PostgreSQL(二十八)执行计划与单表查询成本估算
目录
(一)PG查询的执行流程
0、SQL执行五大步
1、解析器 Parser
2、分析器/分析仪 Analyzer
3、重写器 Rewriter
4、规划器 Planner & 执行器 Executor
5、涉及的重要插件:pg_hint_plan插件
(二)执行计划概述
1、执行计划
2、执行器与缓冲区之间的关系
(三)单表查询成本估算
1、优化基于成本
2、三种成本:启动、运行和总计
3、三种成本展示示例
(四)全表扫描成本估算
1、顺序扫描Sequential Scan成本计算公式
2、顺序扫描Sequential Scan成本计算案例
(五)索引扫描成本估算
1、Index Scan启动成本估算公式及案例
2、Index Scan运行成本估算公式及案例
(1)运行成本计算公式:
(2)案例:Index Scan的运行成本估算
3、Index Scan总成本估算
(六)seq_page_cost、random_page_cost参数配置
1、HDD硬盘:
2、SDD硬盘:
(一)PG查询的执行流程
0、SQL执行五大步
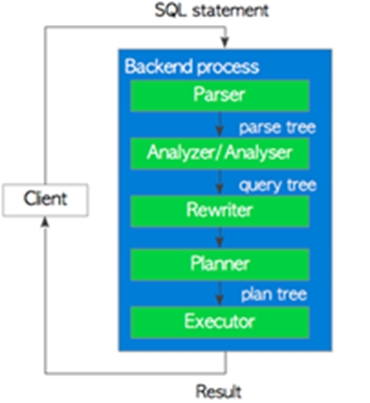
| 执行顺序 | 描述 |
| 解析器 Parser | 解析器从纯文本的sql语句生成解析树。 |
| 分析器/分析仪 Analyzer | 分析器/分析器对解析树执行语义分析并生成查询树。 |
| 重写器 Rewriter | 重写器使用存储在规则系统中的规则(如果存在此类规则)转换查询树。 |
| 规划器 Planner | 计划者从查询树生成可以最有效地执行的计划树,计划树的好坏直接影响执行的性能。 |
| 执行器 Executor | 执行器通过按计划树创建的顺序访问表和索引来执行查询。 |
1、解析器 Parser
解析器生成解析树,后续子系统可以从纯文本的sql语句中提取该树

2、分析器/分析仪 Analyzer
分析器/分析器对解析树执行语义分析并生成查询树

3、重写器 Rewriter
重写器是实现规则系统的系统,必要时根据pgrules系统目录中存储的规则转换查询树。
postgresql中的视图是通过规则系统实现的。通过"创建视图"命令定义视图时,将自动生成相应的规则并将其存储在目录中。
假设已经定义了以下视图并且相应的规则存储在pgrules系统目录中:
CREATE VIEW employees_list
AS SELECT e.id,e.name,d.name AS department
FROM employees AS e,departments AS d
WHERE e.department_id=d.id;
4、规划器 Planner & 执行器 Executor
规划器从重写器接收查询树,并生成(查询)计划树,执行者可以最有效地处理该树。
5、涉及的重要插件:pg_hint_plan插件
postgresql的内核本身不支持sql中的计划器提示。如果要在查询中使用提示,需要引用pg_hint_plan扩展插件。插件下载地址:pg_hint_plan
(二)执行计划概述
1、执行计划
explain显示sql执行计划。与其他rdbms一样,postgresql中的explain命令显示计划树本身。

cost后面跟着的“0.00”“17.88”等值都属于无量纲值,代表pg数据库整体的性能代价估算值,不代表一个具体的含义(cpu时间、IO次数等)
2、执行器与缓冲区之间的关系
执行器、缓冲区管理器、临时文件之间的关系

从上图可知,执行器是在后端进程内执行的;
缓冲区管理器是将数据库读到共享内存中,并需要时将数据传输到工作内存中;
如果需要,可能会用到临时文件。
(三)单表查询成本估算
1、优化基于成本
成本是无量纲值,这些不是绝对的绩效指标,而是比较运营相对绩效的指标。
执行者执行的所有操作都具有相应的成本函数。
2、三种成本:启动、运行和总计
(1)启动成本‘start-up cost’是在获取第一个行之前花费的成本。例如,索引扫描节点的启动成本是读取索引页面以访问目标表中的第一个元组的成本;而假如是全表扫描,则启动成本为0,因为在扫描第一行之前,不需要额外做准备动作。
(2)运行成本‘run cost'是获取所有行的成本。
(3)总成本'total cost'是启动和运行成本的成本之和(+run cost)。
3、三种成本展示示例
explain命令显示每个操作中的启动和总成本,cost后面数字的含义为:
cost=启动成本.运行成本.总成本。
例如下图中cost后方的数字代表:启动成本25.97,运行成本null,总成本26.50。

(四)全表扫描成本估算
1、顺序扫描Sequential Scan成本计算公式
顺序扫描的成本由cost_seqscan()函数估算。
在顺序扫描中,启动成本=0,运行成本由以下等式定义:
‘run cost’='cpu run cost'+'disk run cost'
=(cpu_tuple_cost + cpu_operator_cost)*N[tuple] + seq_page_cost*N[page]
#公式说明:
#run cost:总运行成本
#cpu run cost:cpu运行成本
#disk run cost:磁盘运行成本
#cpu_tuple_cost:cpu访问一行所花的成本,缺省值为0.01(系统参数)
#cpu_operator_cost:cpu操作所花的成本,缺省值为0.0025(系统参数)
#N[tuple]:总行数(SELECT reltuples FROM pg_class WHERE relname='$tab_name';)
#seq_page_cost:访问一个块需要多少成本,缺省值为1(系统参数)
#N[page]:块个数(SELECT relpages FROM pg_class WHERE relname='$tab_name';)
2、顺序扫描Sequential Scan成本计算案例
(1)准备测试表,执行SQL语句:
wqdb2=# CREATE TABLE tab2(id int,info text);
CREATE TABLEwqdb2=# INSERT INTO tab2 SELECT generate_series(1,10000),md5(random()::text);
INSERT 0 100wqdb2=# VACUUM ANALYZE tab2;
VACUUM(2)查询表的块数(page)和行数(tuple):
wqdb2=# SELECT relpages,reltuples FROM pg_class WHERE relname='tab2';relpages | reltuples
----------+-----------84 | 10000
(1 row)#查询结果表示,N[tuple]=10000,N[page]=84,带入计算公式可知:
#run cost=(cpu_tuple_cost + cpu_operator_cost)*N[tuple] + seq_page_cost*N[page]
# =(0.01+0.0025)*10000+1*84
# =209
(五)索引扫描成本估算
1、Index Scan启动成本估算公式及案例
启动成本估算公式:

H(index)指的是索引的高度,可以通过插件来查询(详情可见上一章节:27.2.4)
N[index,tuple]指的是索引的行数
N[index,page]指的是索引的页数
案例:计算以下语句通过索引访问的成本
(1)为测试表添加索引并执行测试SQL语句:
wqdb2=# create index tab2_id_idx ON tab2(id);
CREATE INDEXwqdb2=# select * from tab2 where id<100;(2)查询索引的行数和页数:N[index,tuple]、N[index,page]、H[index]
wqdb2=# SELECT relpages,reltuples FROM pg_class WHERE relname='tab2_id_idx';relpages | reltuples
----------+-----------30 | 10000
(1 row)wqdb2=# SELECT * FROM bt_metap('tab2_id_idx');magic | version | root | level | fastroot | fastlevel | last_cleanup_num_delpages | last_cleanup_num_tuples | allequalimage
--------+---------+------+-------+----------+-----------+---------------------------+-------------------------+---------------340322 | 4 | 3 | 1 | 3 | 1 | 0 | -1 | t
(1 row)启动成本计算结果:
#根据(3)N(index,tuple)=10000,H(index)=1,cpu_oprator_cost=0.0025(by default)

2、Index Scan运行成本估算公式及案例
(1)运行成本计算公式:
索引扫描的运行成本是表和索引的cpu成本和IO(输出/输入)成本之和:
run cost = ('index cpu cost' + 'table cpu cost') + ('index IO cost' + 'table IO cost')
#内容说明:
1、index cpu cost:索引cpu成本
=Selectivity*N[index,tuple]*(cpu_index_tuple_cost + cpu_operator_cost)
#Selectivity是可选性,查看方法请看:PostgreSQL(知识片):查询/计算Selectivity
#N[index,tuple]:SELECT reltuples FROM pg_class WHERE relname='tab2_id_idx';
#cpu_index_tuple_cost:系统参数,缺省值0.05,show cpu_index_tuple_cost;
#cpu_operator_cost:系统参数,缺省值0.0025,show cpu_operator_cost;
2、table cpu cost:表cpu成本:
= Selectivity*N[tuple]*cpu_tuple_cost
#N[tuple]:表的总行数
3、index IO cost:索引IO成本:
=ceil(Selectivity*N[index,page]) *random_page_cost
#N[index,page]:SELECT relpages FROM pg_class WHERE relname='tab2_id_idx';
#random_page_cost:show random_page_cost; 缺省是4
4、table IO cost:表IO成本:
=max_io_cost+indexCorrelation²*(min_io_cost-max_io_cost)
#max_io_cost:= N[page] * random_page_cost。表示最大IO成本。找到row_id指向的块id时,刚好块id包含了所有的数据块,此时为最大IO。
##N[page]:SELECT relpages FROM pg_class WHERE relname='tab2';
#min_io_cost:=1*random_page_cost+(ceil(selectivity*N[page]) -1) * seq_page_cost表示最小IO成本。找到row_id指向的块id时,刚好row_id都在一个数据块里,此时为最小IO
##seq_page_cost:show seq_page_cost;
#indexCorrelation²:索引关联度的平方。表示找到的row_id指向了一个块id还是多个块id(索引关联度的计算请看PostgreSQL(知识片):索引关联度indexCorrelation)
(2)案例:Index Scan的运行成本估算
运行成本依次计算:
1、索引CPU成本
Selectivity= [ 1 + (100-100) / (200-100) ] / 100 = 0.01
N[index,tuple]=10000
cpu_index_tuple_cost=0.005
cpu_operator_cost=0.0025
'index cpu cost'=selectivity*N[index,tuple]*(cpu_index_tuple_cost+cpu_operator_cost)
=0.01*10000*(0.005+0.0025)
=0.75
2、表CPU成本
N[tuple]=10000
cpu_tuple_cost=0.01
'table cpu cost'=selectivity*N[tuple] * cpu_tuple_cost=0.01*10000*0.01=1
3、索引IO成本
N[index,page]=30
random_page_cost=4
'index IO cost'=ceil(selectivity * N[index,page])*random_page_cost
=ceil(0.01*30)*4.0=4
4、表IO成本
N[page]=84
max_io_cost= N[page] * random_page_cost=84*4=336
min_io_cost=1*random_page_cost+(ceil(selectivity*N[page]) -1) * seq_page_cost
=1*4+(ceil(0.01*84)-1)*1=4
indexCorrelation²=1
table IO cost=max_io_cost+indexCorrelation²*(min_io_cost-max_io_cost)
=336+1*(4-336)=4
5、运行成本
run cost= ('index cpu cost' + 'table cpu cost') + ('index IO cost' + 'table IO cost')
=(0.75+1)+(4+4)
= 9.75

3、Index Scan总成本估算
5.1中算出了启动成本start-up cost=0.285
5.2中算出了运行成本run cost=9.75
可以算出总成本total cost=start-up cost+run cost=0.285+9.75=10.035
(六)seq_page_cost、random_page_cost参数配置
seq_page_cost: 访问一个块需要多少成本
random_page_cost:随机访问一个数据块的成本
1、HDD硬盘:
seq_page_cost=1.0
random_page_cost=4.0
2、SDD硬盘:
seq_page_cost=1.0
random_page_cost=1.0(降低随机访问一个块的成本,可能会影响全表扫描)