R²ec: 构建具有推理能力的大型推荐模型,显著提示推荐系统性能!!
摘要:大型推荐模型通过编码或项目生成将大型语言模型(LLMs)扩展为强大的推荐工具,而近期在LLM推理方面的突破也同步激发了在推荐领域探索推理的动机。目前的研究通常将LLMs定位为外部推理模块,以提供辅助性思考来增强传统的推荐流程。然而,这种分离式的设计存在显著的资源成本高和次优联合优化的限制。为了解决这些问题,我们提出了R²ec,这是一个具有内在推理能力的统一大型推荐模型。首先,我们重新构思了模型架构,以便在自回归过程中实现推理和推荐的交错进行。随后,我们提出了RecPO,这是一个相应的强化学习框架,能够在单一策略更新中同时优化R²ec的推理和推荐能力;RecPO引入了一种融合奖励方案,仅利用推荐标签来模拟推理能力,从而消除了对专门推理注释的依赖。在三个数据集上与各种基线模型的实验验证了R²ec的有效性,显示出在Hit@5指标上相对提升了68.67%,在NDCG@20指标上相对提升了45.21%。
本文目录
一、背景动机
二、核心贡献
三、实现方法
3.1 模型设计
架构设计
推理和推荐的交替过程
3.2 训练优化
轨迹采样
奖励和优势估计
四、实验结论
4.1 性能显著提升
4.2 推理模块有效性
4.3 优势估计方法对比
4.4 轨迹采样和组大小的影响
五、总结
一、背景动机
论文题目:R²ec: TOWARDS LARGE RECOMMENDER MODELS WITH REASONING
论文地址:https://arxiv.org/pdf/2505.16994
随着 LLMs 在推理任务中的突破,研究者开始探索如何将推理能力引入推荐系统。然而,现有的研究通常将 LLMs 作为外部推理模块,与传统的推荐流程解耦,这增加了内存占用和推理延迟。此外,推理和推荐模块只能交替更新,无法实现端到端的学习,导致性能次优。
该文章提出推理与推荐统一的大模型架构,通过双任务头和融合奖励机制解决传统解耦设计的缺陷。证明强化学习可在无人工推理标注下优化推荐模型的推理能力,为推荐系统引入可解释性和复杂决策能力。
二、核心贡献
- 提出 R²ec 模型:R²ec 是一个统一的大型推荐模型,具有内在的推理能力。该模型通过重新设计架构,将推理和推荐任务集成到一个自回归过程中,通过一个策略更新同时优化推理和推荐能力。
- RecPO训练框架:为了训练 R²ec,作者提出了 RecPO,一个基于强化学习的训练框架,它通过引入融合奖励方案(结合离散排名奖励和连续相似性奖励)来优化模型,无需依赖专门的推理注释。
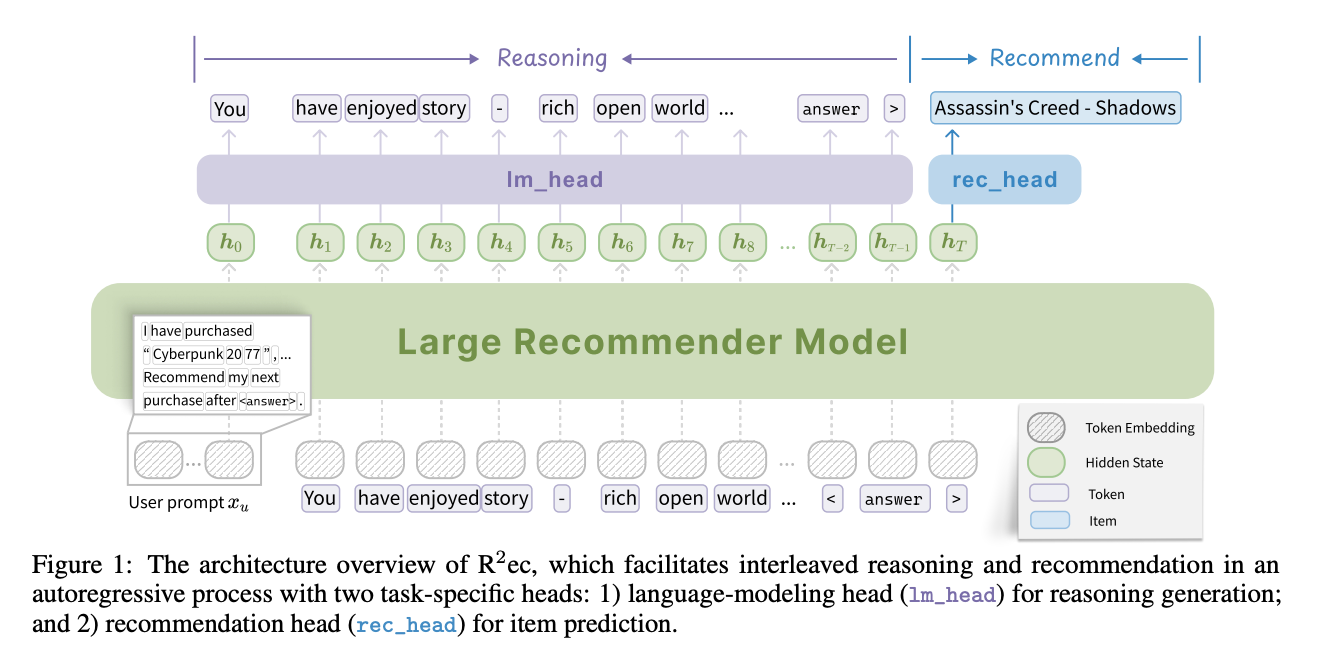
三、实现方法
3.1 模型设计
R²ec 的核心设计是将推理(reasoning)和推荐(recommendation)任务集成到一个统一的模型架构中,通过自回归过程实现推理和推荐的交替进行。
架构设计
-
基础架构:R²ec 基于一个解码器架构(decoder-only backbone),类似于常见的 Transformer 模型。
-
任务特定头(Task-specific Heads):
-
语言建模头(lm_head):负责生成推理标记(reasoning tokens)。它通过自回归的方式逐步生成推理过程中的文本内容。
-
推荐头(rec_head):用于预测推荐项目。它通过计算候选项目与生成的推理标记的相似度来生成推荐分数。
-
推理和推荐的交替过程
-
推理生成:模型首先通过语言建模头生成一系列推理标记,这些标记描述了用户可能感兴趣的内容或推荐的逻辑。
-
项目预测:在推理标记生成完成后,模型通过推荐头对候选项目进行评分,最终生成推荐列表。
3.2 训练优化
为了训练 R²ec,文章提出了 RecPO,一个基于强化学习(RL)的训练框架。RecPO 的目标是同时优化推理和推荐能力,而无需依赖专门的推理注释。具体实现如下:
轨迹采样
-
采样过程:对于每个用户,模型通过当前策略采样多条推理轨迹(reasoning trajectories)。每条轨迹包括一系列推理标记和最终推荐的项目。
-
采样策略:使用温度(temperature)和 top-K 采样来控制生成轨迹的随机性和多样性。
奖励和优势估计
-
奖励计算:为了评估生成轨迹的质量,文章设计了一个融合奖励方案,结合了离散排名奖励(Rd)和连续相似性奖励(Rc)。
-
离散排名奖励(Rd):使用 NDCG@k(Normalized Discounted Cumulative Gain)来衡量推荐项目的排名质量。
-
连续相似性奖励(Rc):计算生成的推理标记与目标项目之间的 softmax 相似度。
-
融合奖励:通过线性组合将两种奖励结合起来,其中 β 是一个权重参数,用于平衡两种奖励的贡献。
-
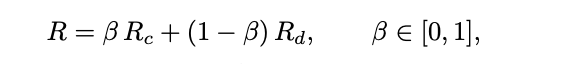
-
优势估计:使用 GRPO或 RLOO 等方法来估计每条轨迹的优势值,这些优势值用于指导模型的更新方向。
四、实验结论
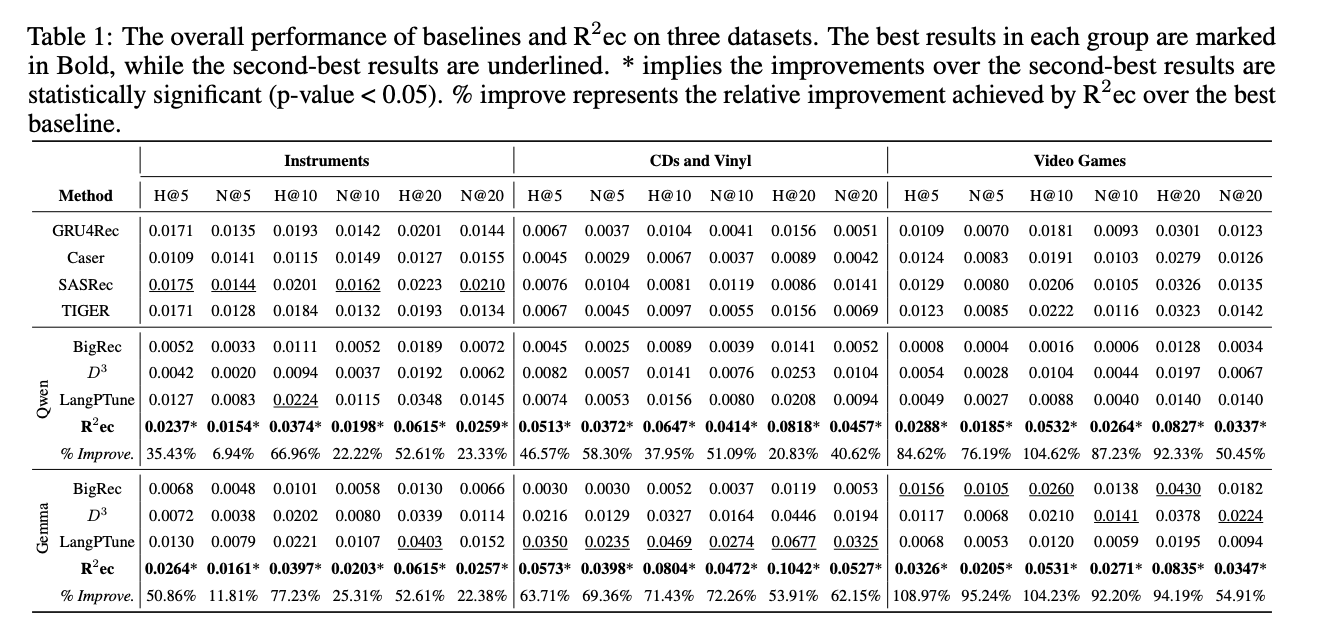
4.1 性能显著提升
R2EC 在所有实验数据集上均显著优于传统推荐系统、基于 LLM 的推荐系统和推理增强的推荐系统。具体来说,R2EC 在 Hit@5 和 NDCG@20 指标上分别实现了 68.67% 和 45.21% 的相对提升,表明其在推荐准确性和排名质量上都表现出色。
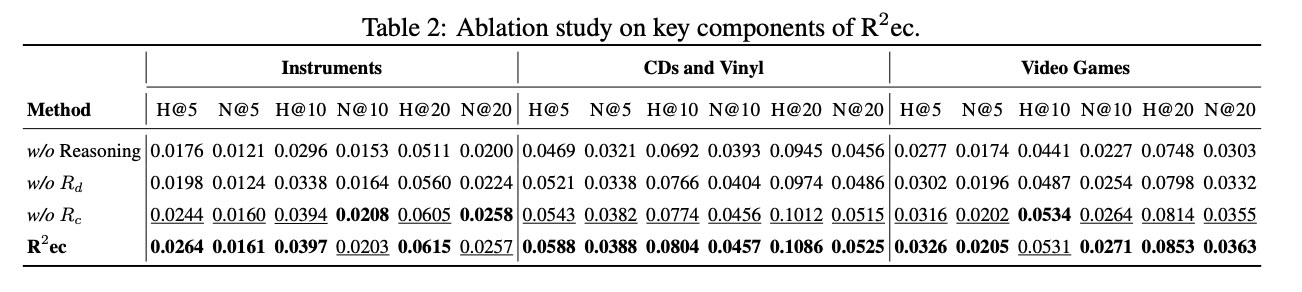
4.2 推理模块有效性
-
无推理(w/o Reasoning):移除推理模块后,模型性能显著下降,表明推理模块对推荐性能有重要贡献。R2EC 在所有指标上平均提升了约 15%。
-
无连续奖励(w/o Rc):仅使用离散排名奖励 Rd 时,模型性能优于仅使用连续相似性奖励 Rc,但融合奖励方案进一步提升了性能。
-
无离散奖励(w/o Rd):仅使用连续相似性奖励 Rc 时,模型性能下降,表明离散奖励在优化过程中更为关键。
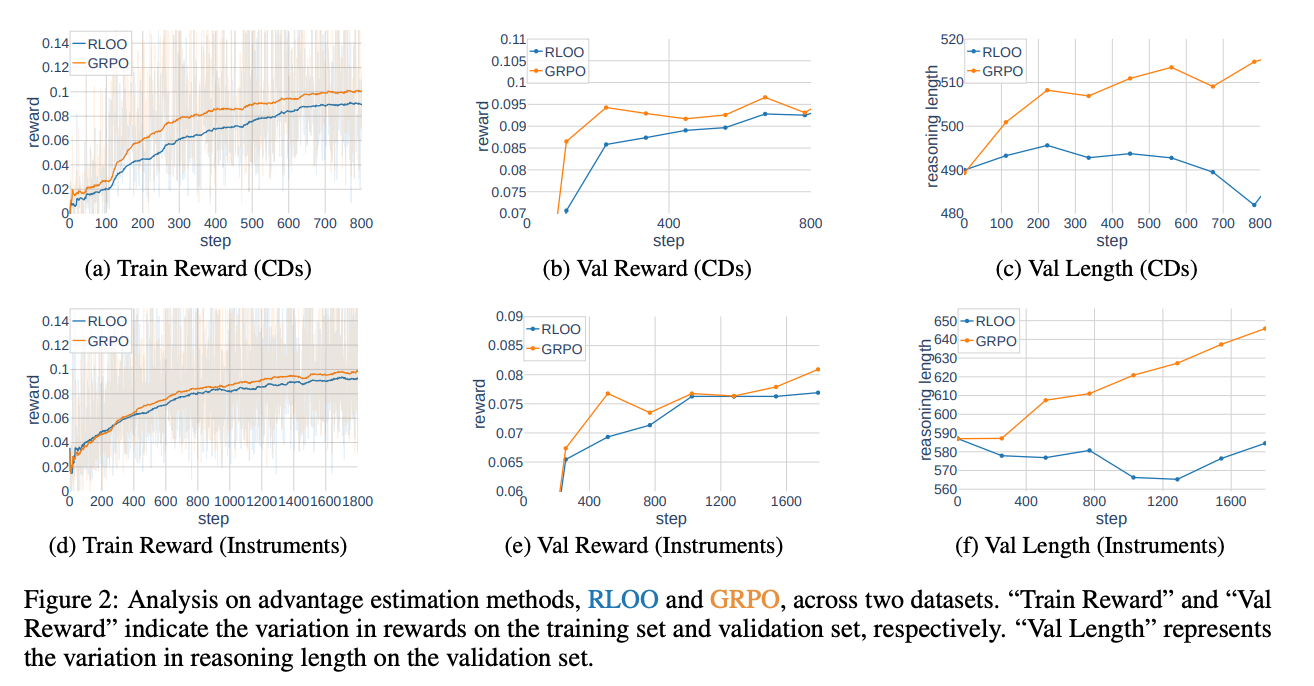
4.3 优势估计方法对比
-
训练奖励(Train Reward):两种方法在训练过程中都表现出高方差,但 GRPO 在初始阶段学习更快。
-
验证奖励(Val Reward):GRPO 在验证集上的表现优于 RLOO,表明其在早期训练中能够提供更大的梯度。
-
推理长度(Reasoning Length):GRPO 的推理长度随着训练的进行逐渐增加,而 RLOO 保持相对稳定。
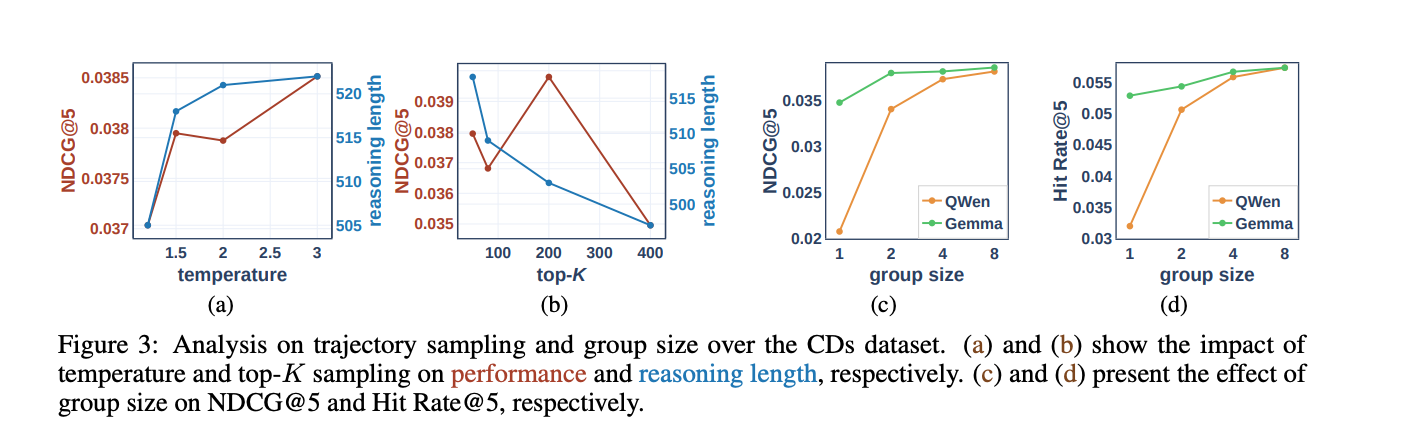
4.4 轨迹采样和组大小的影响
-
采样温度(Temperature):增加采样温度可以提高推理的多样性和推荐性能,但过高的温度会导致推理长度过长。
-
top-K 采样:增加 top-K 会缩短推理长度,但过多的候选标记会引入噪声,降低推荐性能。
-
组大小(Group Size):较大的组大小可以提高性能,但会增加训练成本。实验表明,组大小为 6 或 8 时性能提升最为显著。
五、总结
文章提出了一种新的大型推荐模型 R²ec,它通过引入推理能力显著提升了推荐性能。R²ec 的设计和训练方法为推荐系统领域带来了新的视角,特别是在如何将推理能力与推荐任务紧密结合方面。