深度学习学习率优化方法——pytorch中各类warm up策略
warm-up具体原理以及为什么这么做在之前的博客有介绍,这里直接介绍如何直接使用pytorch中的warm-up策略,在pytorch中对于warm-up所有支持的方法都有描述,可以直接阅读1。
深度学习中各类学习率优化方法(AdaGrad/RMSprop/Adam/Warm-UP)原理及其代码
前言
在pytorch中,选择优化器(torch.optim)一般在使用过程中直接通过这个去定义我们所需要的优化器,如adam等,因此对于其基础类(torch.optim.Optimizer(params, defaults))一般就是直接输入模型的参数,而后可以直接通过这个类去做一些基本操作,如Optimizer.load_state_dict 加载优化器状态等。直接通过Adamw来解释(都是直接继承这个基础类的)
class AdamW(Optimizer):def __init__(self,params: ParamsT,lr: Union[float, Tensor] = 1e-3,betas: Tuple[float, float] = (0.9, 0.999),eps: float = 1e-8,weight_decay: float = 1e-2,amsgrad: bool = False,*,maximize: bool = False,foreach: Optional[bool] = None,capturable: bool = False,differentiable: bool = False,fused: Optional[bool] = None,):
其中不同变量含义为:
1、params:一般就是网络结构的优化参数
对于这个参数可以多了解一些,一般使用过程中都是直接
model.parameters(),但是有些时候,比如模型结构复杂可能对于不同的网络结构选择不同的学习率等,可以直接optimizer = torch.optim.AdamW([{'params': model.fc1.parameters(), 'lr': 1e-3},{'params': model.fc2.parameters(), 'lr': 1e-4, 'weight_decay': 0.01},],lr= 1e-5)
2、lr:学习率;3、betas:是一阶和二阶矩估计的指数衰减率;4、eps:为了防止除以 0 而加在分母中的一个非常小的数(epsilon);5、weight_decay:权重衰减系数(L2 正则化强度)
了解其基本优化算法之后在 torch.optim 也有另外一个“大杀器”:torch.optim.lr_scheduler 直接去对学习率进行优化
学习率优化器
上面已经介绍了 torch.optim.lr_scheduler这里直接进一步解释其各类方法以及代码实战。其中在 torch.optim.lr_scheduler 中大部分调整学习率的方法都是根据epoch训练次数。直接总结如下所示:
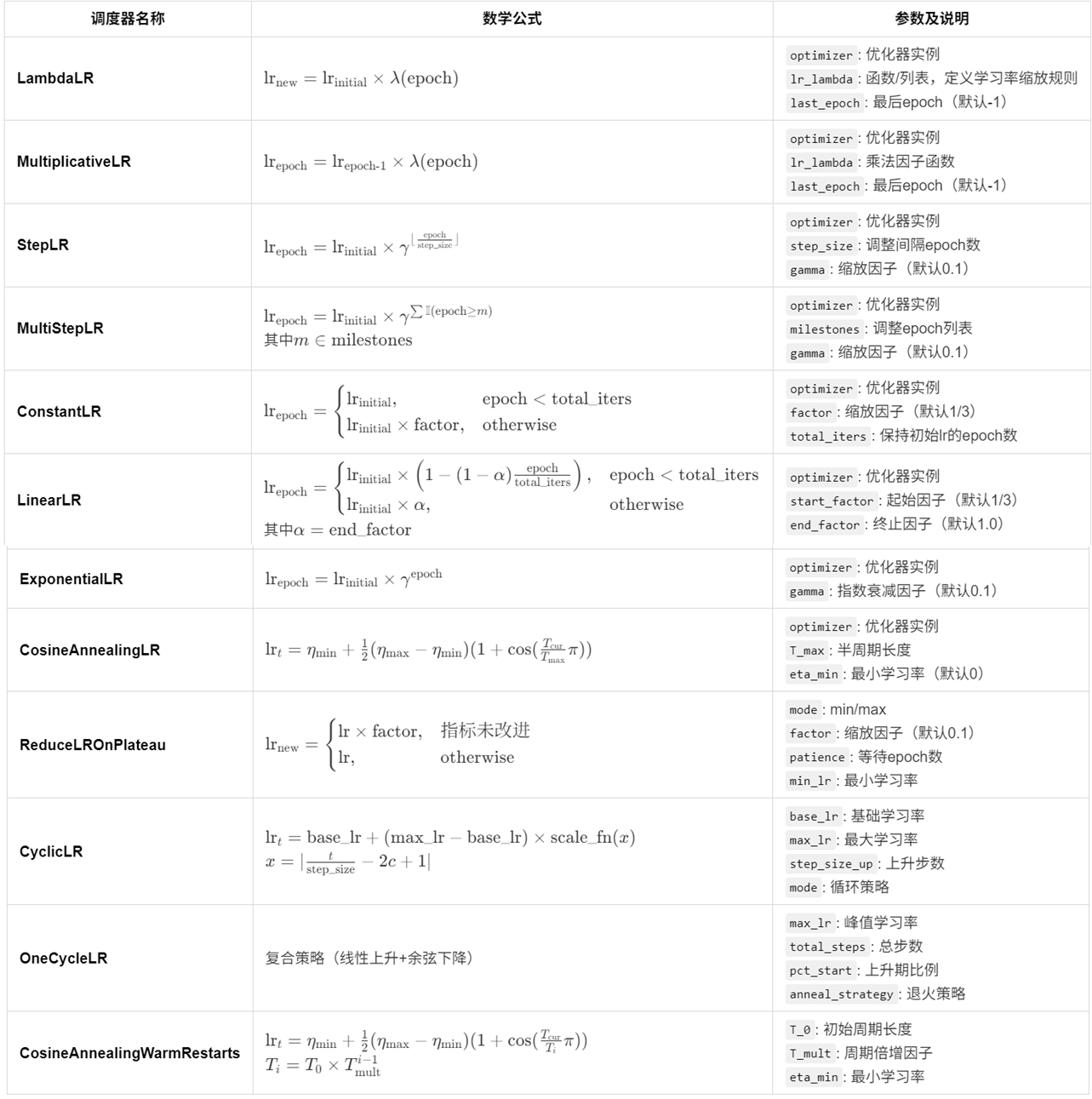
对于不同的优化器实际测试代码见文件:learning_rate.ipynb。于此同时不同学习率优化得到的学习率变化曲线为:
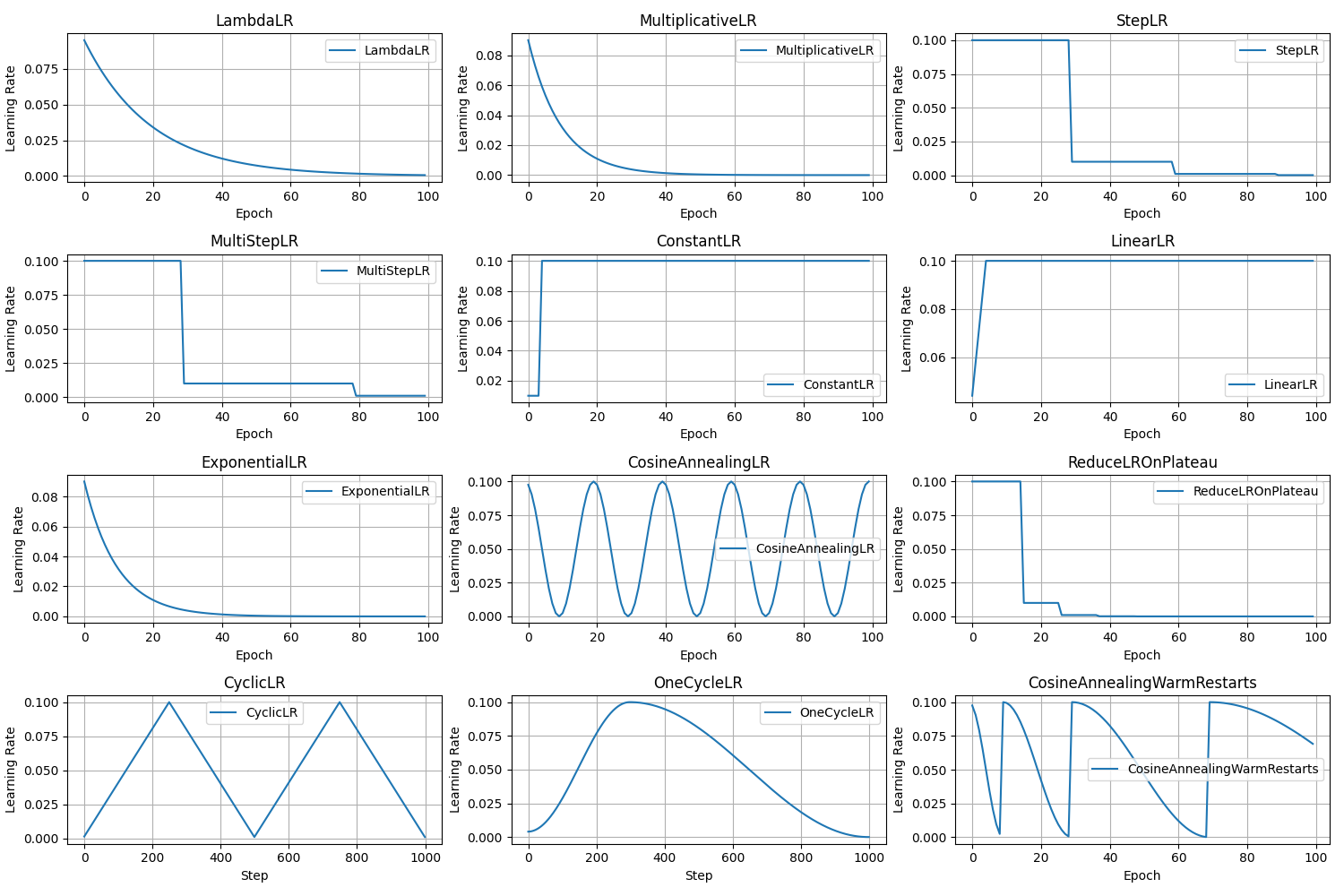
值得注意的是,在使用lr_scheduler过程中,一般使用套路为:
# 定义学习率变化方式
lr_scheduler = torch.optim.lr_scheduler.CosineAnnealingLR(optimizer, T_max= (page_layout_config.cos_warmup_t_max* len(train_dataloader)),eta_min= page_layout_config.cos_warmup_eta_min)
...
# 如果使用huggingface的并行训练框架
lr_scheduler = accelerator.prepare(lr_scheduler)
out = model(x)
loss = loss_function(out, label)
accelerator.backward(loss)
if accelerator.sync_gradients:accelerator.clip_grad_norm_(model.parameters(), 1.0)
optimizer.step()
lr_scheduler.step() # 更新策略是由讲究的,见下面括号中的描述
optimizer.zero_grad()
# 如果不使用框架
out = model(x)
loss = loss_function(out, label)
loss.backward()
optimizer.step()
lr_scheduler.step()
optimizer.zero_grad()
要获取学习率的当前值,可使用 scheduler.get_last_lr()[0]。不同调度器的更新方式存在差异,具体如下:1、基于步数的调度(再每一次dataloader处理之后都要进行更新):CyclicLR 和 OneCycleLR 直接根据训练步数(step)更新学习率,适合在每个 batch 后调用 scheduler.step()。2、基于指标的调度:ReduceLROnPlateau 根据验证指标(如损失或准确率)动态调整学习率,需在 scheduler.step(metrics) 中传入指标值。3、基于 epoch 的调度(在结束一个epoch后再去更新学习率):其他调度器(如 CosineAnnealingLR)通常基于 epoch 调整学习率。例如,CosineAnnealingLR(optimizer, T_max=10, eta_min=0) 以 10 个 epoch 为一个周期进行余弦退火调整。
参考
https://docs.pytorch.org/docs/stable/optim.html#how-to-adjust-learning-rate ↩︎