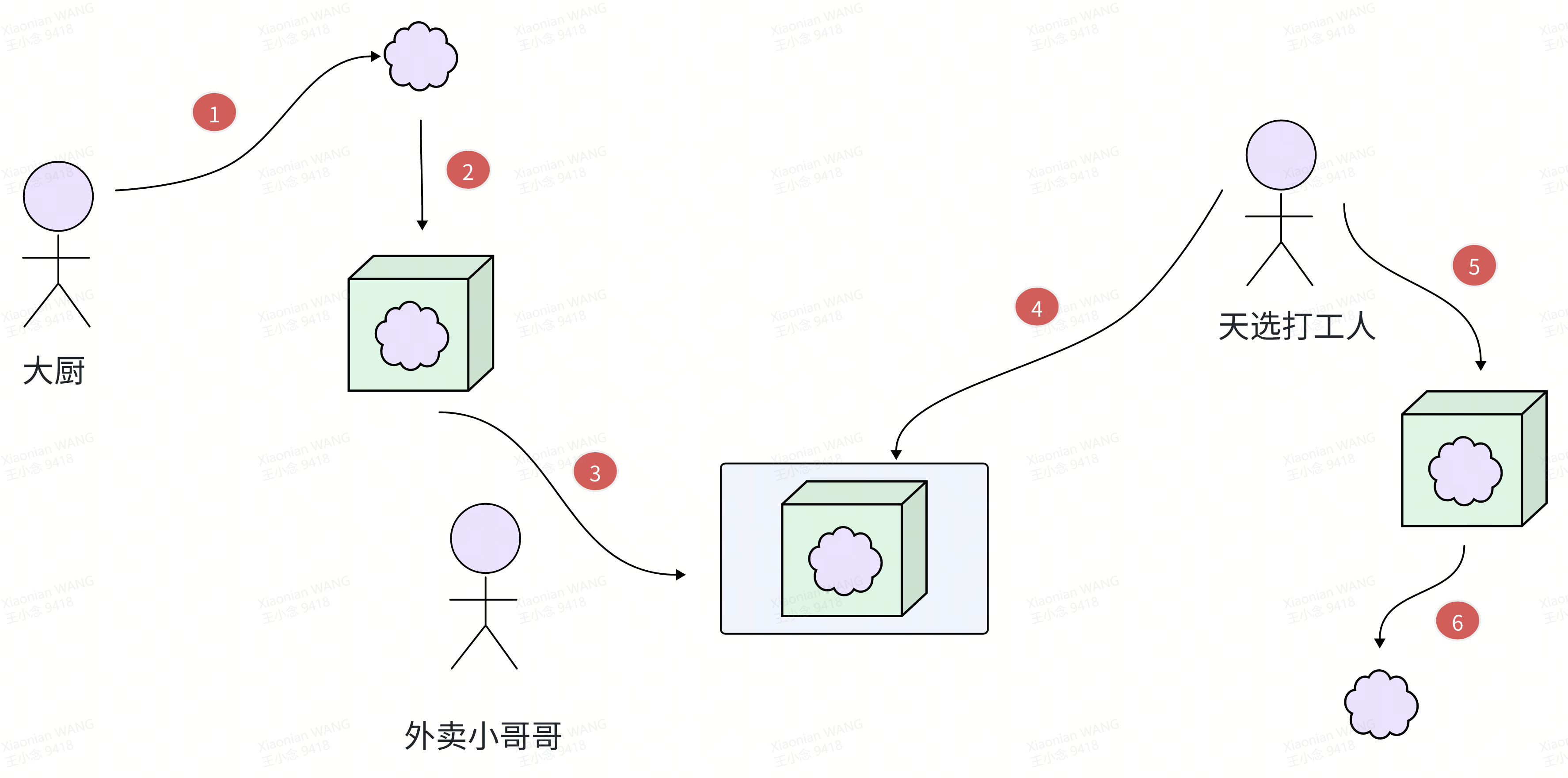
- 大厨接到订单后一顿大火猛炒,美味佳肴瞬间完成
- 餐厅服务员小姐姐将美味佳肴装进外卖袋,等待外卖小哥哥的光临
- 外卖小哥哥找到外卖袋,骑着电瓶车疾驰到外卖柜将外卖袋放进外卖箱
- 天选打工人接到外卖小哥哥的电话,起身从工位走到外卖柜找到外卖箱取走外卖袋
- 天选打工人解开外卖袋拿出美味佳肴,有时候外卖袋还打的死结,打开它还要费一番周折
- 天选打工人开始干饭
以上是天选打工人的干饭流程,富豪们自然有一套自己的打法:
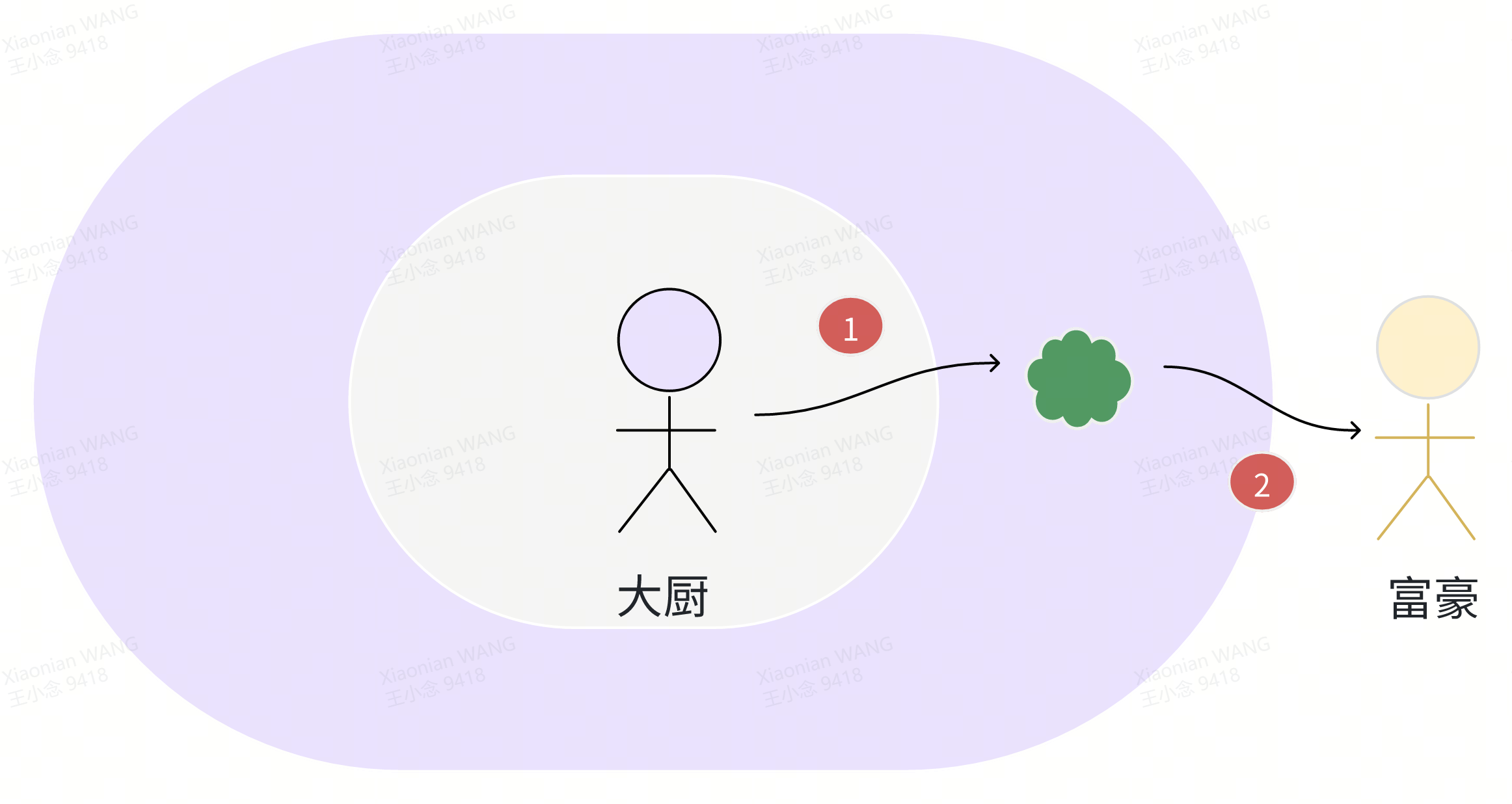
富豪将大厨直接接到自己的大house,因为今天的晚餐预定的菜单是铁板烧,所以制作铁板烧的厨具也一并被接到了大house。大厨的铁板烧厨具很神奇,既可以当餐具也可以当厨具(虽然有些荒诞,but,生活也许本该如此)。接下来,富豪要开始自己的用餐流程了:
- 大厨在自己的厨具上烹饪完成铁板烧,告诉富豪可以用餐了
- 富豪收到通知,开始使用餐具(即大厨的厨具)用餐
天选打工人的干饭过程相比富豪的用餐,多了很多流程。大厨制作好美味佳肴,服务员小姐姐必须将美味佳肴打包,外卖小哥哥必须将打包后的美味佳肴送到外卖箱,天选打工人必须到外卖箱将美味佳肴搬运到自己的工位,到了工位上还必须可能需要费点周折打开外卖袋才能最终和自己的美味佳肴邂逅。富豪因为比较壕富,有了更优雅的解决方案。
零拷贝的原理可以和富豪的用餐过程类比:
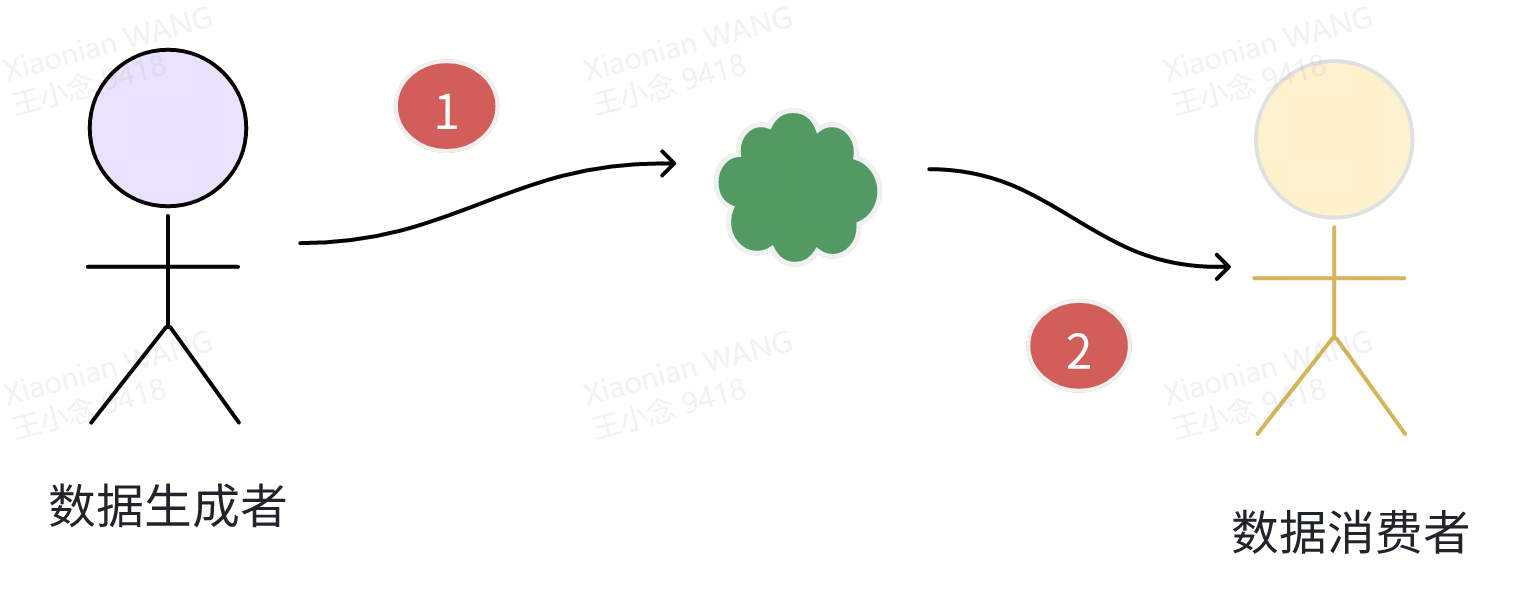
数据生产者和数据消费者约定一个地址,生产者直接在该地址上生产数据。数据生产完成后通知数据消费者,消费者直接在约定的地址之上消费数据。生产者不需要在别的地方生产完数据后再将数据打包压缩加密,然后将加密数据包搬运到约定地址。消费者也不需要将数据从约定地址搬运到另外的地址,解密解压缩然后消费。
2 为什么要使用protobuf来实现零拷贝
百度作为曾经自动驾驶的黄埔军校向自动驾驶领域输送了大批高质量的人才,其最早开发的cyberRT作为自动驾驶的通信中间件被很多企业采用。cyberRT使用谷歌的protobuf作为数据结构描述语言。protobuf在网络传输上有比较大的优势:
- 二进制编码:采用紧凑的二进制形式,相比JSON/XML减少30%-80%的数据体积,显著降低网络负载
- 编解码速度:序列化/反序列化速度相比JSON快5-100倍,尤其适合高并发或延迟敏感场景
- 无冗余字段:以字段标签替代字段名,避免传输键名,进一步压缩数据
cyberRT采用protobuf作为数据结构描述语言有其实际的业务场景:
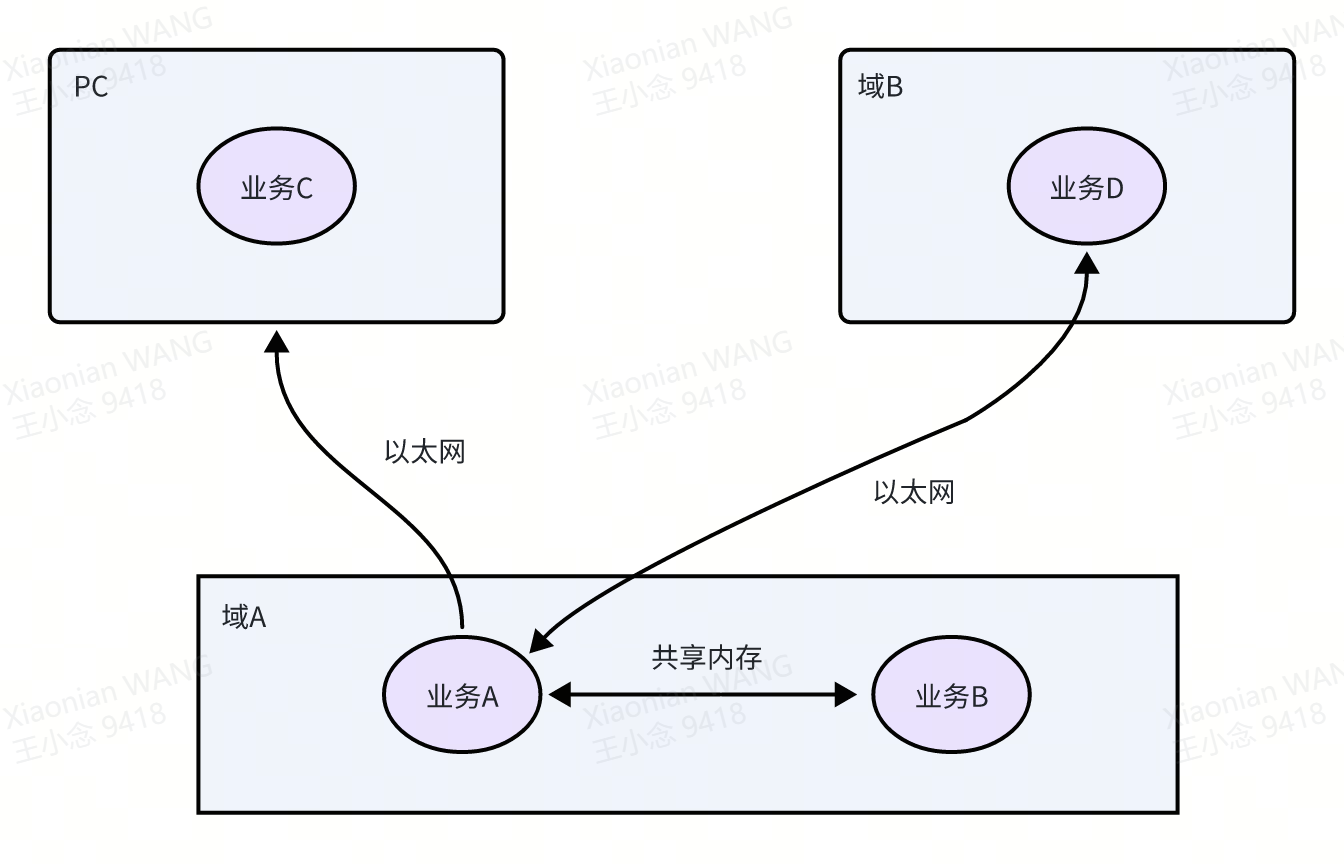
如上图所示。域A中的自动驾驶业务A不仅需要和同一个域内的业务B通过共享内存交换数据,还需要和域B中的业务D通过以太网相互通信。此外,PC上的业务C需要录制业务A的数据以进行数据回放,业务A和业务C也通过以太网通信。
cyberRT无论是域内共享内存还是域外以太网通信,所有的数据都需要经过序列化后再发送,对端收到数据后需首先对数据进行反序列化,然后再使用。以域内共享内存通信为例:
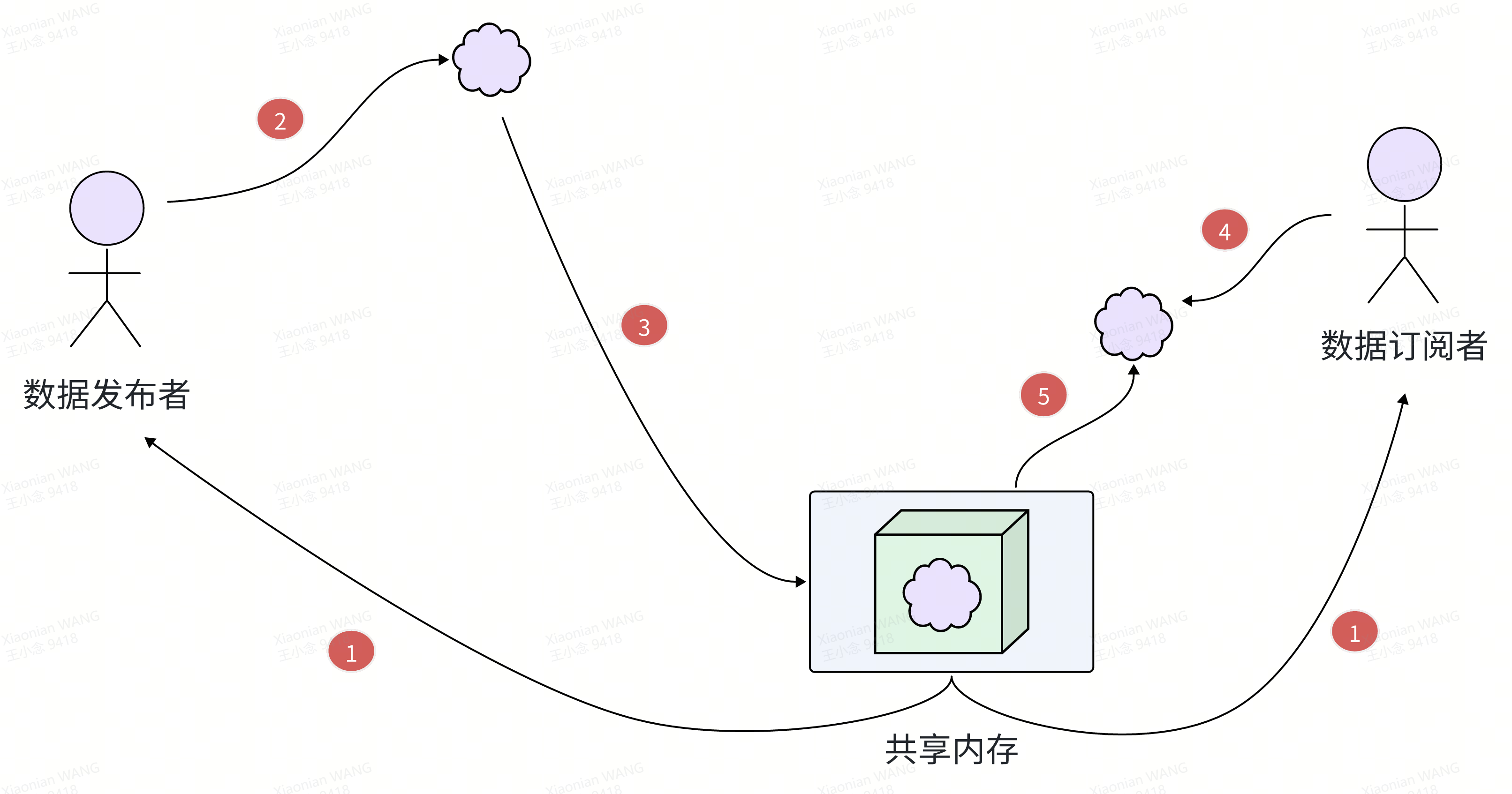
- 数据发布者和数据订阅者分别将同一段物理内存映射进各自的虚拟地址空间,该物理内存即为共享内存
- 数据发布者分配一段内存(非1中的共享内存),在该内存上构造protobuf message对象并填充数据
- 将2中的protobuf message序列化到1中建立的共享内存,通知数据订阅者
- 数据订阅者收到数据更新通知后,也分配一段内存(非1中的共享内存)
- 数据订阅者将共享内存中的数据反序列化到4中分配的内存,此时才真正开始使用数据发布者发布的数据
从以上过程可以看出,整个通信过程不仅有数据的序列化和反序列化操作,还多了两次拷贝(发布者将数据从内存序列化到共享内存、订阅者将数据从共享内存反序列化到新的内存),不仅增大了消息的传输延时,序列化和反序列化操作还会增加cpu的占用率。所以,cyberRT的共享内存通信不是零拷贝,在传输效率层面还有优化的空间。
3 冰羚iceoryx为了实现真正的零拷贝做了哪些事情
冰羚做到了真正的共享内存零拷贝通信。在探讨冰羚的零拷贝实现机制之前,我们先考虑一个问题,如果一个类含有虚函数,可以实现该类的对象直接通过共享内存在两个进程共享吗?
假设有一个类Point,声明如下:
class Point {
public:Point(float x = 0.0, float y = 0.0): _x(x), _y(y) { }virtual float z();protected:float _x, _y;
};因为存在虚函数,所以该类拥有一个虚函数表(使用objdump探索c++类成员的内存布局_objdump 虚函数表-CSDN博客),构造函数可能被编译器扩展如下:
Point* Point::Point(Point *this, float x, float y): _x(x), _y(y)
{// 设定object的virtual table pointer (vptr)this->__vptr_Point = __vtbl__Point;// 扩展member initialization listthis->_x = x;this->_y = y;return this;
}如果使用以下代码调用虚函数z():
Point *px = new Point();
px->z();可能被编译器扩充为:
px = _new(sizeof(Point));
if (px != 0)px->Point::Point();if (px != 0)(*px->__vptr_Point[2])(px);每一个对象在构造的时候,虚函数表的地址被写死了,调用虚函数的时候需要通过虚函数表找到虚函数的地址,但是这两个地址都属于发布者进程地址空间的地址,该地址在订阅者进程中可能无效。
所以,如果一个类包含虚函数,其对象不能直接通过共享内存在两个进程间安全共享。为了在共享内存中传输数据,数据结构的设计最好不要包含虚函数。
冰羚为了做到真正的零拷贝,至少做了以下软件架构设计:
1. 数据描述语言(IDL)采用C struct风格设计,具备POD(Plain Old Data)特征。POD 类型的内存布局是连续的,并且没有内部的指针或引用等复杂结构。这使得它们可以直接通过内存拷贝(如 memcpy)来复制或赋值。如下是冰羚IDL的一个例子,只有数据成员,无任何成员函数,可以通过C struct的语法访问数据成员。
struct ComplexDataType
{double x = 0.0;double y = 0.0;double z = 0.0;iox::forward_list<iox::string<10>, 5> stringForwardList;iox::list<uint64_t, 10> integerList;iox::list<iox::optional<int32_t>, 15> optionalList;iox::stack<float, 5> floatStack;iox::string<20> someString;iox::vector<double, 5> doubleVector;iox::vector<iox::variant<iox::string<10>, double>, 10> variantVector;
};2. 容器全部重写,不采用C++标准库的容器实现,因为标准库的容器实现代码不受控制,动态扩容的内存未必一定分配在指定的共享内存上(当然可以定制化内存分配策略,较复杂)。比如vector的实现:
namespace iox
{
/// @brief C++11 compatible vector implementation. We needed to do some
/// adjustments in the API since we do not use exceptions and we require
/// a data structure which can be located fully in the shared memory.
///
/// @attention Out of bounds access or accessing an empty vector can lead to a program termination!
///
template <typename T, uint64_t Capacity>
class vector final
{public:using value_type = T;using iterator = T*;using reference = T&;using const_iterator = const T*;using const_reference = const T&;using difference_type = std::ptrdiff_t;using size_type = decltype(Capacity);using index_type = size_type;/// @brief creates an empty vectorvector() noexcept = default;/// @brief creates a vector with count copies of elements with value value/// @param [in] count is the number copies which are inserted into the vector/// @param [in] value is the value which is inserted into the vectorvector(const uint64_t count, const T& value) noexcept;
};3. 不使用虚函数动态绑定,大量使用CRTP(Curiously Recurring Template Pattern)设计模式,比如:
/// @brief Represents a file. It supports various read and write functionalities
/// and can verify the existance of a file as well as remove existing files.
class File : public FileManagementInterface<File>
{public:File(const File&) noexcept = delete;File& operator=(const File&) noexcept = delete;File(File&& rhs) noexcept;File& operator=(File&& rhs) noexcept;~File() noexcept;/// @brief Returns the underlying native file handle.int get_file_handle() const noexcept;/// @brief Reads the contents of the file and writes it into the provided buffer./// @param[in] buffer pointer to the memory./// @param[in] buffer_len the storage size of the provided memory./// @returns The amount of bytes read, at most buffer_len.expected<uint64_t, FileReadError> read(uint8_t* const buffer, const uint64_t buffer_len) const noexcept;
};CRTP模式中,派生类将自己作为模板参数传递给基类。在这种模式下,基类是一个模板类,并且派生类是这个模板的实例化类型。CRTP允许在编译时实现多态行为。与传统的动态多态(通过虚函数实现)不同,CRTP实现的多态无需运行时的虚函数表查找操作。
除了使用CRTP实现静态多态,也大量使用模板参数构造继承关系,比如:
template <typename ChunkQueueDataProperties, typename LockingPolicy>
struct ChunkQueueData : public LockingPolicy
{using ThisType_t = ChunkQueueData<ChunkQueueDataProperties, LockingPolicy>;using LockGuard_t = std::lock_guard<const ThisType_t>;using ChunkQueueDataProperties_t = ChunkQueueDataProperties;ChunkQueueData(const QueueFullPolicy policy, const VariantQueueTypes queueType) noexcept;UniqueId m_uniqueId{};static constexpr uint64_t MAX_CAPACITY = ChunkQueueDataProperties_t::MAX_QUEUE_CAPACITY;VariantQueue<mepoo::ShmSafeUnmanagedMultiChunk, MAX_CAPACITY> m_queue;concurrent::Atomic<bool> m_queueHasLostChunks{false};RelativePointer<ConditionVariableData> m_conditionVariableDataPtr;optional<uint64_t> m_conditionVariableNotificationIndex;const QueueFullPolicy m_queueFullPolicy;
};
4 protobuf为什么不能实现共享内存上的零拷贝通信
在protobuf arena实现概述-CSDN博客一文的最后提出了一个问题,基于protobuf能否实现共享内存上的零拷贝?答案是不能。主要存在以下两个问题:
1. repeated字段的赋值和取值均需通过arena_or_elements_,但arena_or_elements_被赋值的地址是发布者进程地址空间的地址,在订阅者进程中可能无效,所以发布者无法通过arena_or_elements_获取repeated字段中的数值。
2. string字段的对象虽然可以在共享内存上构造,但string对象的内存分配和扩容依赖C++标准库的实现,这部分内存不一定在共享内存上分配,发布者进程无法通过共享内存获取string对象的内容。
针对问题1,为了正确得到arena_or_elements_在订阅者进程地址空间的正确位置,可以为RepeatedField增加一个数据成员:
class RepeatedField final {
private:RepeatedField* ori_this_;
};该数据成员存储Repeated对象在发布者进程地址空间中的地址:
template <typename Element>
inline RepeatedField<Element>::RepeatedField(Arena* arena): current_size_(0), total_size_(0), arena_or_elements_(arena), ori_this_(this){}
可以利用this指针在发布者进程和订阅者进程的偏移量计算得到arena_or_elements_在订阅者进程地址空间中实际的值:
Element* unsafe_elements() const {if (this != ori_this_) {int64_t offset = reinterpret_cast<uint64_t>(this) - reinterpret_cast<uint64_t>(ori_this_);return reinterpret_cast<Element*>(reinterpret_cast<uint64_t>(arena_or_elements_) + offset);}return static_cast<Element*>(arena_or_elements_);}针对第二个问题,为ArenaStringPtr增加一个数据成员用来存放共享内存上的string对象内容的起始地址:
struct PROTOBUF_EXPORT ArenaStringPtr {
private:char* raw_string_;
}在设置string值的时候利用Arena在共享内存上分配一段内存,将string的内存单独再拷贝一次至该地址:
void ArenaStringPtr::Set(const std::string* default_value, std::string&& value,::google::protobuf::Arena* arena) {if (IsDefault(default_value)) {if (arena == nullptr) {tagged_ptr_.Set(new std::string(std::move(value)));} else {//tagged_ptr_.Set(Arena::Create<std::string>(arena, std::move(value)));tagged_ptr_.SetTagged(Arena::Create<std::string>(arena, value));raw_string_ = Arena::CreateArray<char>(arena, value.size()+1);std::memcpy(raw_string_, value.c_str(), value.size());raw_string_[value.size()] = '\0';}} else if (IsDonatedString()) {std::string* current = tagged_ptr_.Get();auto* s = new (current) std::string(std::move(value));arena->OwnDestructor(s);tagged_ptr_.Set(s);} else /* !IsDonatedString() */ {*UnsafeMutablePointer() = std::move(value);}
}发布者进程在获取string内容的时候同样利用ArenaStringPtr的ori_this_字段计算raw_string_在其地址空间的准确地址:
struct PROTOBUF_EXPORT ArenaStringPtr {ArenaStringPtr() : raw_string_(nullptr), ori_this_(this), data_(nullptr) {}private:ArenaStringPtr* ori_this_;
{;PROTOBUF_NDEBUG_INLINE const std::string GetChar() const {// Unconditionally mask away the tag.if(tagged_ptr_.IsTagged()) {int64_t offset = reinterpret_cast<uint64_t>(this) - reinterpret_cast<uint64_t>(ori_this_);return reinterpret_cast<char*>((char*)raw_string_ + offset);} return *tagged_ptr_.Get();}当然需要更改protoc的接口生成代码:
// cpp_string_field.ccformat("inline std::string* $classname$::mutable_$name$() {\n"" std::string* _s = _internal_mutable_$name$();\n""$annotate_mutable$"" // @@protoc_insertion_point(field_mutable:$full_name$)\n"" return _s;\n""}\n""inline const std::string $classname$::_internal_$name$() const {\n"" return $name$_.GetChar();\n""}\n""inline void $classname$::_internal_set_$name$(const std::string& ""value) {\n"" $set_hasbit$\n");5 改造冰羚代码
冰羚的IDL虽然支持自定义实现的容器类,但要求容器的大小事先确定,因为需要根据固定的大小去共享内存上寻找满足大小需求的chunk。protobuf的repeated字段支持数据的动态添加,可能涉及到内存的动态扩容,所以一个protobuf message数据填充的时候可能需要不止一次向Roudi进程申请多个chunk。一个protobuf message可能对应多个chunk,而不像冰羚的message与chunk是一对一的关系。
基于以上结束,数据传输队列存储的不再是ShmSafeUnmanagedChunk(读一读冰羚代码(9)publisher数据发布之寻找共享内存上的可用空间-CSDN博客),而是ShmSafeUnmanagedMultiChunk:
class ShmSafeUnmanagedMultiChunk
{public:ShmSafeUnmanagedMultiChunk() noexcept = default;ShmSafeUnmanagedMultiChunk(ChunkManagementManagement* chunkManagementManagement) noexcept;/// @brief takes a SharedMultiChunk without decrementing the chunk reference counterShmSafeUnmanagedMultiChunk(SharedMultiChunk chunk) noexcept;/// @brief Creates a SharedChunk without incrementing the chunk reference counter and invalidates itselfSharedMultiChunk releaseToSharedChunk() noexcept;/// @brief Creates a SharedMultiChunk with incrementing the chunk reference counter and does not invalidate itselfSharedMultiChunk cloneToSharedChunk() noexcept;SharedChunk cloneFirstToSharedChunk() noexcept;SharedChunk releaseFirstToSharedChunk() noexcept;/// @brief Checks if the underlying RelativePointerData to the chunk is logically a nullptr/// @return true if logically a nullptr otherwise falsebool isLogicalNullptr() const noexcept;/// @brief Access to the ChunkHeader of the underlying chunk/// @return the pointer to the ChunkHeader of the underlying chunk or nullptr if isLogicalNullptr would return trueChunkHeader* getChunkHeader() noexcept;std::vector<ChunkHeader*> getChunkHeaders() noexcept;/// @brief const access to the ChunkHeader of the underlying chunk/// @return the const pointer to the ChunkHeader of the underlying chunk or nullptr if isLogicalNullptr would return/// trueconst ChunkHeader* getChunkHeader() const noexcept;ChunkManagementManagement* getChunkManagementManagement() noexcept;/// @brief Checks if the underlying RelativePointerData to the chunk is neither logically a nullptr nor that the/// chunk has other owner/// @return true if neither logically a nullptr nor other owner chunk owners present, otherwise falsebool isNotLogicalNullptrAndHasNoOtherOwners() const noexcept;bool addChunkManagement(const not_null<ChunkManagement*> chunkManagement) noexcept;private:RelativePointerData m_chunkManagementManagement;
};
唯一的数据成员存储的是ChunkManagementManagement的id和offset,而不是之前的ChunkManagement:
struct ChunkManagementManagement
{using base_t = ChunkManagement;using referenceCounterBase_t = uint64_t;using element_t = iox::RelativePointer<base_t>;using referenceCounter_t = concurrent::Atomic<referenceCounterBase_t>;using chunkManagementContainer_t = FixedPositionContainer<element_t, MAX_CHUNK_NUMBER_IN_ONE_REQ>;ChunkManagementManagement(const not_null<MemPool*> chunkManagementPool) noexcept;referenceCounter_t m_referenceCounter{1U};chunkManagementContainer_t m_chunkManagements;iox::RelativePointer<MemPool> m_chunkManagementPool;bool addChunkManagement(const not_null<ChunkManagement*> chunkManagement) noexcept;
};ChunkManagementManagement使用FixedPositionContainer管理多个ChunkManagement,可以利用ChunkManagementManagement一次性释放多个chunk。跟ChunkManagement一样,ChunkManagementManagement数据结构需要在共享内存的初始化时分配空间(读一读冰羚代码(4)Roudi共享内存的建立过程-CSDN博客):
class MemoryManager
{
private:vector<MemPool, 1> m_chunkManagementManagementPool;
};void MemoryManager::generateChunkManagementPool(BumpAllocator& managementAllocator) noexcept
{m_denyAddMemPool = true;uint64_t chunkSize = sizeof(ChunkManagement);m_chunkManagementPool.emplace_back(chunkSize, m_totalNumberOfChunks, managementAllocator, managementAllocator);chunkSize = sizeof(ChunkManagementManagement);m_chunkManagementManagementPool.emplace_back(chunkSize, m_totalNumberOfChunks, managementAllocator, managementAllocator);
}新的管理区共享内存布局如下:

6 demo code
iox::popo::Publisher<tutorial::Person>* get_publisher_singleton_instance() {static iox::popo::Publisher<tutorial::Person>* pPub = nullptr;if (pPub == nullptr) {static iox::popo::PublisherOptions publisherOptions;publisherOptions.historyCapacity = 10U;static iox::popo::Publisher<tutorial::Person> publisher({"ZeroCopy", "Protobuf", "Demo"}, publisherOptions);pPub = &publisher;}return pPub;
}void* block_alloc(size_t size, size_t& actualSize) {auto* pPub = get_publisher_singleton_instance();if (pPub != nullptr) {return pPub->loanBlock(size, actualSize);}return nullptr;
}void block_dealloc(void* ptr, size_t size) {/*auto* pPub = get_publisher_singleton_instance();if (pPub != nullptr) {return pPub->releaseBlock(ptr);}*/
}以上代码定制化了protobuf的内存分配策略,protobuf message的构造空间利用Roudi在共享内存上申请,内存的释放由冰羚本身机制保证,为保证Arena不介入,定制化的内存释放函数实现为空(如果不定义,Arena会调用delete释放)。
利用Arena构造protobuf message对象并赋值:
void publisher()
{google::protobuf::ArenaOptions options;options.block_alloc = block_alloc;options.block_dealloc = block_dealloc;int32_t counter = 0;iox::popo::Publisher<tutorial::Person>* pPub = get_publisher_singleton_instance();//! [send]constexpr const char GREEN_RIGHT_ARROW[] = "\033[32m->\033[m ";while (!iox::hasTerminationRequested()){google::protobuf::Arena arena(options);tutorial::Person *person = google::protobuf::Arena::CreateMessage<tutorial::Person>(&arena);pPub->getSample(person).and_then([&](auto& sample) {sample->set_id(counter++);sample->add_value(counter);sample->add_value(counter + 1);sample->add_value(counter + 2);sample->set_name("zerocopy" + std::to_string(counter));consoleOutput("Sending ", GREEN_RIGHT_ARROW, sample->id());std::cout << "Sending name " << sample->name() << std::endl;;sample.publish();});std::this_thread::sleep_for(CYCLE_TIME);}//! [send]
}冰羚实际返回的内存大小一般大于protobuf message的大小,为充分利用内存空间,需要对Arena的代码做如下改造:
struct ArenaOptions {void* (*block_alloc)(size_t, size_t&);
};第二个参数存储实际得到的内存大小。原始的声明为void* (*block_alloc)(size_t)。
7 零拷贝和非零拷贝的数据延时对比(基于protobuf)
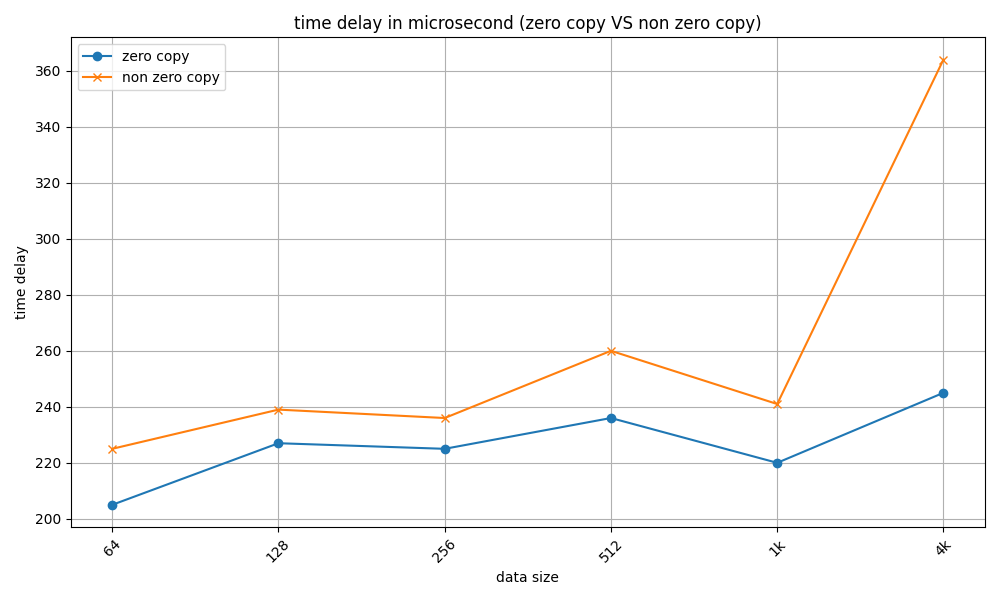
小数据量的延时对比
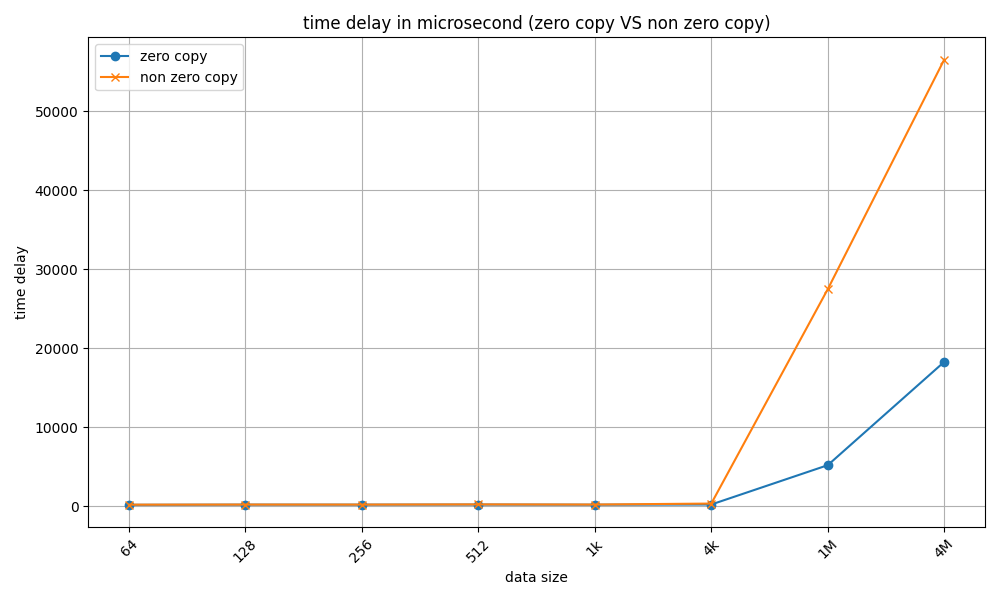
较大数据量的延时对比
可以看出,数据量较小时,零拷贝相较于非零拷贝,数据的传输速度有10%-20%的提升,随着数据量的增加,零拷贝的优势越来越明显,4M数据的延时竟然有三倍的差距!
Demo的GitHub地址:solara0616/zerocopy-protobuf