14-Oracle 23ai Vector Search 向量索引和混合索引-实操
一、Oracle 23ai支持的2种主要的向量索引类型:
1.1 内存中的邻居图向量索引 (In-Memory Neighbor Graph Vector Index)
HNSW(Hierarchical Navigable Small World :分层可导航小世界)索引 是 Oracle AI Vector Search 中唯一支持的内存邻居图向量索引类型。基于HNSW图算法,通过多层图结构加速搜索。
HNSW索引在23ai版本引入的新的内存结构:向量内存池(Vector Memory Pool)中创建;向量内存池(Vector Memory Pool)位于SGA中,Oracle通过 vector_memory_size参数控制这块内存的大小。Oracle 23 ai free目前的版本需要设置 vector_memory_size后,shutdown immediate ,startup
0. HNSW 索引原理详解
HNSW(Hierarchical Navigable Small World)是一种高效的高维向量近似最近邻搜索算法,其核心思想是通过构建多层图结构来加速相似性搜索。以下是其工作原理的深入解析:
1. 基础概念:小世界网络
- 核心特性:任意两个节点可通过少量边连接(类似社交网络中的"六度空间"理论)
- HNSW 创新点:将小世界特性分层实现,形成可导航的层级结构
-
2. 多层图结构构建
HNSW 构建一个由多层组成的图(Layer 0 到 Layer L):层级特性:- 高层(Layer L):节点稀少,长距离连接(快速导航)
- 底层(Layer 0):包含所有节点,密集连接(精确搜索)
- 节点进入规则:随机分配层级(概率随层级升高指数下降)
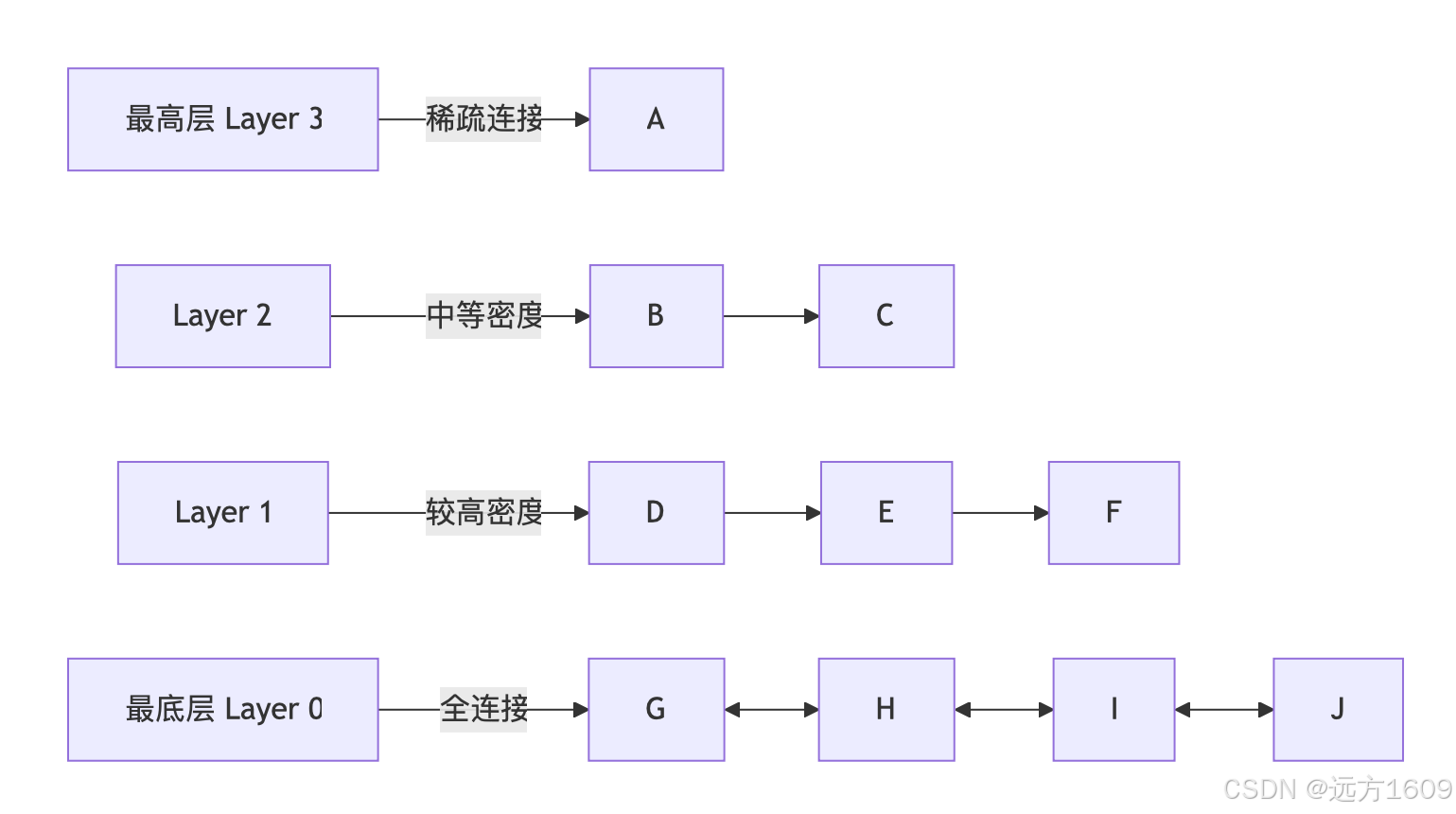
3. 搜索流程(查询向量 Q)
顶层导航(粗粒度):
- 从最高层随机节点开始
- 沿"长距离边"快速跳转到目标区域
逐层细化:
- 每下降一层,使用更密集的连接
- 逐步缩小搜索范围
底层精确搜索:
- 在 Layer 0 执行贪婪遍历
- 从上层确定的入口点开始
- 不断跳转到更近的邻居,直到找到局部最优
4. HNSW 高效特性
层级漏斗效应:
- 高层快速定位区域(减少 90%+ 搜索量)
- 底层精确定位目标
小世界特性:
- 平均路径长度:O(log N)
- 聚类系数高(相似节点紧密连接)
动态平衡:
- 插入/删除时自动重连最优邻居
- 保持图的导航性不变
5. Oracle 如何实现HNSW
内存优化:
- 全内存存储(SGA 的向量内存池)
- 通过 vector_memory_size 控制内存分配
参数控制:
CREATE VECTOR INDEX ... PARAMETERS (TYPE HNSW,NEIGHBORS 64, -- 每层最大邻居数 (M)EFCONSTRUCTION 500 -- 构建候选数
)1.2 磁盘上的邻居分区矢量索引 (Neighbor Partition Vector Index)
IVF(Inverted File Flat :倒排文件扁平) 索引是一种基于分区的向量索引技术,是 Oracle AI Vector Search 中唯一支持的邻居分区向量索引类型。IVF索引在磁盘上创建,并且和其他数据块一样可以缓存在buffer cache。
0. IVF 索引原理深度解析
IVF(Inverted File Flat)是一种基于空间划分的高效向量索引方法,通过分区聚类技术实现大规模向量数据的快速近似最近邻搜索
1. 空间分区:构建向量空间地图
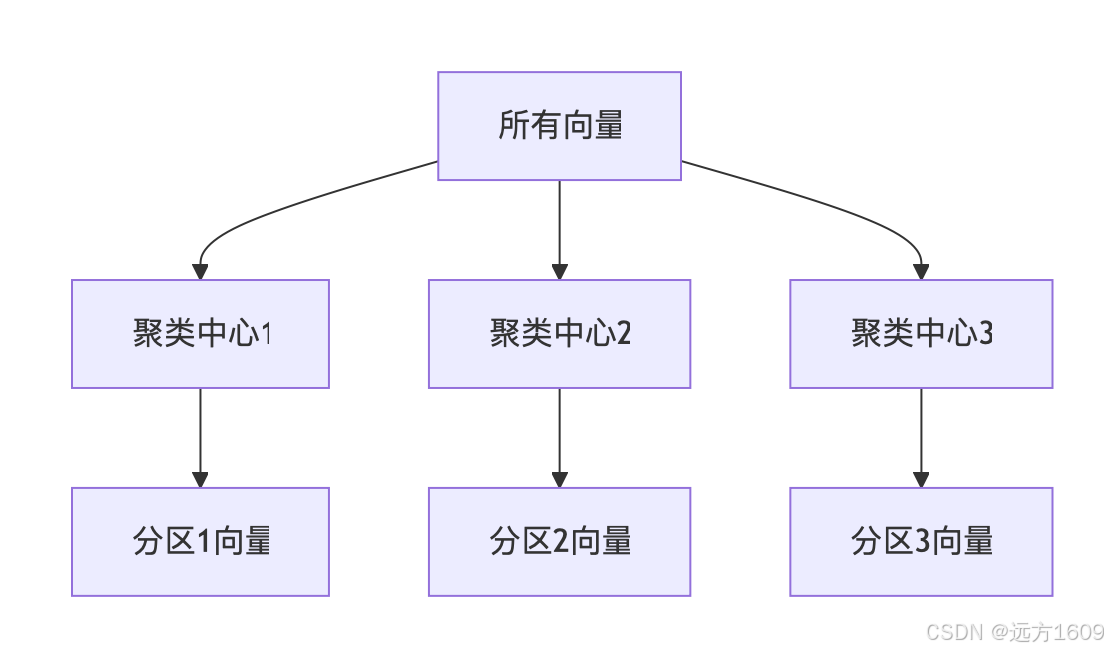
关键步骤:
- 使用 K-means 算法将 N 个向量聚类成 K 个分区(K << N)
- 每个分区由聚类中心(质心)代表
- 构建倒排索引:中心点 → 所属向量列表
Oracle 参数控制:
PARAMETERS (TYPE IVF,NEIGHBOR PARTITIONS 1000, -- 分区数KSAMPLES_PER_PARTITION 1000 -- 聚类采样数
)2. 搜索流程:三阶段过滤
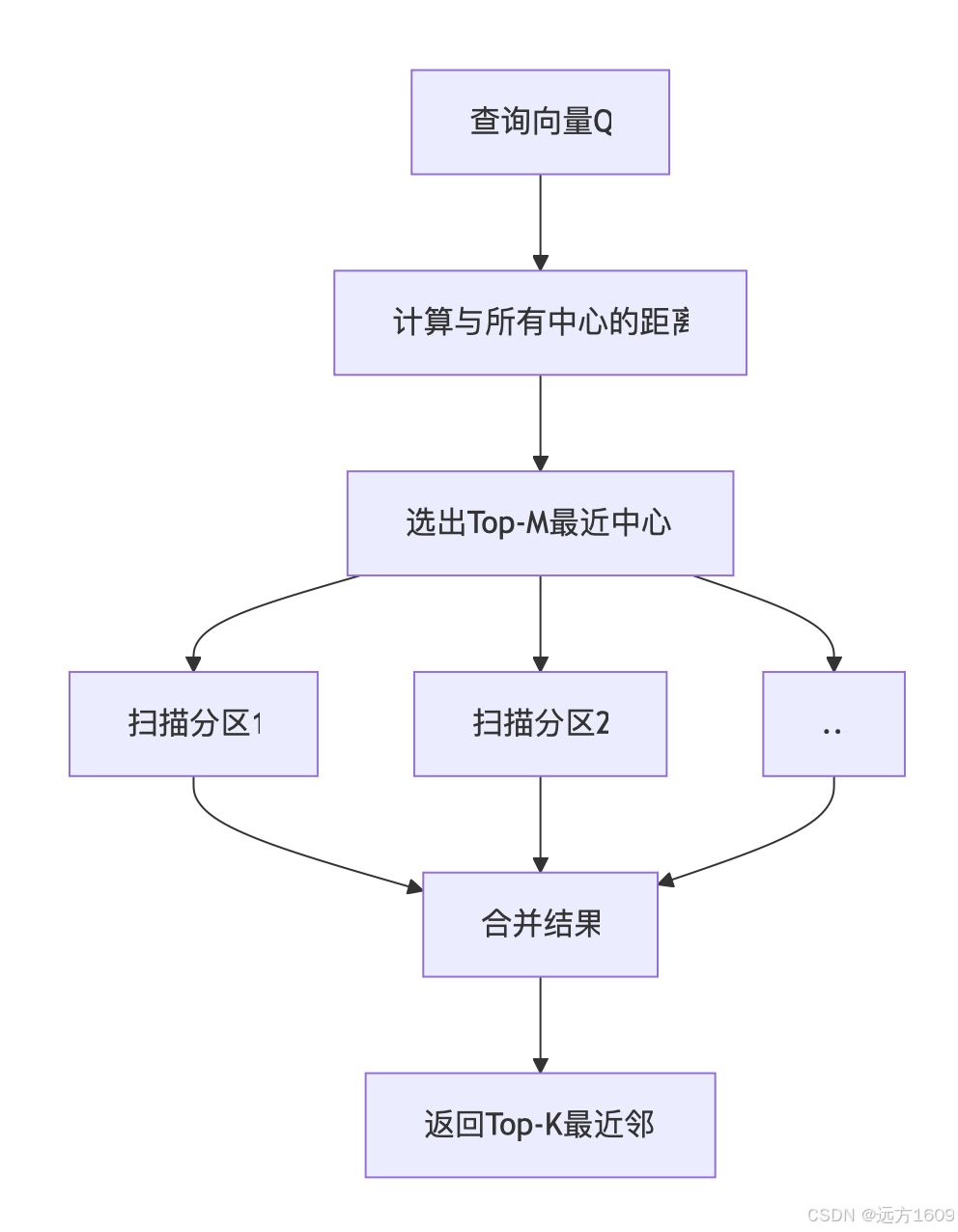
粗搜索(Coarse Search):
- 计算查询向量与所有聚类中心的距离
- 选择距离最近的 M 个分区(M << K)
- Oracle 优化:使用 VECTOR_IVF_PROBE 提示控制 M 值
精细搜索(Fine Search):
- 在选中的 M 个分区内进行线性扫描
- 计算查询向量与分区内所有向量的距离
结果合并:
- 从 M 个分区中收集候选向量
- 按距离排序返回 Top-K 结果
4. Oracle 如何实现IVF
磁盘存储结构: 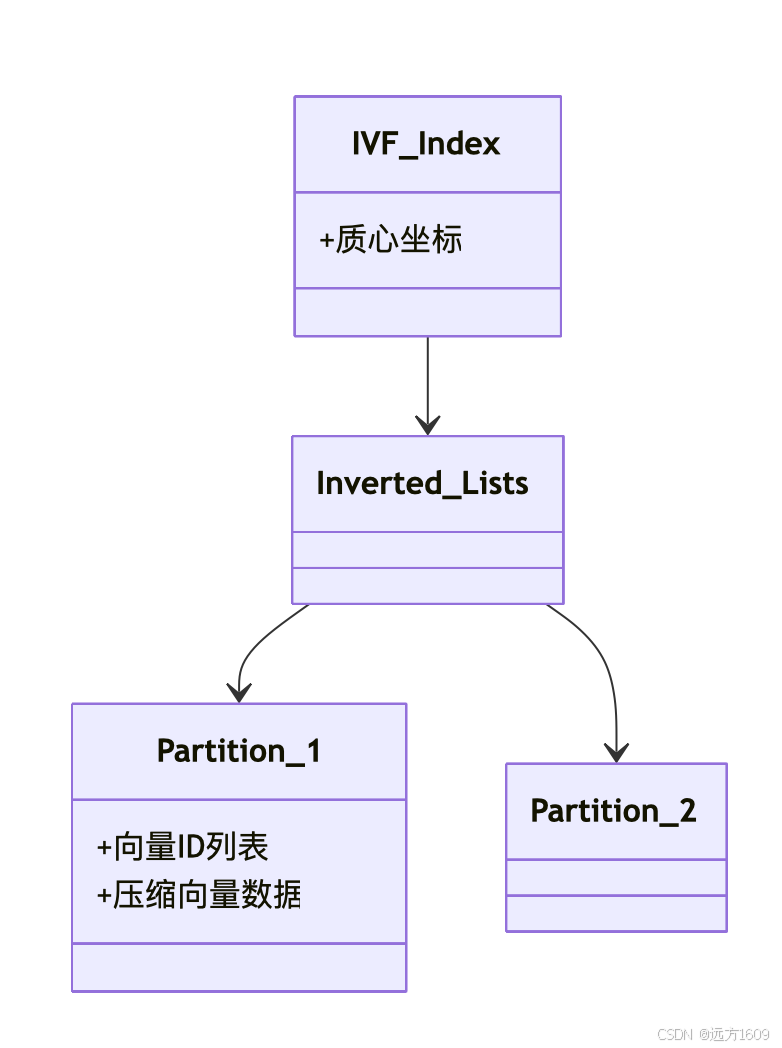
智能缓存机制:
- 热分区自动缓存在 Buffer Cache
- 冷分区按需从磁盘加载
- 通过 DBMS_VECTOR 包预加载:
EXEC DBMS_VECTOR.LOAD_IVF_PARTITIONS('idx_ivf', 50); 动态再平衡 :
- 定期重新计算聚类中心
- 增量添加新向量时自动调整分区
- 重建索引维护窗口:
ALTER INDEX idx_ivf REBUILD PARAMETERS('NEIGHBOR_PARTITIONS 2000');
1.3 Oracle 23ai支持的向量索引的特性:
向量索引
- 加速高维向量的相似性搜索(如欧氏距离、余弦相似度)
- 两种类型:HNSW(内存图结构)和 IVF(磁盘分区结构)
混合向量索引
结合向量搜索与文本搜索(如 DBMS_VECTOR_CHAIN 包),支持多模态查询(文本+向量)
1.4 索引选择
在 Oracle 中,HNSW 特别适合需要亚秒级响应的场景(如:实时推荐系统), IVF 更适合超大规模数据集(10亿+向量)。在 Oracle 中处理 >1亿向量时,IVF 相比 HNSW 可降低 5-10 倍内存占用,同时保持 90%+ 召回率。通过调整 NEIGHBOR_PARTITIONS 和 VECTOR_IVF_PROBE 可实现精度与速度的平衡。
二、创建向量索引的实操过程
1. HNSW 索引
实际运行,其中--参数解释:
CREATE VECTOR INDEX idx_hnsw ON fashion_items2 (FEATURES)ORGANIZATION INMEMORY NEIGHBOR GRAPHDISTANCE COSINE -- 相似度计算方式(余弦)WITH TARGET ACCURACY 95 -- 目标精度%PARAMETERS (TYPE HNSW,NEIGHBORS 64, -- 每层最大邻居数(1-2048)EFCONSTRUCTION 500 -- 构建候选数(1-65535))PARALLEL 4; -- 并行构建 特点:
- - 存储在 SGA 的向量内存池(vector_memory_size 控制大小)
- - 低延迟查询(毫秒级响应)
- - 适用场景:实时推荐系统、小数据集高速搜索
CREATE VECTOR INDEX idx_hnsw ON fashion_items2 (FEATURES) ORGANIZATION INMEMORY NEIGHBOR GRAPH DISTANCE COSINE WITH TARGET ACCURACY 952 PARAMETERS (3 TYPE HNSW,4 NEIGHBORS 64,5 EFCONSTRUCTION 5006 )7 PARALLEL 4;索引已创建。SYS@FREE> DESC fashion_items2名称 是否为空? 类型----------------------------------------------------------------- -------- --------------------------------------------ITEM_ID NUMBERFEATURES VECTOR(*, *, DENSE)SYS@FREE> 特点:
- 存储在磁盘(可缓存在 Buffer Cache)
- 高吞吐量,适合亿级向量
- 适用场景:大规模图像检索、生物特征库搜索
3. 混合向量索引实操
结合文本搜索与向量搜索的跨模态查询:
-- 创建包含文本和向量的表
CREATE TABLE hybrid_data (id NUMBER PRIMARY KEY,description VARCHAR2(4000),text_embedding VECTOR,image_embedding VECTOR
);-- 创建文本索引
CREATE INDEX idx_text ON hybrid_data (description) INDEXTYPE IS CTXSYS.CONTEXT;-- 创建向量索引
CREATE VECTOR INDEX idx_vec ON hybrid_data (image_embedding)ORGANIZATION INMEMORY NEIGHBOR GRAPHDISTANCE COSINE;-- 混合搜索:文本匹配 + 图像相似度
SELECT id, description
FROM hybrid_data
WHERE CONTAINS(description, '自然风光') > 0 -- 文本搜索AND VECTOR_DISTANCE(image_embedding, :query_vec, COSINE) < 0.2 -- 向量搜索
ORDER BY SCORE(1) DESC;
SP2-0552: 未声明绑定变量 "QUERY_VEC"。需要设定变量
帮助:https://docs.oracle.com/error-help/db/sp2-0552/
SYS@FREE>