【大模型学习】项目练习:视频文本生成器
🚀实现视频脚本生成器
视频文本生成器
📚目录
- 一、游戏设计思路
- 二、完整代码解析
- 三、扩展方向建议
- 四、想说的话
一、⛳设计思路
本视频脚本生成器采用模块化设计,主要包含三大核心模块:
- 显示模块:处理用户输入和菜单显示
- 游戏逻辑模块:雷盘状态维护、胜负判断
- 声明模块:解耦合,提高代码健壮性
说明:
编译器为Visual Studio code,Python版本为3.12,安装库为:
altair==5.5.0
annotated-types==0.7.0
anyio==4.9.0
attrs==25.3.0
blinker==1.9.0
cachetools==5.5.2
certifi==2025.4.26
charset-normalizer==3.4.2
click==8.2.1
colorama==0.4.6
distro==1.9.0
gitdb==4.0.12
GitPython==3.1.44
greenlet==3.2.2
h11==0.16.0
httpcore==1.0.9
httpx==0.28.1
idna==3.10
Jinja2==3.1.6
jiter==0.10.0
jsonpatch==1.33
jsonpointer==3.0.0
jsonschema==4.24.0
jsonschema-specifications==2025.4.1
langchain==0.3.25
langchain-core==0.3.63
langchain-deepseek==0.1.3
langchain-openai==0.3.18
langchain-text-splitters==0.3.8
langsmith==0.3.43
MarkupSafe==3.0.2
narwhals==1.41.0
numpy==2.2.6
openai==1.82.1
orjson==3.10.18
packaging==24.2
pandas==2.2.3
pillow==11.2.1
protobuf==6.31.1
pyarrow==20.0.0
pydantic==2.11.5
pydantic_core==2.33.2
pydeck==0.9.1
python-dateutil==2.9.0.post0
pytz==2025.2
PyYAML==6.0.2
referencing==0.36.2
regex==2024.11.6
requests==2.32.3
requests-toolbelt==1.0.0
rpds-py==0.25.1
six==1.17.0
smmap==5.0.2
sniffio==1.3.1
SQLAlchemy==2.0.41
streamlit==1.45.1
tenacity==9.1.2
tiktoken==0.9.0
toml==0.10.2
tornado==6.5.1
tqdm==4.67.1
typing-inspection==0.4.1
typing_extensions==4.13.2
tzdata==2025.2
urllib3==2.4.0
watchdog==6.0.0
zstandard==0.23.0
二、🎉具体流程操作
2.1 安装虚拟环境
方式一:使用anaconda安装
1.下载anaconda
2.打开
3.创建并进入虚拟环境
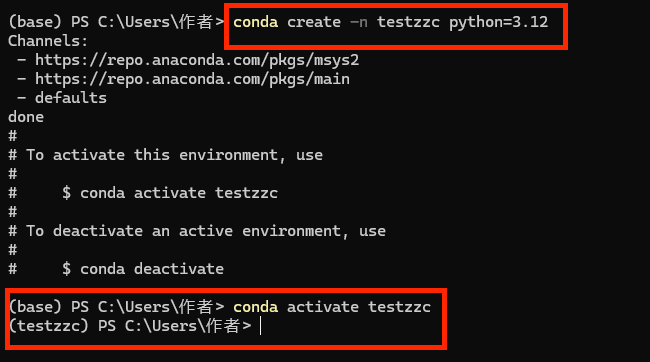
4.正常安装相应的库即可

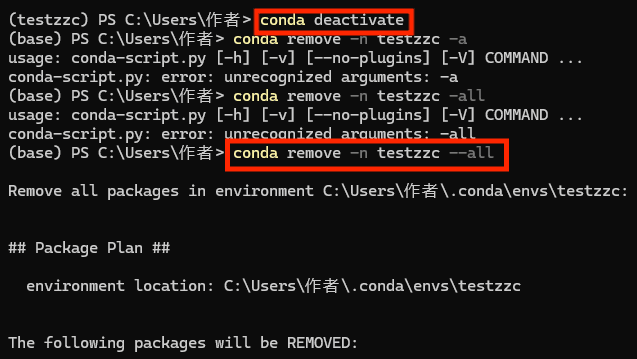
5.删除虚拟环境(可选)
先退出当前虚拟环境,再删除虚拟环境
方式二:在Visual Studio code创建虚拟环境
1.根据图操作
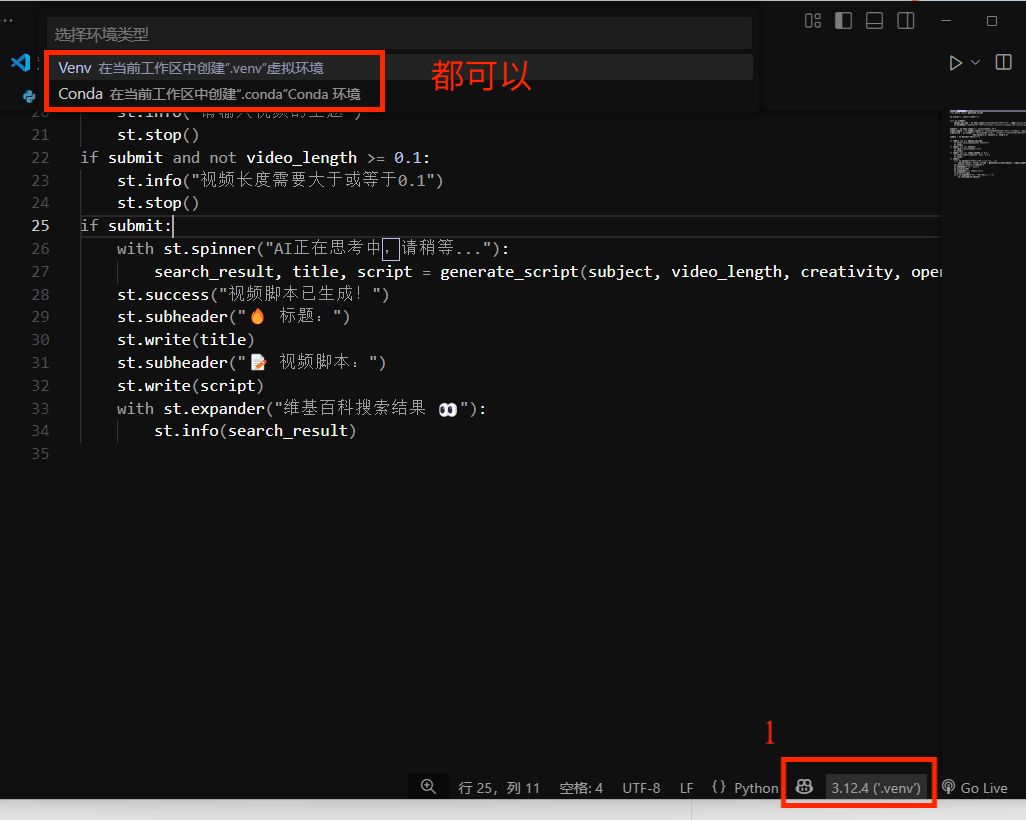
2.找到Python安装环境配置即可
2.2 安装相应的库
1.打开终端
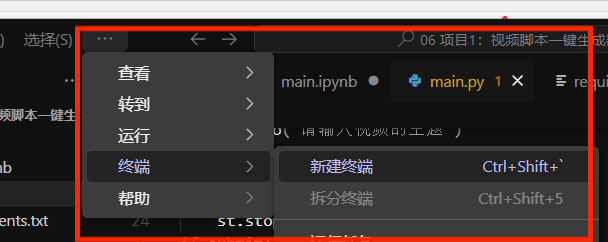
2.输入

requirements.txt自己把相应的库建出来txt文件
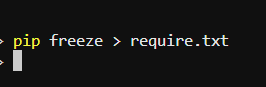
3.导入相应的库(可选)
打开终端,输入:
2.3 后端
主要实现功能:
1.标题获取:使用Langchain中的Deepseek模型进行调用获取–Langchain文档
2.内容获取:使用Langchain中的Deepseek模型进行调用获取
from langchain.prompts import ChatPromptTemplate #获取标题提示模版
from langchain_deepseek import ChatDeepSeek #deepseek-chat模型def catch_content(video_object, video_length, video_create, video_api_key): #参数分别为视频主题、视频长度、创造力和用户API密钥# 获取视频标题script_title = ChatPromptTemplate.from_messages([("human", "请为'{video_object}'这个主题的视频起一个吸引人的标题,要求有文采")])# 获取视频脚本内容script_content = ChatPromptTemplate.from_messages([("human","""你是一位小红书平台的短视频博主。根据以下标题和相关信息,写一个文本内容。视频标题:{title},视频时长:{duration}分钟,生成的文本的长度尽量遵循视频时长的要求。要求开头抓住眼球,中间提供干货内容,结尾有惊喜,文本格式也请按照【开头、中间,结尾】分隔。整体内容的表达方式要尽量轻松有趣,吸引年轻人。你需要根据标题和时长来生成内容,内容要有趣且吸引人。""")])# 创建模型获取api和创造性model = ChatDeepSeek(api_key=video_api_key, temperature=video_create, model="deepseek-reasoner")# 获取标题和文本内容title_chain = script_title | modelcontent_chain = script_content | model# 调用获取真正标题title = title_chain.invoke({"video_object": video_object}).content# 调用获取真正内容content = content_chain.invoke({"title": title, "duration": video_length}).contentreturn title, content
2.4🚀前端
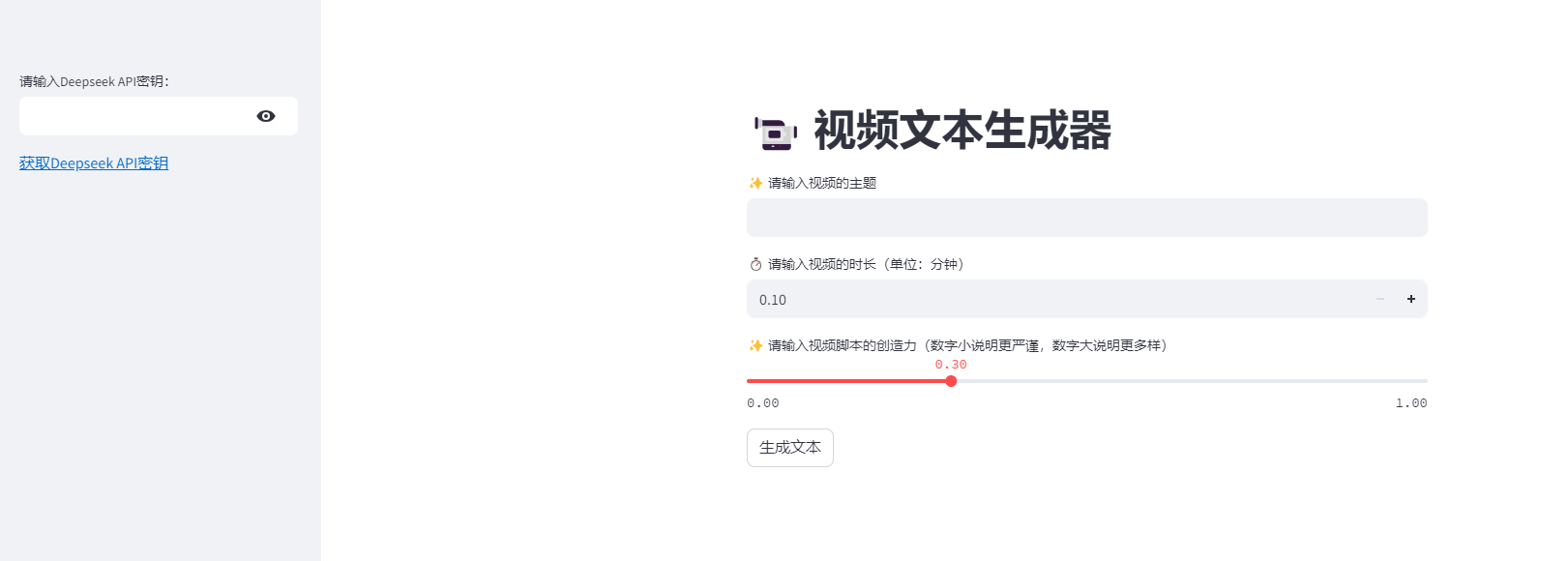
1.前端页面:使用streamlit进行页面布置
import streamlit as st #前端库
from backend import catch_contentst.title("📹 视频文本生成器")with st.sidebar: #侧边栏deepseek_api_key = st.text_input("请输入Deepseek API密钥:", type="password")st.markdown("[获取Deepseek API密钥](https://platform.deepseek.com/api_keys)")aim = st.text_input("✨ 请输入视频的主题")
video_length = st.number_input("⏱️ 请输入视频的时长(单位:分钟)", min_value=0.1, step=0.1)
creativity = st.slider("✨ 请输入视频脚本的创造力(数字小说明更严谨,数字大说明更多样)", min_value=0.0,max_value=1.0, value=0.3, step=0.1) #必须都为小数
submit = st.button("生成文本")
# 检查输入
if submit and not deepseek_api_key:st.info("请输入你的Deepseeek API密钥")st.stop() #检查API密钥是否输入,若输入则不在执行后续代码
if submit and not aim:st.info("请输入视频的主题")st.stop()
if submit and not video_length >= 0.1:st.info("视频长度需要大于或等于0.1")st.stop()
if submit:# 加载效果with st.spinner("AI正在思考中,请稍等..."): #只要以下代码未运行完,这st.spinner就会一直显示title, content = catch_content(aim, video_length, creativity, deepseek_api_key)st.success("视频文本已生成!")st.subheader("❤️🔥 标题:")st.write(title)st.subheader("⭐ 视频文本:")st.write(content)
2.5 本地运行
1.终端运行
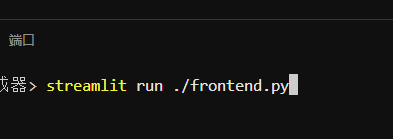
2.第一次运行之后,会叫你输入邮箱,输入即可
3.运行成功
2.6 streamlit云部署 (可选)
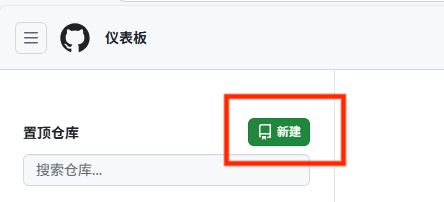
1.注册并登入github网页
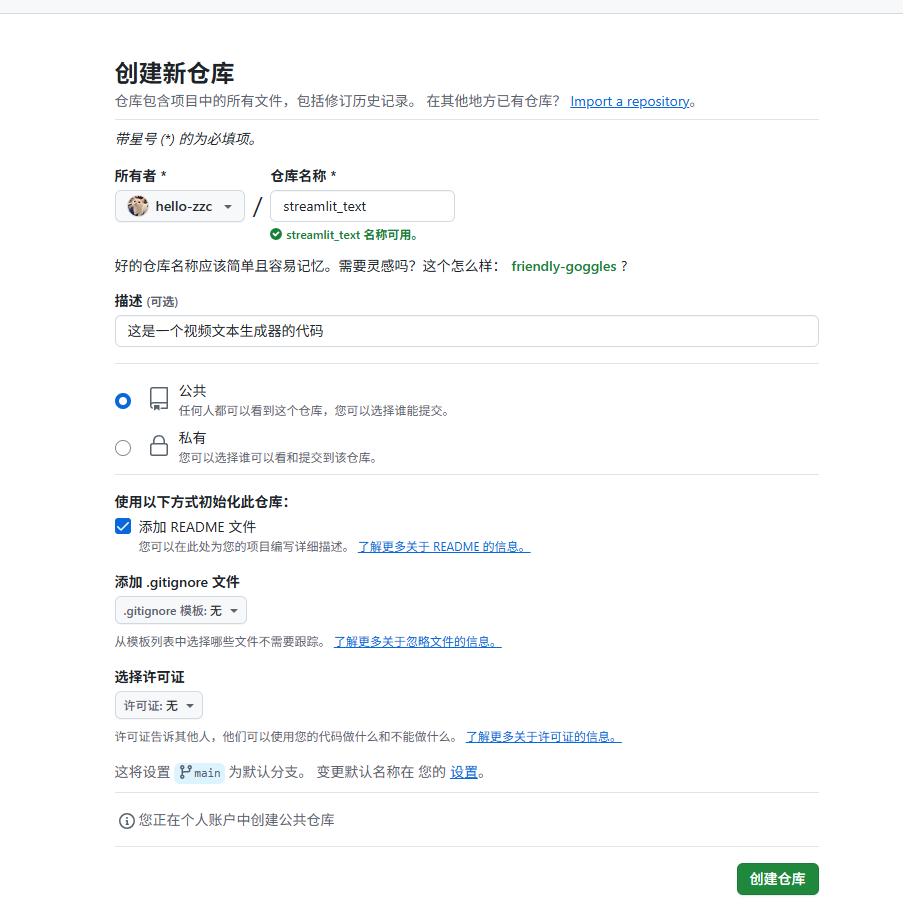
2.新建仓库
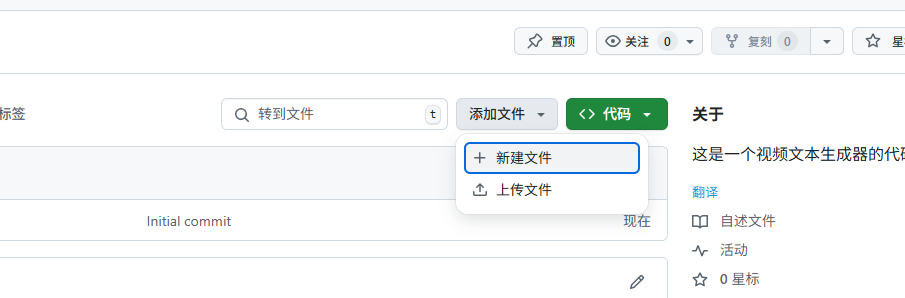
3.上传文件
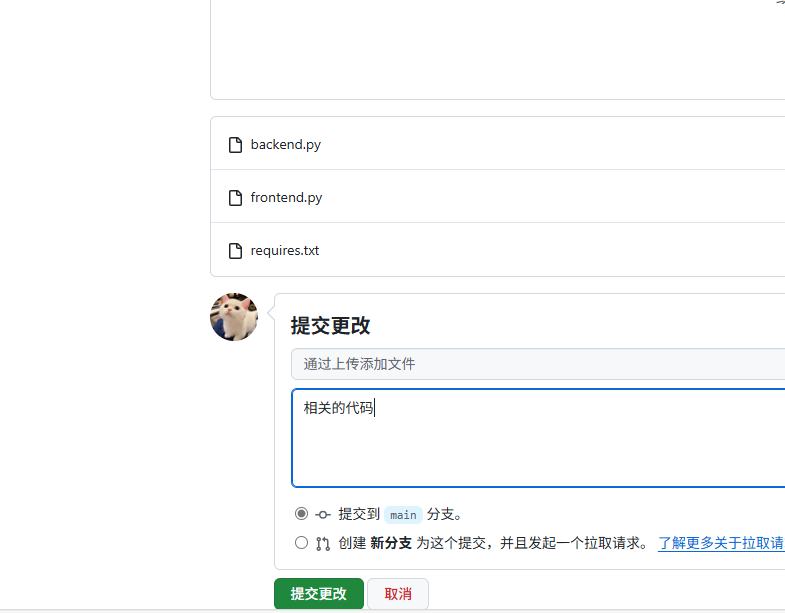
4.提交文件
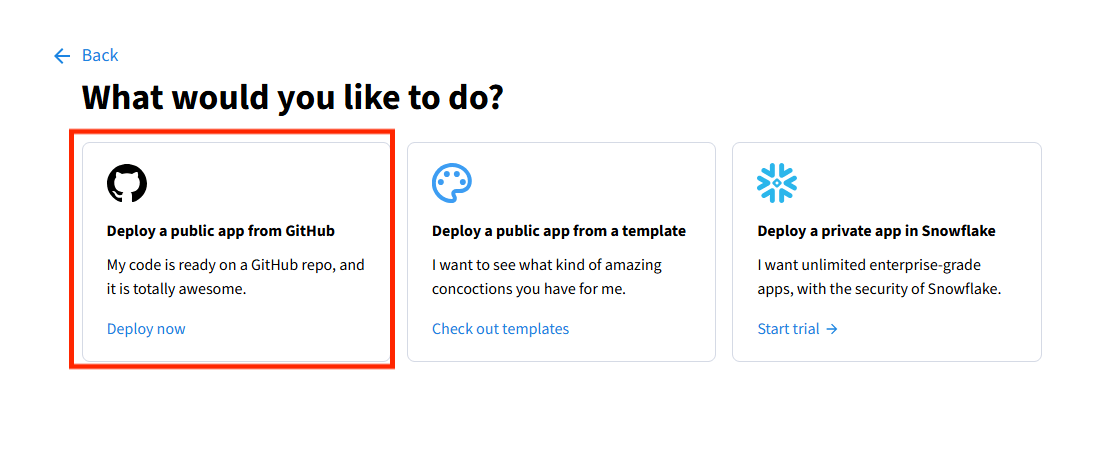
5.登入streamlit云
6.选择
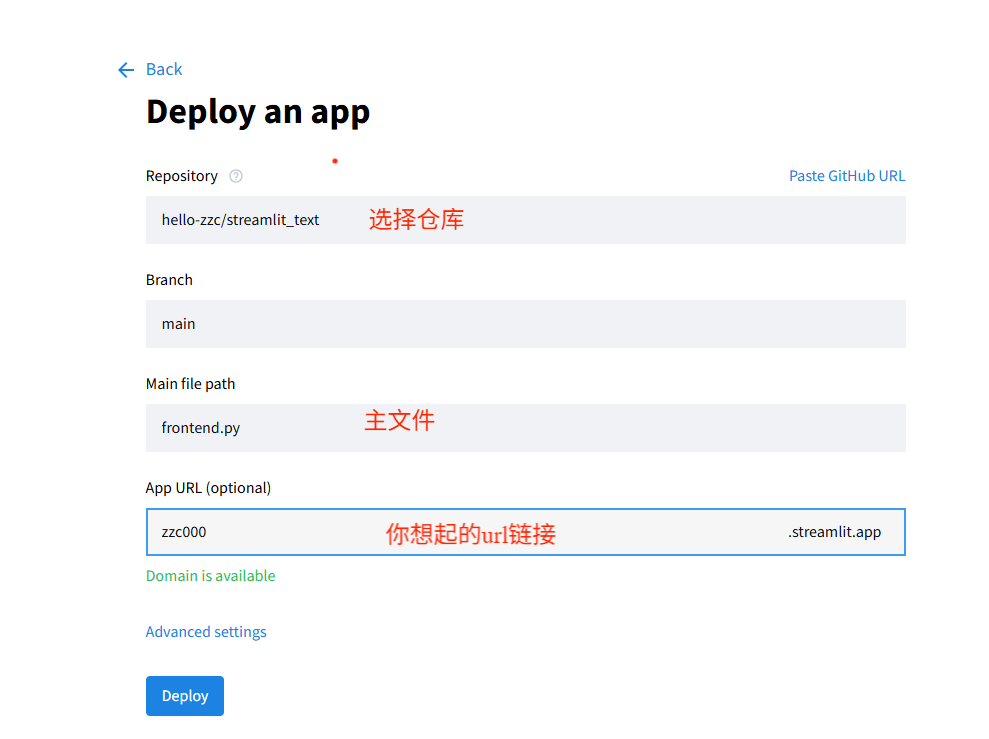
7.然后选择
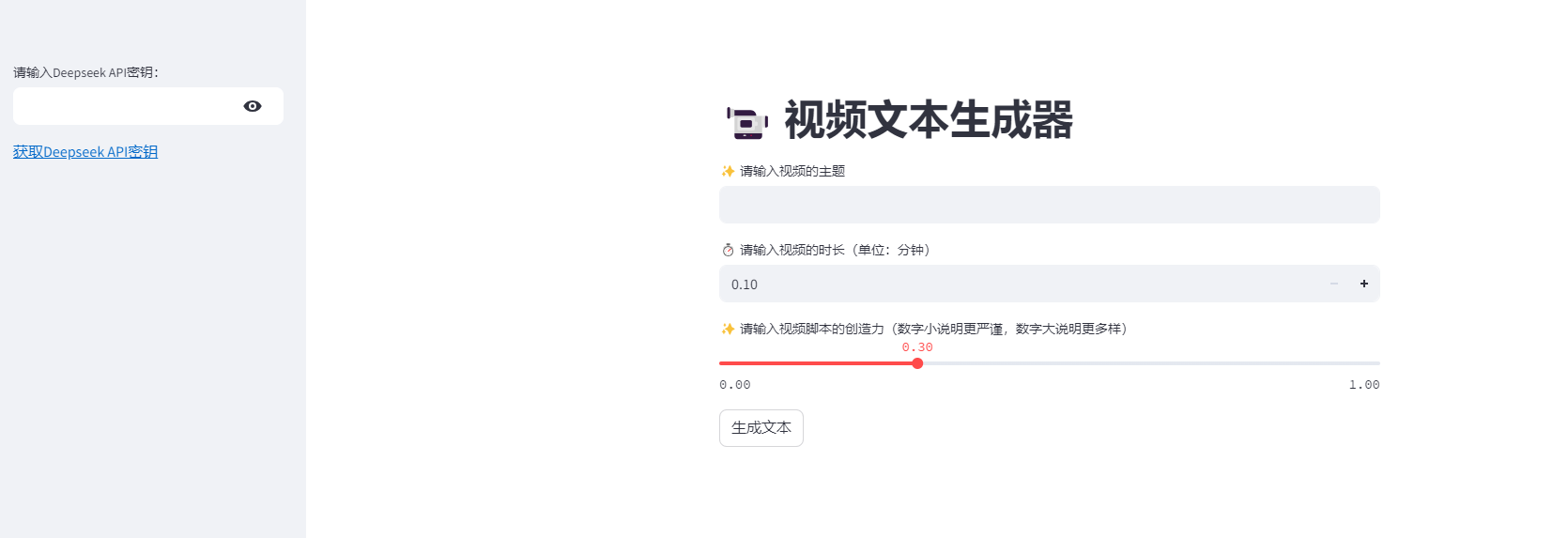
8.部署成功
视频文本生成器
9.若部署失败,需要删除失败的操作(可选)
三、😉想说的话
3.1 代码现状
个人感兴趣,玩一下,不足之处多多包涵。
主要问题有:
- 功能实现不够多
- 变量名起的不够精炼
3.2 改进方案
如何解决:
- 多学习,多练习,熟练度上去后,尝试表达想法。
- 勤注释,换位思考
- 多背单词
3.3 开发困难记录
练习过程中遇到的困难:
- 在streamlit云部署过程中第一次部署失败,因为库依赖多处发生冲突
- 第一次部署失败后,无论尝试多少次,链接一直未能正确更新,依旧卡在第一次失败点处
3.4 解决方案
如何解决的困难:
- 因为库依赖数量巨大,改不了,所以选择重新安装库,生成requirements.txt文件
- 删除streamlit云上的第一次失败部署
3.5代码汇总
个人主页csdn资源