NLP学习路线图(二十九):BERT及其变体
在自然语言处理(NLP)领域,一场静默的革命始于2017年。当谷歌研究者发表《Attention is All You Need》时,很少有人预料到其中提出的Transformer架构会彻底颠覆NLP的发展轨迹,更催生了以GPT系列为代表的语言模型风暴,重新定义了人类与机器的交互方式。
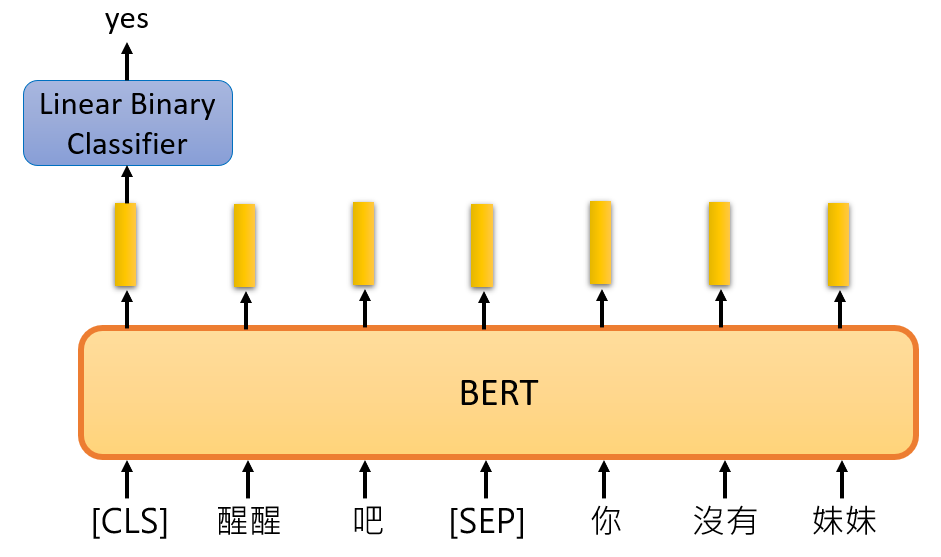
一、传统NLP的瓶颈:Transformer的诞生背景
在Transformer出现之前,NLP领域长期被两大架构主导:
-
RNN(循环神经网络):擅长序列处理但存在梯度消失问题,难以捕捉长距离依赖
-
CNN(卷积神经网络):并行效率高但难以建模全局位置关系
核心痛点:传统模型在处理长文本时效率低下,且严重依赖监督数据和人工特征工程。例如机器翻译需要复杂的编码器-解码器结构和对齐机制。
二、Transformer架构解析:注意力机制的革命
Transformer的核心创新在于完全摒弃循环与卷积,纯基于注意力机制构建。其架构包含三大核心模块:
1. 自注意力机制(Self-Attention)
# 自注意力计算简化示例
def self_attention(Q, K, V):scores = torch.matmul(Q, K.transpose(-2, -1)) / math.sqrt(d_k)weights = torch.softmax(scores, dim=-1)return torch.matmul(weights, V)-
Query-Key-Value模型:每个词生成三种向量
-
缩放点积注意力:计算词与词之间的关联强度
-
多头机制:并行多个注意力头捕捉不同子空间信息
2. 位置编码(Positional Encoding)
# 正弦位置编码公式
PE(pos,2i) = sin(pos/10000^(2i/d_model))
PE(pos,2i+1) = cos(pos/10000^(2i/d_model))-
解决无卷积/循环结构下的序列顺序问题
-
通过三角函数注入绝对位置信息
3. 层级化结构
-
编码器堆栈:6层相同结构(原论文),每层含:
-
多头自注意力子层
-
前馈神经网络子层
-
残差连接 + Layer Normalization
-
-
解码器堆栈:额外加入编码器-解码器注意力层
🔥 关键突破:Transformer在WMT 2014英德翻译任务上达到28.4 BLEU,训练速度比最优循环模型快8倍!
三、GPT系列模型:生成式预训练的进化史诗
🚀 GPT-1(2018):生成式预训练的开创者
-
核心架构:12层Transformer解码器
-
训练策略:
-
无监督预训练:BookCorpus(4.5GB文本)
-
有监督微调:针对下游任务
-
-
重大创新:证明生成式预训练 + 任务微调的有效性
🚀 GPT-2(2019):零样本学习的震撼
-
模型规模:15亿参数(最大版本)
-
数据扩展:WebText(800万网页,40GB)
-
关键发现:
- 零样本任务迁移:无需微调即可执行翻译/问答 - 规模效应:模型能力随参数量指数级增长 -
争议焦点:因“过于危险”暂缓开源最大模型
🚀 GPT-3(2020):超大规模范式
-
惊人规模:1750亿参数(96层Transformer)
-
上下文长度:2048 tokens
-
训练革命:
-
数据集:Common Crawl+WebText+Books+Wikipedia(570GB)
-
少样本学习:仅需任务描述 + 少量示例
-
-
涌现能力:
-
代码生成(GitHub Copilot底层模型)
-
复杂推理(数学证明/逻辑推导)
-
🚀 GPT-4(2023):多模态与对齐突破
-
架构升级:
-
推测参数:约1.8万亿(稀疏专家模型MoE)
-
上下文窗口:128K tokens
-
-
多模态支持:图像+文本联合输入
-
对齐技术:
-
RLHF(人类反馈强化学习)优化
-
Constitutional AI原则约束
-
-
实际应用:
-
GitHub Copilot X
-
Microsoft 365 Copilot
-
Duolingo Max
-
四、技术影响与挑战
✅ 革命性贡献:
-
预训练-微调范式:BERT、T5等模型延续此路径
-
提示工程(Prompt Engineering):新的交互范式
-
AI创作革命:写作助手、代码生成、艺术创作
⚠️ 严峻挑战:
| 挑战类型 | 具体表现 |
|---|---|
| 算力需求 | GPT-3训练成本约460万美元 |
| 偏见与毒性 | 训练数据中的社会偏见放大 |
| 事实幻觉 | 生成看似合理但不真实的内容 |
| 安全风险 | 钓鱼邮件/虚假信息生成 |
五、实战:使用Hugging Face快速体验GPT
from transformers import GPT2LMHeadModel, GPT2Tokenizertokenizer = GPT2Tokenizer.from_pretrained("gpt2")
model = GPT2LMHeadModel.from_pretrained("gpt2")input_text = "人工智能的未来"
input_ids = tokenizer.encode(input_text, return_tensors="pt")# 生成文本
output = model.generate(input_ids, max_length=100,num_return_sequences=3,temperature=0.7
)for i, sample in enumerate(output):print(f"生成结果 {i+1}: {tokenizer.decode(sample, skip_special_tokens=True)}")六、未来展望
-
效率革命:模型压缩(如Knowledge Distillation)
-
可控生成:精准控制内容属性和风格
-
具身智能:GPT+机器人技术实现物理交互
-
AI立法:全球范围内加速AI监管框架建立
著名AI研究者Yann LeCun曾断言:“Transformer是AI领域的蒸汽机”。当GPT-4已能通过律师资格考试(排名前10%),我们正在见证的不仅是技术演进,更是人类认知边界的重构。
结语:从Transformer到GPT-4,这条技术进化的核心脉络揭示了AI发展的底层逻辑——规模扩展(Scaling Laws)与架构创新的螺旋上升。当模型参数量突破百万亿,当多模态融合成为常态,我们迎来的或许不仅是更强大的工具,而是一个需要重新定义创造力、知识甚至意识的新纪元。