LLM:Scaling Law
文章目录
- 前言
- 一、幂律
- 二、LLM中的幂律
- 三、GPT中的scaling
- 四、ChatGPT时代
- 五、最优的Scaling Law
- 总结
前言
各种LLM百花齐放,1B,2B,7B等等预训练模型,但是否思考过模型的大小和训练数据的关系。模型大小和训练数据对模型性能(即测试损失)的贡献是否相等?哪一个更重要?如果我想将测试损失降低10%,我应该增加模型大小还是训练数据?需要增加多少?这就是本文的核心讨论点 Scaling Law(来自机器学习研究科学家 Cameron R. Wolfe 一篇超长的blog)
原文链接:https://cameronrwolfe.substack.com/p/llm-scaling-laws
“If you have a large dataset and you train a very big neural network, then success is guaranteed!” - Ilya Sutskever
一、幂律
基本的幂律可表示为以下公式:
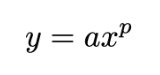
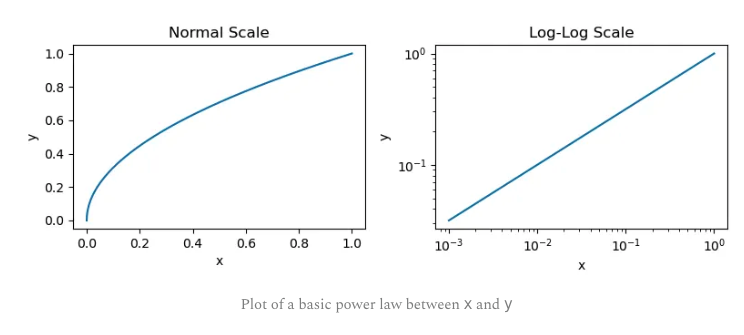
这里研究的两个量是 x 和 y,而 a 和 p 是描述这些量之间关系的常数。如果我们绘出这个幂律函数,我们会得到如下所示的图。这里提供普通和对数度量的图,因为大多数研究 LLM scaling 的论文都使用对数度量(对数度量能反映线性关系)。
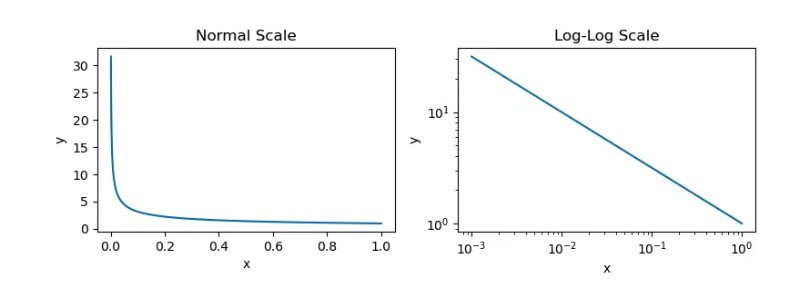
但很多时候,展示 LLM scaling 的图看起来并不像上面的图,而通常是上下颠倒的;请参阅下面的示例。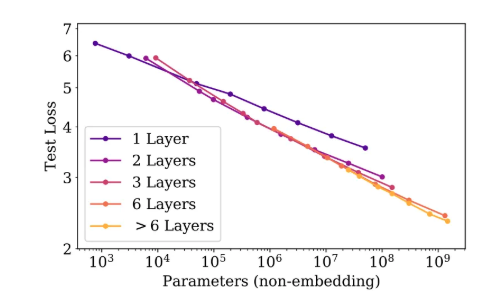
这只是逆幂律,通常会对 p 使用负指数。使幂律的指数为负数会使图颠倒过来
二、LLM中的幂律
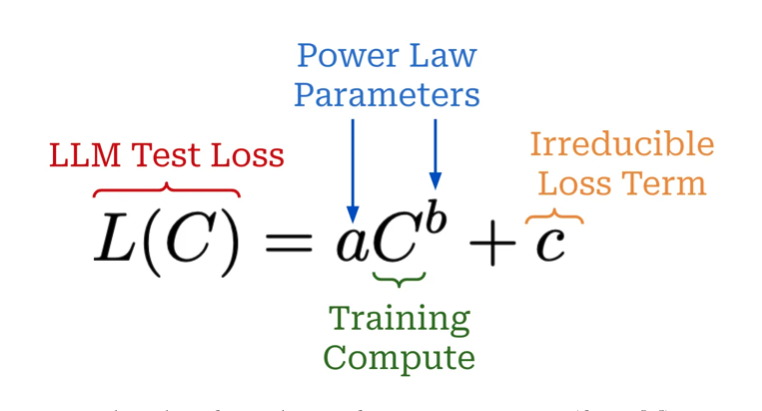
分别以 计算成本,训练数据规模, 模型参数量为三个变量分析对Loss的影响,如下图 (图中呈现为log图,alpha为作者统计的数字,可视为log图下的斜率)
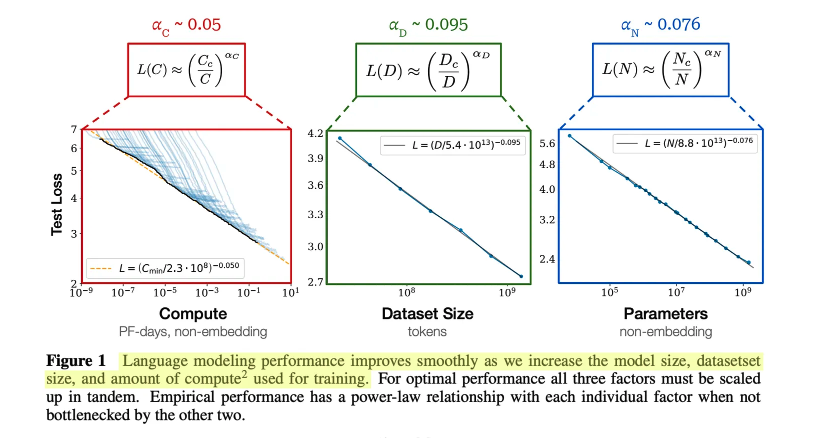
因此,为了获得最佳性能,应该同时增大这三个分量(模型大小、数据和计算量)。如果我们单独增大其中任何一个分量,我们就会达到某个收益递减点。
此外有个作者提到了一个有意思的点,较大的 LLM 往往具有更高的样本效率,这意味着它们在数据较少的情况下可达到与较小模型相同的测试损失水平。因此,对 LLM 进行预训练以使其收敛(可以说)不是最优的。相反,我们可以在较少的数据上训练更大的模型,在收敛之前停止训练过程。(但实际上这种情况很少见,数据少一般用小模型就足够了,推理成本也更低)
作者还广泛分析了模型大小与用于预训练的数据量之间的关系,发现数据集的大小不需要像模型大小那样快速增加。模型大小增加约 8 倍需要训练数据量增加约 5 倍才能避免过拟合。
三、GPT中的scaling
LLM Scaling Law 最广为人知和最明显的应用是 OpenAI 打造的 GPT 系列模型。这里聚焦系列中早期的开放模型 —— GPT-3
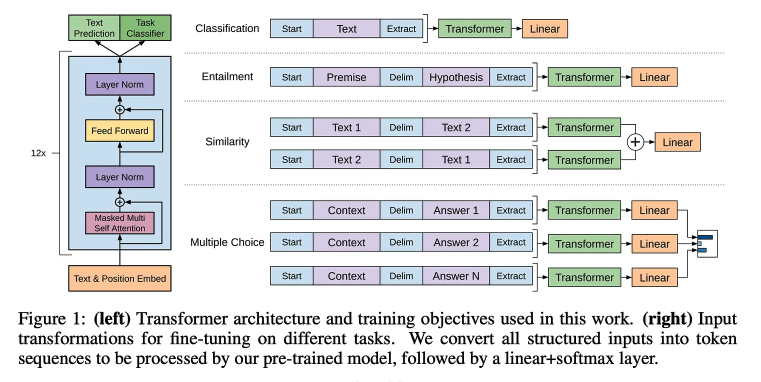
最早的 GPT 模型实际上非常小 — 总共 12 层和 117M 参数。**该模型首先在 BooksCorpus 上进行预训练,BooksCorpus 是一个包含约 7000 本书原始文本的数据集。然后,使用监督训练目标并为每个任务创建单独的分类头来微调模型以解决各种不同的下游任务。**这篇论文是第一批对decoder-only Transformer 进行大规模自监督预训练的论文之一,其中得到了一些有趣的发现:
- 对纯文本进行自监督预训练非常有效。
- 使用长而连续的文本跨度进行预训练非常重要。
- 以这种方式进行预训练后,可以对单个模型进行微调,使其能以最领先的准确度解决各种不同的任务。
与 GPT 相比,GPT-2 对预训练过程进行了两大改变:
- 预训练数据集改成了 WebText,它比 BooksCorpus 大得多,并且是通过从互联网上抓取数据创建的。
- 这些模型没有针对下游任务进行微调。相反,是通过使用预训练模型执行零样本推理来解决任务。
GPT-3 明确证实了大规模预训练对 LLM 的好处,GPT-3 使用的decoder-only架构与之前的模型非常相似,但预训练却是基于 CommonCrawl 的更大数据集。这个数据集比之前的 WebText 数据集大约大 10 倍。
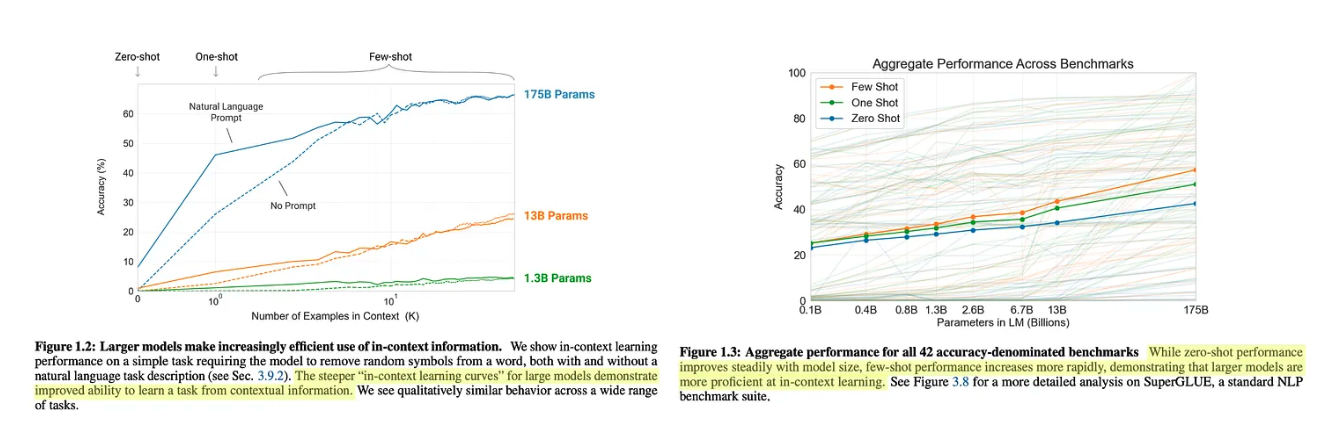
GPT-3 主要通过使用少样本学习(上下文学习 in-context learning)方法进行评估。少样本提示(GPT-3 使用)、零样本提示(GPT-2 使用)和微调(GPT 使用)之间的差异如下所示。

当在各种语言理解任务上评估 GPT-3 时,研究者发现使用较大的模型时,可显著提高少样本学习的性能,如下图所示。与较小的模型相比,较大的模型可以更好、更有效地利用其上下文窗口中的信息。GPT-3 能够通过少样本学习在多个任务上超越 SOTA,并且模型的性能随着规模的扩大还能平稳提升。
四、ChatGPT时代
GPT3不需要对底层模型进行任何微调或更改 —— 只需要调整模型的提示词即可达到优秀的表现。使模型开创了 AI 研究的下一个时代,并引入了一种与 LLM 交互(即提示词)的全新直观范式。
OpenAI 发布的接下来几个模型 ——InstructGPT、ChatGPT 和 GPT-4—— 结合了大规模预训练和新的后训练技术(即监督微调和 RLHF),大大提高了 LLM 质量。
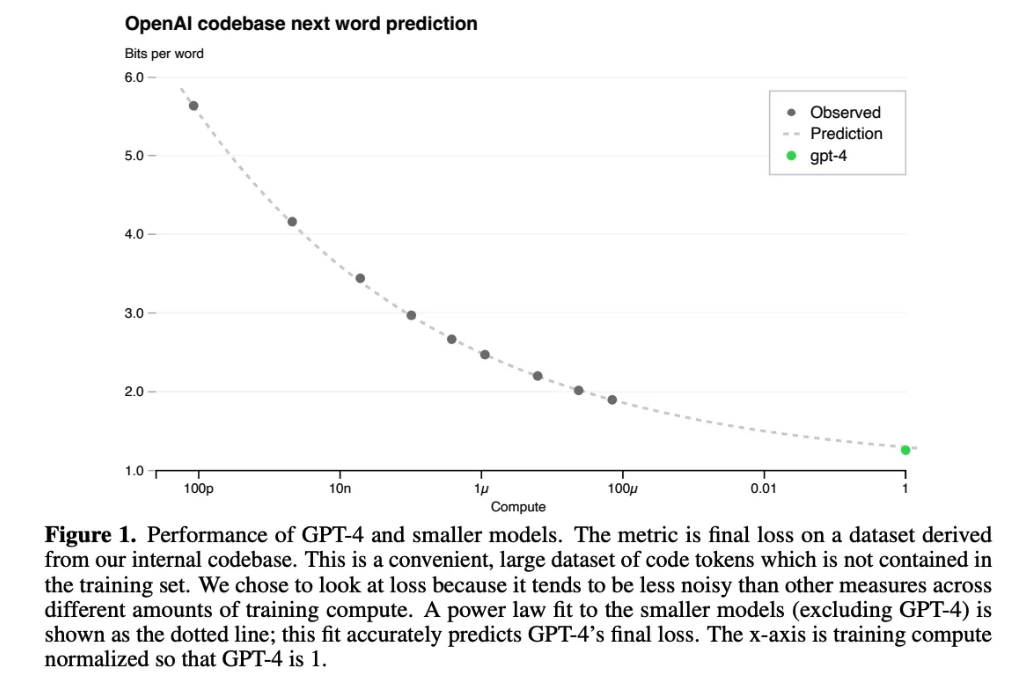
大规模预训练成本非常高,因此研究者通常只有一次机会来做对 —— 根本没有针对具体模型调整的空间。Scaling Law 在此过程中起着关键作用。研究者可以使用少成千上万倍的计算量来训练模型,并使用这些结果来拟合幂律。然后,这些幂律可用于预测更大模型的性能。特别是,研究者在中看到,可使用衡量计算和测试损失之间关系的幂律来预测 GPT-4 的性能;
一旦拟合,Scaling Law 就可用来以非常高的准确度预测 GPT-4 的最终性能;其中a b两个幂律参数就是由多个小模型拟合出来的。在这里,我们应该注意,该图没有使用对数尺度,可以看到损失的改善随着计算量的增加而明显开始衰减
五、最优的Scaling Law
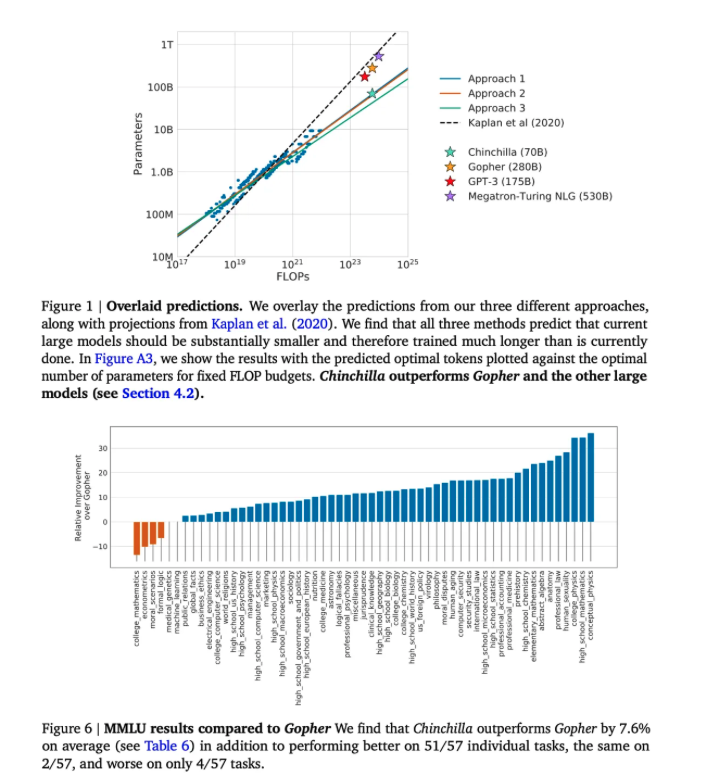
GPT-3 之后的大多数研究者训练的模型明显大于 GPT-3—— 例如 530B 参数 MT-NLG模型 —— 但用于训练这些模型的数据集的大小与 GPT-3 相似。这些模型并没有在 GPT-3 之上实现性能提升,而使用更多参数和更多数据组合的模型表现要好得多
受这些观察的启发,通过使用许多不同的模型和数据大小组合训练 LLM,我们可以发现一个幂律,该幂律可以根据这些因素预测 LLM 的测试损失。
根据这些幂律,研究者可以确定哪种训练设置最适合给定的计算预算。研究者认为,计算最优的训练应该按比例 scaling 模型和数据大小。这一发现表明,大多数 LLM 都训练不足,无法拟合其规模 —— 使用大量数据训练现有的 LLM 将对研究者大有裨益。
为了验证这一发现,作者训练了一个 700 亿参数的 LLM,称为 Chinchilla。与之前的模型相比,Chinchilla 较小,但拥有更大的预训练数据集 —— 总共 1.4T 个训练 token。Chinchilla 使用与 Gopher 相同的数据和评估策略。尽管比 Gopher 小 4 倍,但 Chinchilla 的表现始终优于更大的模型;
总结
虽然为了 scaling LLM 预训练,研究者必须同时增加模型和数据集的大小。但是最近的研究表明,大多数研究人员更喜欢「过度训练」他们的模型 —— 由于较大的模型在推理时成本更高,因此现在对较小的模型进行过度训练是一种常见的做法。
另外,scaling LLM 预训练将需要研究者创建更大的预训练数据集,然而目前已经很难找到新的大规模高质量预训练数据来源,因此scaling 未来是否需要转换方向也是目前的探究方向