使用pandas实现合并具有共同列的两个EXCEL表
表1:
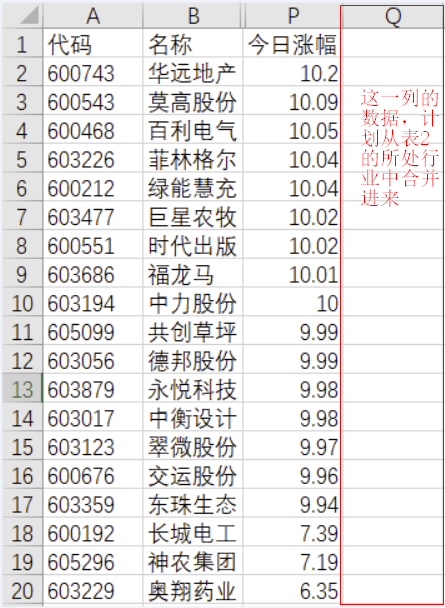
表2:
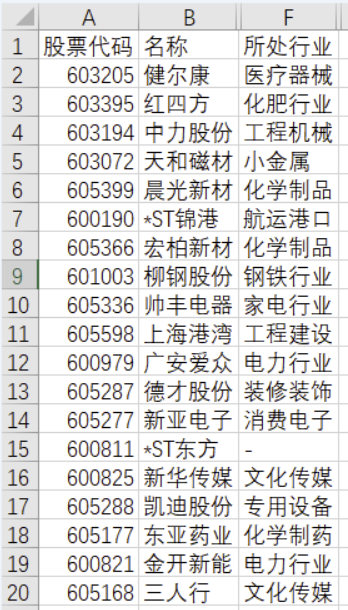
表1和表2,有共同的列“名称”,而且,表1的内容(行数)<=表2的行数。
目的,根据“名称”列的对应内容,将表2列中的“所处行业”填写到表1相应的位置。
实现代码:
import pandas as pdcsv_file_path_a = '表1.csv' # 替换为你的CSV文件路径
csv_file_path_b = '表2.csv' # 替换为你的CSV文件路径
df_a = pd.read_csv(csv_file_path_a, encoding='gbk')
df_b = pd.read_csv(csv_file_path_b, encoding='gbk')df_merged = pd.merge(df_a, df_b[['名称', '所处行业']], on='名称', how='left')
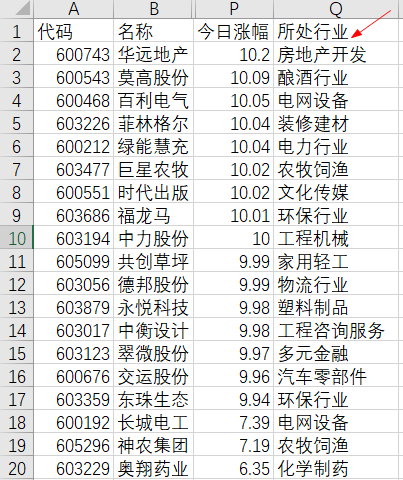
df_merged.to_csv('合并结果.csv', index=False, encoding='gbk')结果(生成一个新的叫做“合并结果.csv”),如下图:
关键代码解释:
on='名称':以“名称”列为匹配键。how='left':保留第一个表(df1)中的所有行,只添加匹配上的“所处行业”。df2[['名称', '所处行业']]:只取 df2 中需要的列,避免多余列混入。