Google机器学习实践指南(TensorFlow六大优化器)
🔥 Google机器学习实践指南(TensorFlow六大优化器)
Google机器学习实战(12)-20分钟掌握TensorFlow优化器
一、优化器核心作用
▲ 训练本质:
迭代求解使损失函数最小化的模型参数,关键要素:
- 特征工程(Feature)
- 优化算法(Optimizer)
本文主要对其中的优化算法进行说明,关于特征工程,欢迎查看前一篇:Google机器学习实战(11)-特征工程六大方法深度解析与应用
二、优化器类型详解
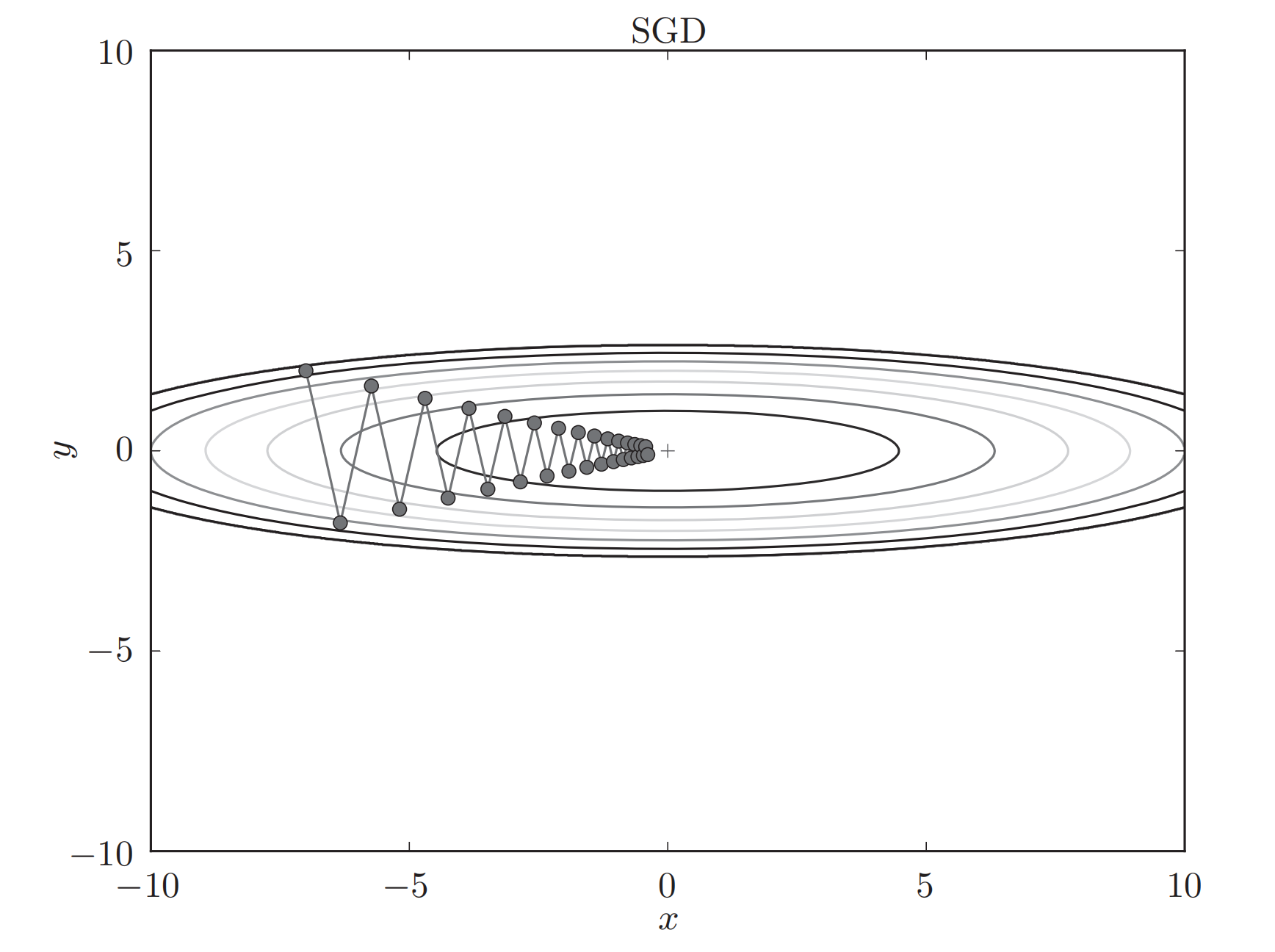
1. SGD随机梯度下降
**说明:**SGD全名 stochastic gradient descent, 即随机梯度下降,但在TensorFlow中SDG是指MBGD(minibatch gradient descent),即最小梯度下降。
**参数:**学习速率 ϵ, 初始参数 θ
实际实现:MBGD(小批量梯度下降)

▲ 图1 SGD参数更新过程
my_optimizer = tf.optimizers.SGD(learning_rate = 0.0000001, clipnorm=5.0)
特点:
- 训练速度快
- 自带正则化效果
2. Momentum
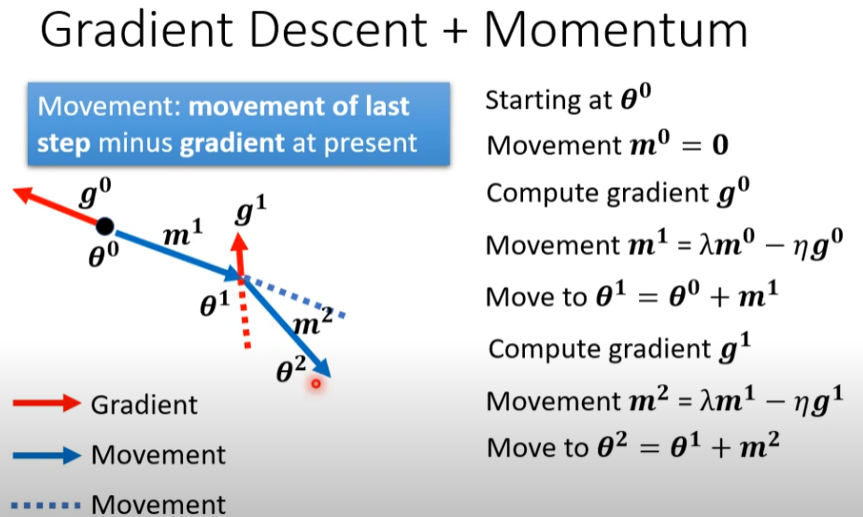
**说明:**momentum即动量,在更新的时候一定程度上保留之前更新的方向,同时利用当前batch的梯度微调最终的更新方向。从而在一定程度上增加稳定性,使得学习地更快,并且还有一定摆脱局部最优的能力。
**参数:**学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
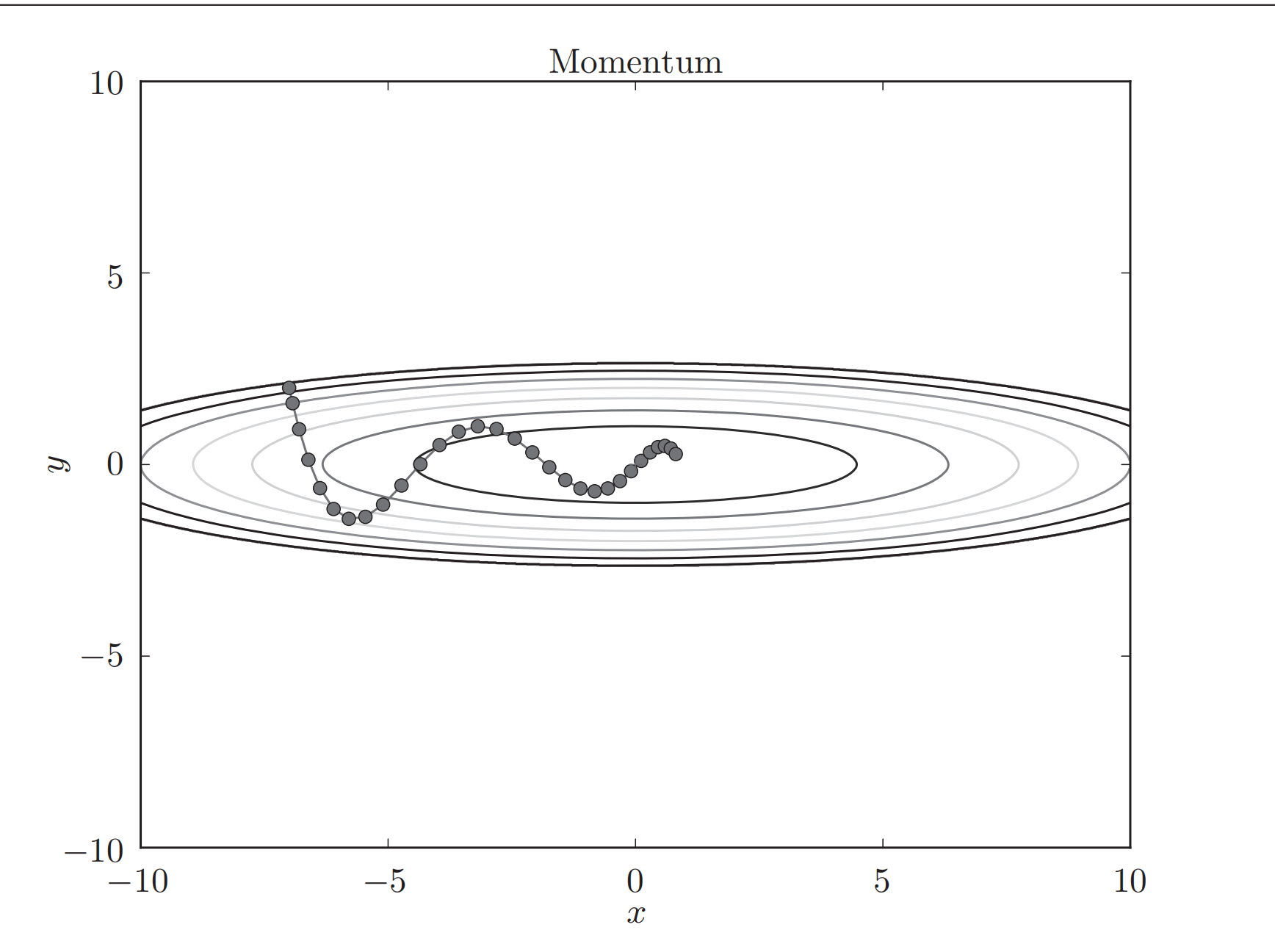
▲ 图2 普通SGD与Momentum法对比
优势:
- 加速同向梯度学习
- 抑制方向震荡
3. Nesterov Momentum
**说明:**Nesterov Momentum(牛顿动量法)是momentum方法的一项改进,与Momentum唯一区别是计算梯度的不同,Nesterov momentum先用当前的速度v更新一遍参数,再用更新的临时参数计算梯度。
**参数:**学习速率 ϵ, 初始参数 θ, 初始速率v, 动量衰减参数α
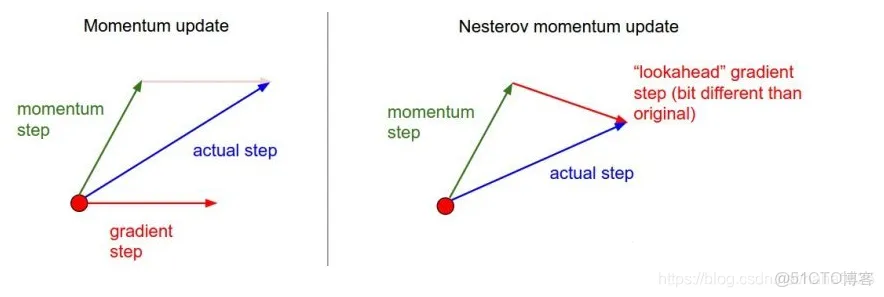
▲ 图3 Nesterov Momentum前瞻性更新
改进点:
- 先按当前速度更新参数
- 在临时参数点计算梯度
4. AdaGrad
说明:AdaGrad(自适应梯度算法)是一种自适应学习率的梯度下降优化算法。它通过累积参数梯度的历史信息来为每个参数自适应地调整学习率。
参数: 全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ
优点:
- 能够实现学习率的自动更改
缺陷:
- 深度网络易提前终止
5. RMSProp
说明: RMSProp通过引入一个衰减系数,让r每回合都衰减一定比例,类是对AdaGrad算法的改进。
参数: 全局学习速率 ϵ, 初始参数 θ, 数值稳定量δ,衰减速率ρ
▲ 图4 学习率自适应过程
改进:
- 引入衰减系数ρ
- 解决AdaGrad过早收敛问题
6. Adam
**说明:**Adam(Adaptive Moment Estimation)本质上是带有动量项的RMSprop,利用梯度的一阶矩估计和二阶矩估计动态调整每个参数的学习率。Adam的优点主要在于经过偏置校正后,每一次迭代学习率都有个确定范围,使得参数比较平稳。
**参数:**步进值 ϵ, 初始参数 θ, 数值稳定量δ,一阶动量衰减系数ρ1, 二阶动量衰减系数ρ2 (经验值:δ=10^−8,ρ1=0.9,ρ2=0.999)。
算法流程:
- 计算一阶/二阶动量
- 偏差校正
- 参数更新
参数建议:
- ρ1=0.9
- ρ2=0.999
- δ=10^-8
三、优化器性能对比
| 优化器 | 收敛速度 | 内存消耗 | 超参数敏感性 |
|---|---|---|---|
| SGD | ⭐⭐ | 低 | 高 |
| Momentum | ⭐⭐⭐ | 中 | 中 |
| Nesterov Momentum | ⭐⭐⭐⭐ | 中 | 中 |
| AdaGrad | ⭐⭐ | 高 | 低 |
| RMSProp | ⭐⭐⭐ | 中 | 中 |
| Adam | ⭐⭐⭐⭐ | 中 | 低 |
四、工程实践建议
✅ 选择策略:
- 简单任务:SGD+Momentum
- 稀疏数据:AdaGrad
- 默认首选:Adam
✅ 调参技巧:
lr_schedule = tf.optimizers.schedules.PolynomialDecay(initial_learning_rate=0.01,decay_steps=10000,end_learning_rate=0.001
)
# 技术问答 #
Q:Adam优化器为什么需要偏差校正?
A:解决初始阶段动量估计偏向0的问题,确保训练初期稳定性
Q:如何选择优化器?
A:从Adam开始尝试,对性能敏感场景可比较SGD+Momentum
附录:学习资源
TensorFlow优化器文档:https://www.tensorflow.org/api_docs/python/tf/optimizers
优化算法可视化:https://ruder.io/optimizing-gradient-descent/
参考文献:
[1]《深度学习优化算法综述》
[2] TensorFlow官方优化器指南