导入典籍数据
1.从网上获取中医相关典籍数据,数目共600+txt,总篇数14万+
2.数据处理
获取到的数据结构大致如下

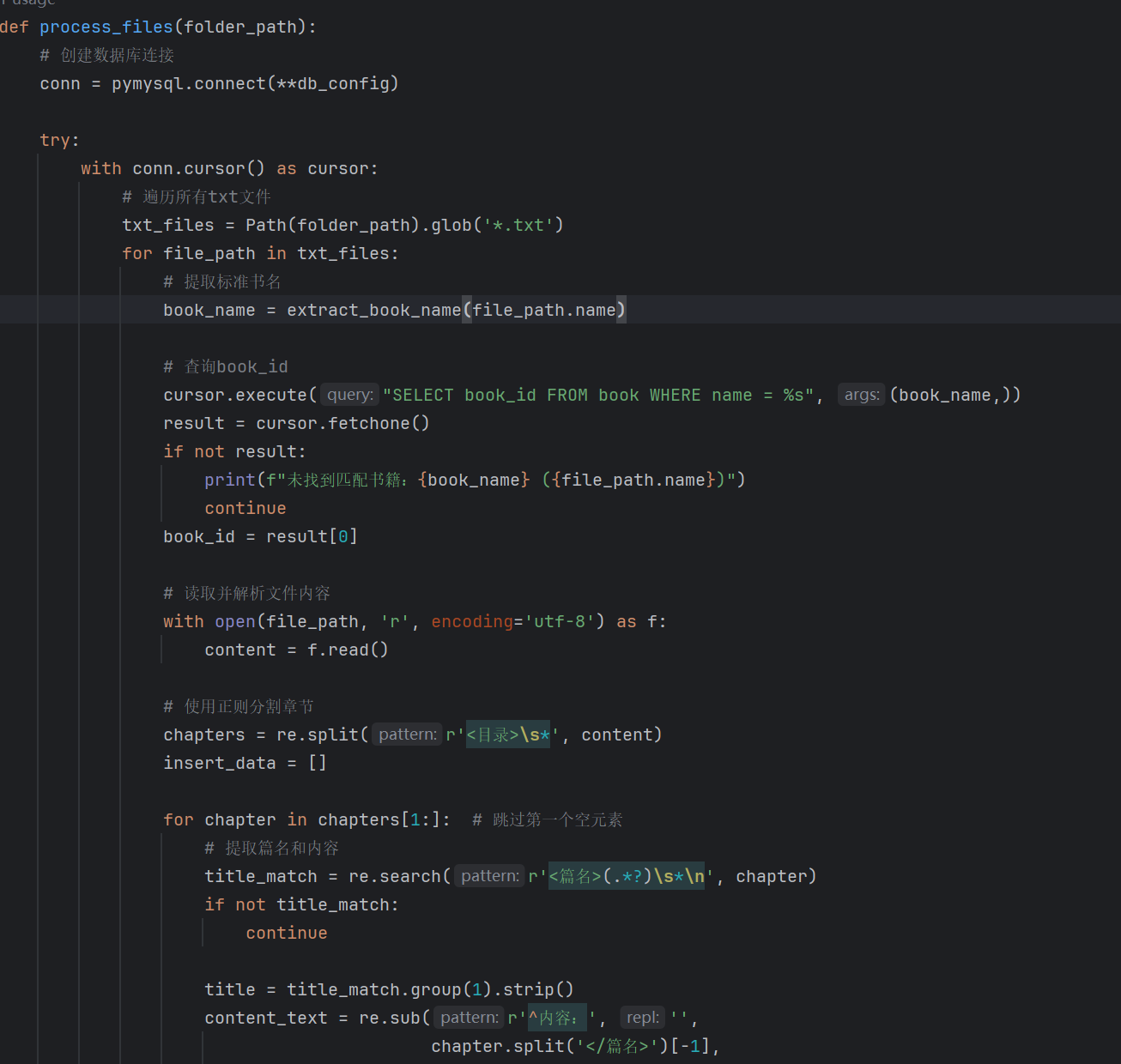
一个txt表示一本书,开头存有书籍相关的名字,作者,朝代,年份,之后每一个<目录>下都跟有一个篇目,标题由<篇名>开头,但并非所有txt都保持这样的格式,因此要先进行数据处理才能存到数据库中
2.1由于下载的txt数据编码格式不一,导致难以正常解析,因此先进行了编码统一化,将其全部变成utf-8编码格式
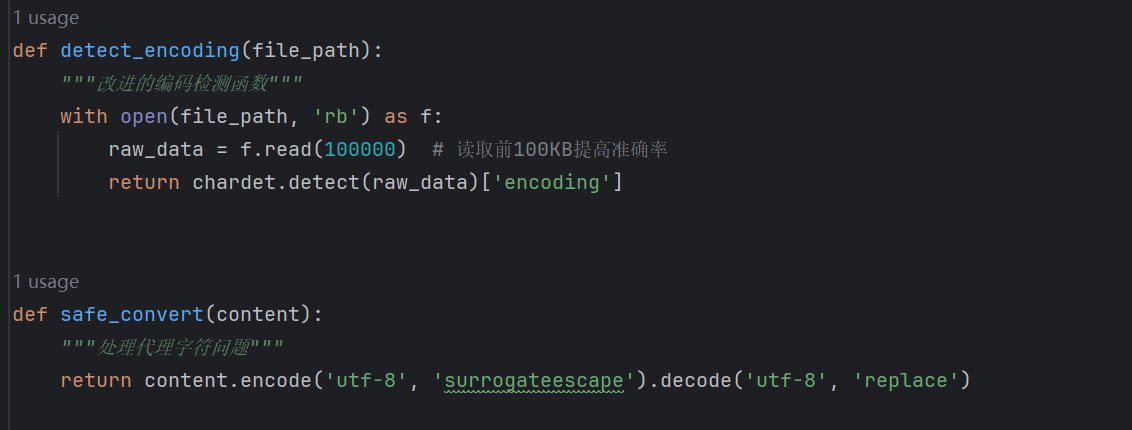
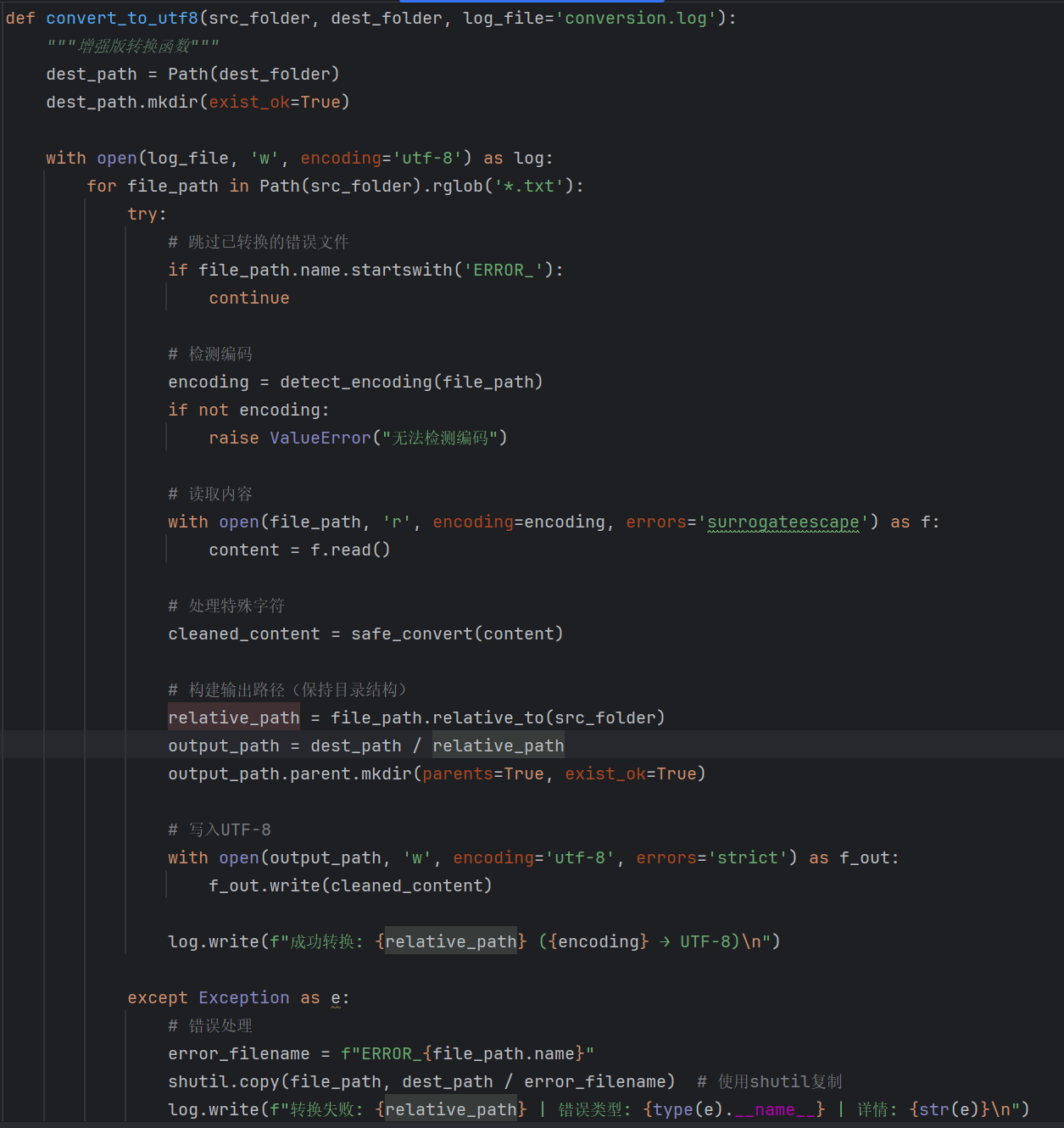
2.2对编码格式转化好的txt文件存入数据库
2.2.1通过对txt内容进行解析将书籍相关信息存入book表,包括bookid,name,author,dynasty,year
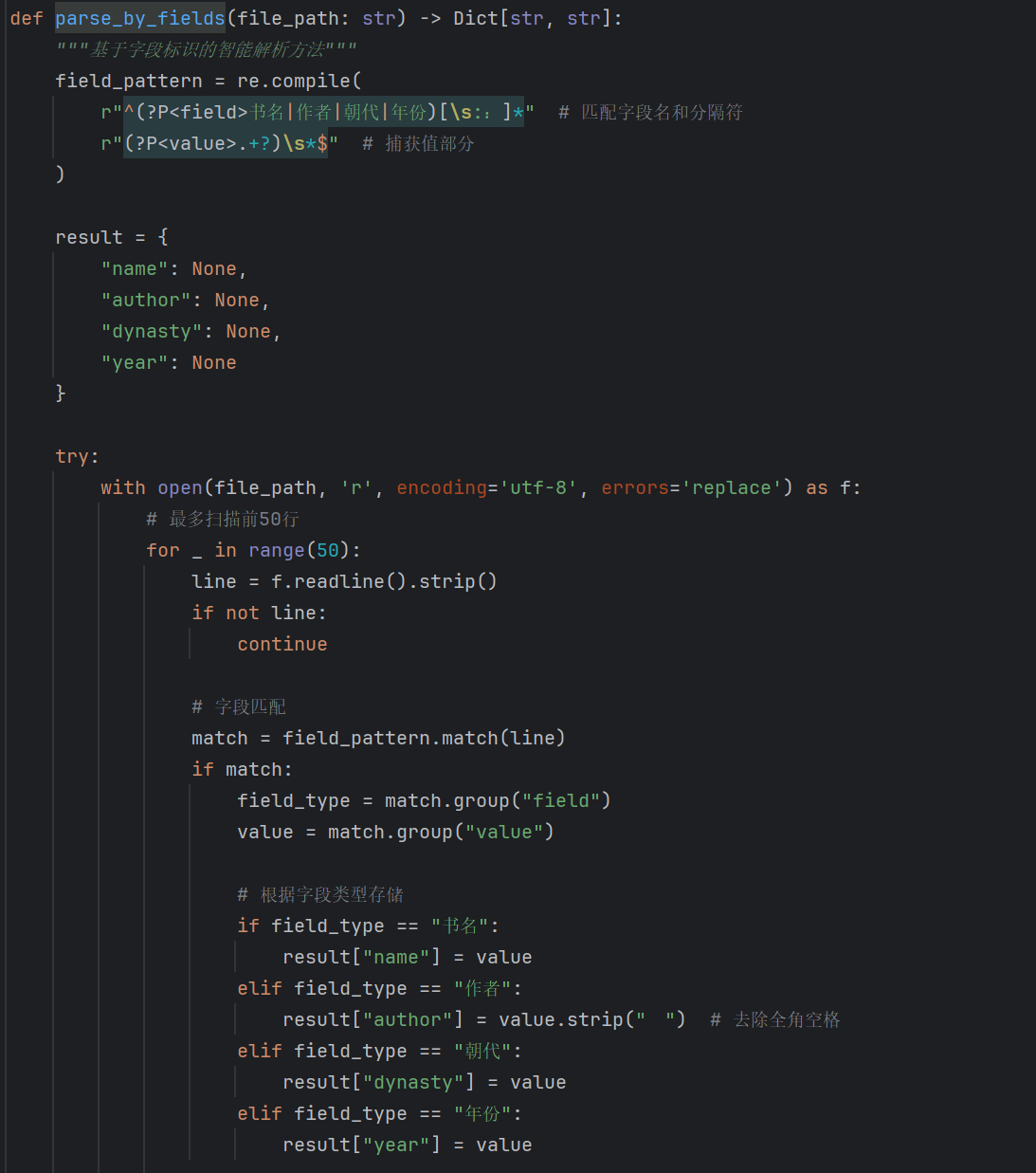
2.2.2删去没能成功处理的书籍
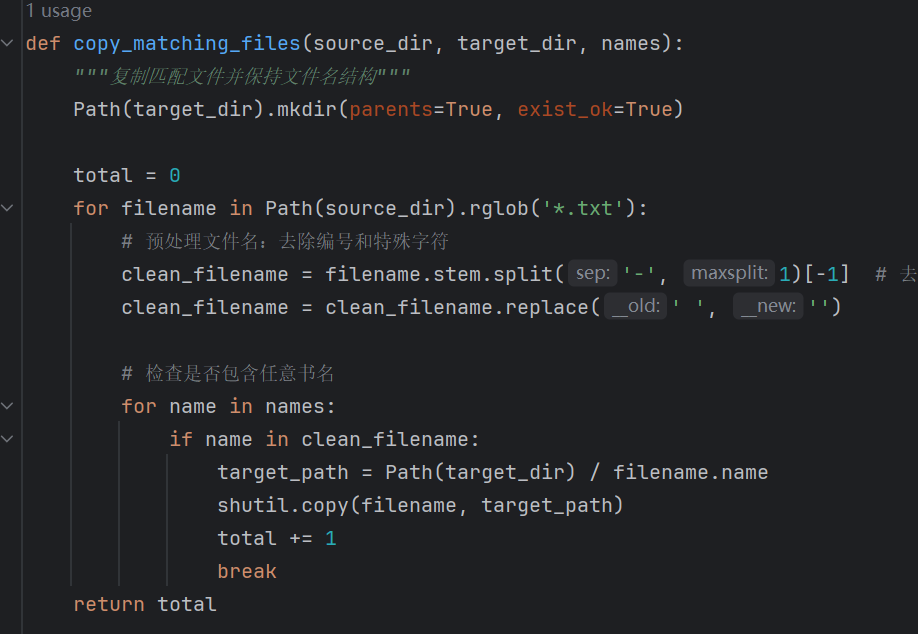
2.2.3
解析清洗后的txt文件,提取其中每本书的篇目,将它们存入classics表中
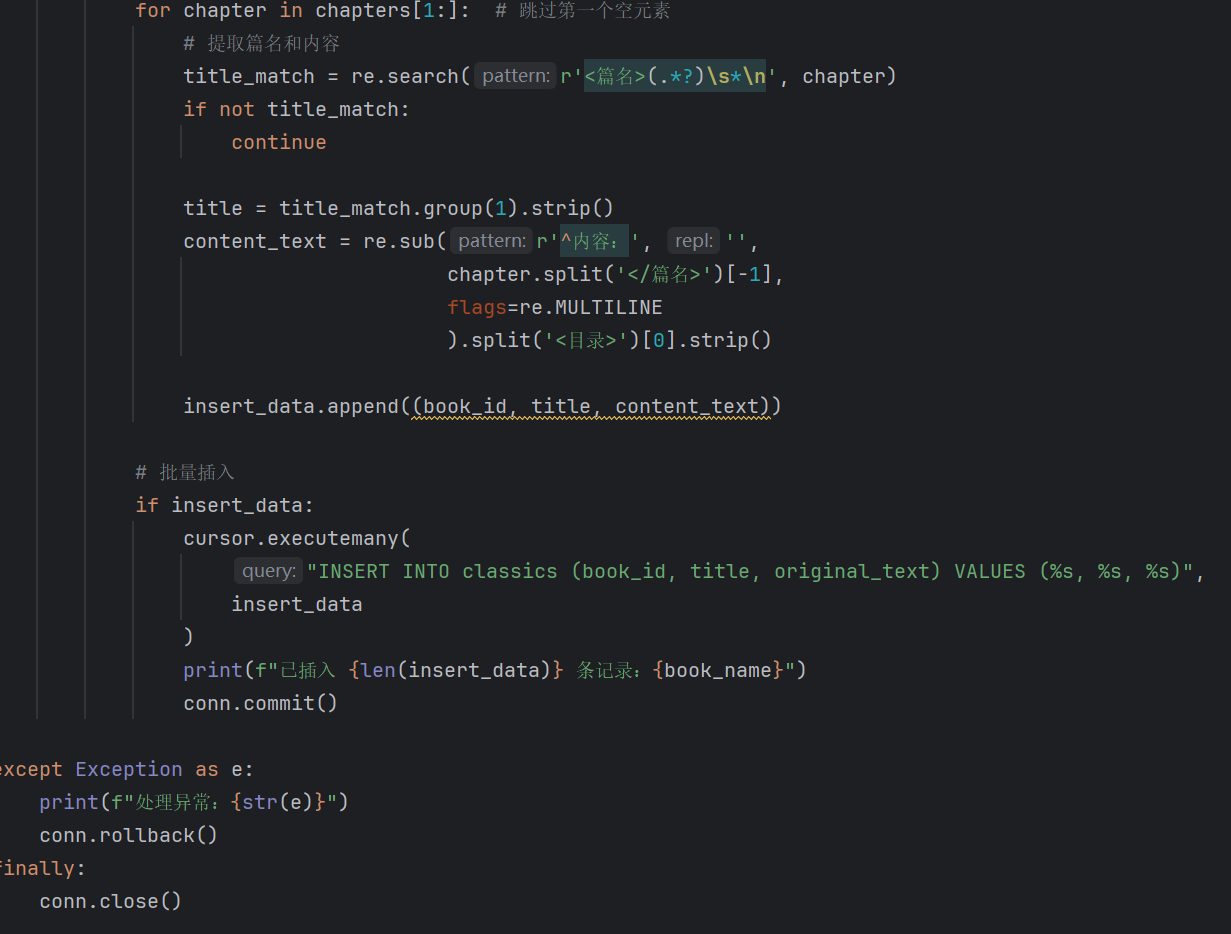
3.处理后数据提取后展示
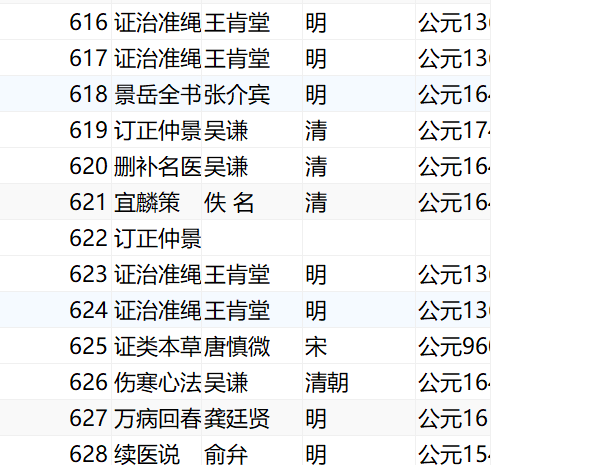
共628篇书目
共141180个典籍篇目
