R语言使用随机过采样(Random Oversampling)平衡数据集
随机过采样(Random Oversampling)是一种用于平衡数据集的技术,常用于机器学习中处理类别不平衡问题。当某个类别的样本数量远少于其他类别时(例如二分类中的正负样本比例悬殊),模型可能会偏向多数类,导致对少数类的预测性能较差。随机过采样通过复制少数类的样本来增加其数量,从而达到类别平衡的目的。
通俗简单的来说,随机过采样是一种简单但有效的技术,它从少数类中随机选择样本并复制它们,直到各类样本数量相等或接近为止。
随机过采样的优点:
实现简单。
不改变原始数据分布。
能有效缓解类别不平衡带来的偏差。
随机过采样的缺点:
容易引起过拟合:因为是直接复制已有样本,模型可能记住这些样本而不是学习泛化特征。
没有引入新的信息,只是重复已有样本。
下面咱们通过R语言简单介绍一下使用随机过采样(Random Oversampling)平衡数据,方法来源于文章(Lunardon, N., Menardi, G., Torelli, N.J.R.J., 2014. ROSE: a Package for Binary )
Imbalanced Learning, 6, p. 79)
先导入R包
# 加载所需库
library(ROSE)
library(ggplot2)
library(dplyr)
咱们先生成一个不平衡的二分类数据
# 设置随机种子以确保结果可复现
set.seed(123)
# 假设有 1000 个样本,其中只有 10% 是正类(y=1)n <- 1000
X1 <- rnorm(n) # 特征1
X2 <- rnorm(n) # 特征2
y <- rbinom(n, size = 1, prob = 0.1) # 少数类只占10%# 构建数据框
data <- data.frame(X1 = X1, X2 = X2, y = as.factor(y))
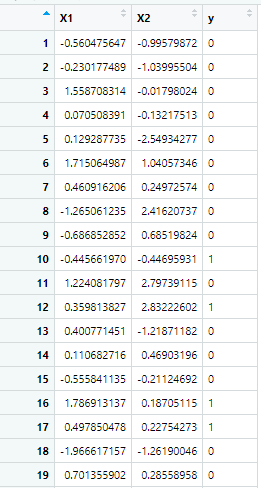
咱们可以看到数据的0很多1很少,这个属于数据阳性比例过少,数据不平衡,
table(data$y)
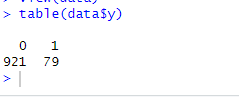
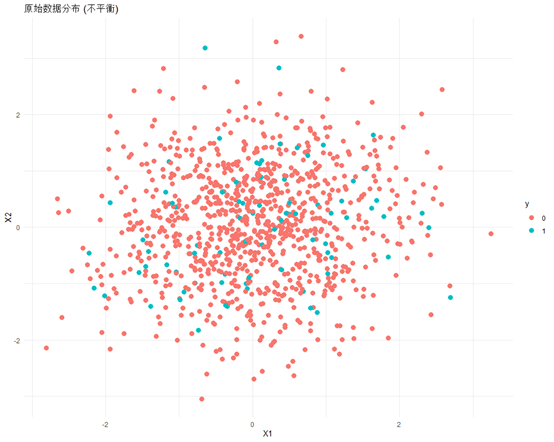
可以看到,阳性结果大概只有十分之一,图示一下
# 绘制原始数据分布图
ggplot(data, aes(x = X1, y = X2, color = y)) +geom_point(size=2) +ggtitle("原始数据分布 (不平衡)") +theme_minimal()
下面咱们使用随机过采样(Random Oversampling)平衡数据,使用 ROSE 包中的 ovun.sample 函数,设置 method = “over”,默认将各类样本数量调整为与最多类相同,其实非常用以,就是一句话代码
data_over <- ovun.sample(y ~ ., data = data, method = "over", seed = 123)$data
查看过采样后的类别分布
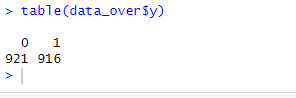
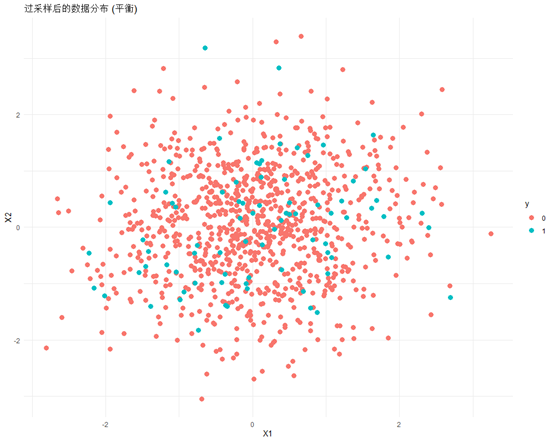
可以看到,1明显增多了,图示一下
# 绘制过采样后的数据分布图
ggplot(data_over, aes(x = X1, y = X2, color = y)) +geom_point(size=3) +ggtitle("过采样后的数据分布 (平衡)") +theme_minimal()
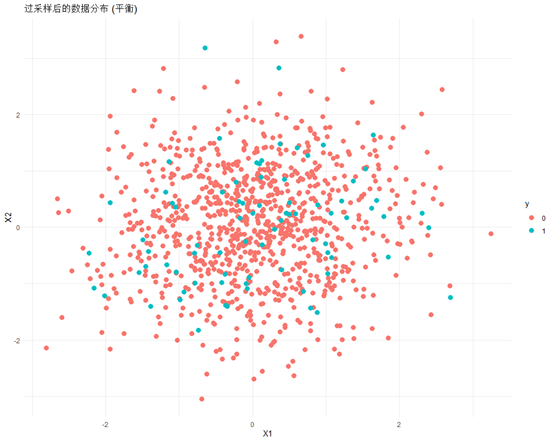
最后我来总结一下,ROSE法随机过采样方法,属于比较简单的平衡数据集方法,随机过采样最简单的方式是直接从少数类中随机抽取样本并复制它们。这种做法会使得少数类的样本数量增加,从而在某种程度上改变了原始的数据分布。特别是当过采样的比例较高时,会导致模型看到更多的重复样本。
由于少数类样本被重复使用,模型可能学会这些特定样本的细节和噪音,而非一般化的模式。这意味着模型可能会对训练集上的表现非常好,但在未见过的数据(测试集或真实世界中的新数据)上表现较差,即发生过拟合。
目前这类方法用于机器学习比较多,对于逻辑回归这样的线性分类器,随机过采样可以通过增加少数类的权重来帮助模型“注意到”这些样本。然而,这也可能导致模型对少数类的预测过于乐观,因为它是在一个经过人为调整的数据分布上进行训练的。因此进行敏感性分析我认为是十分必要的。
后面会介绍一下更加高级的方法,如SMOTE合成采样。