自主学习-《WebDancer:Towards Autonomous Information Seeking Agency》
代码:https://github.com/Alibaba-NLP/WebAgent
相关工作:
ChatGPT DeepResearch: https://cdn.openai.com/deep-research-system-card.pdfGrok DeepSearch: https://x.ai/news/grok-31. 直接调优prompt让LLM完成复杂任务;2. 将思考和tool调用,训练至LLM里,让LLM学会什么时候思考什么时候调用什么tool;现状痛点:训练数据集、测试数据集,都太简单了,和真实复杂任务中的action轨迹的难度相差较大。本文,将reasoning、action、observation组成的序列,喂给模型进行训练(SFT+RL),让其学会遇到任务后该用什么动作序列来解决任务。
QA数据:现成的QA数据集大多是难度简单的,只需1轮~3轮就能解决的问题。有难度的数据集,量又太少。例如:GAIA,WebWalkerQA,BrowseComp。因此,本文选择自己合成这些高难度的QA数据集。目标是构造这样的QA数据集:1. 多样性;2.高难度,需要较 多轮思考、搜索才能回答的Q。1. CRAWL QA抓取知识型网站( arxiv, github, wiki),递归抓取其网页。使用GPT-4o生成QA。复用论文《A complex, natural, and multilingual dataset for end-to-end question answering》的方法,通过in-context learning(也就是few-shot examples),让LLM生成指定类别的问题(COUNT , MULTI-HOP , INTERSECTION)2. E2H QA从初始的简单问题Q1中,找到词组E1,调用搜索引擎查询和E1相关的知识C1,输入大模型得到把E1用知识C1进行扩展后的问题Q2,依次迭代,扩展到复杂的Q。还是用GPT-4o做扩展。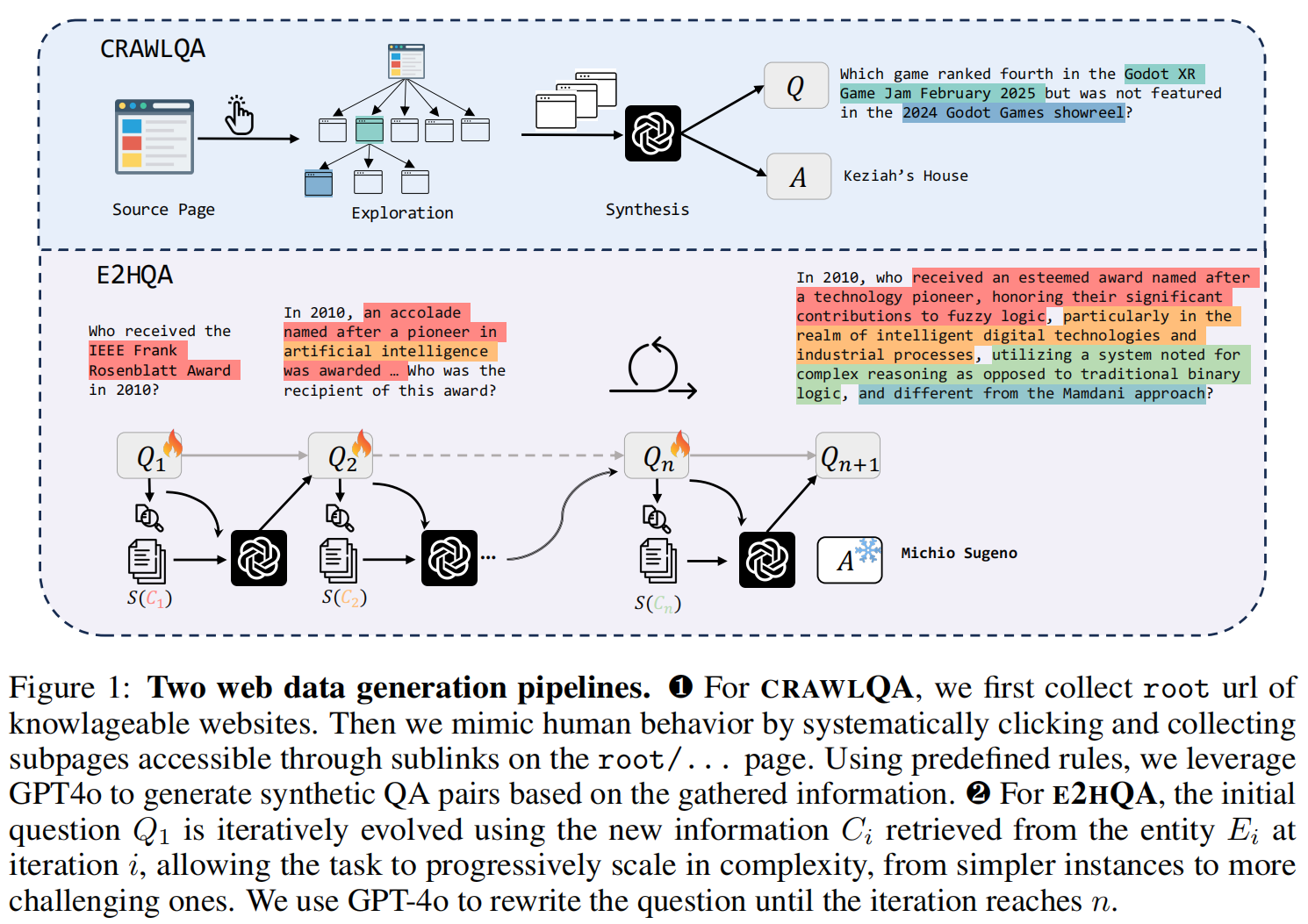 如上图,Q1里的红色Entiry,在Q2里被展开为红色和黄色。Q2里的黄色Entiry,在Q3里被展开为黄色和其他颜色。。。
如上图,Q1里的红色Entiry,在Q2里被展开为红色和黄色。Q2里的黄色Entiry,在Q3里被展开为黄色和其他颜色。。。
ReAct trajectory,由Thought-Action-Observation的链,迭代多次构成。
展开为:
。前者是action名称,后者是参数。
。search是用query(和filter_year)来搜索。visit是去访问input的url_link(和goal)拿到网页内容。answer是输出答案并结束。
observation里:search的o是top-10的网页title和摘要。visit的o是该网页的summary(用LLM总结得到的)
thought和action一同生成:
这个trajectory很关键,里面包含各种:high-level workflow planning, self-reflection, information extraction, adaptive action planning, and accurate action (tool usage)
长的CoT链的训练数据,对模型效果提升有帮助。所以,用了2种方式:
1. 短CoT链制作,使用GPT-4o来一步一步生成。
2. 长CoT链制作,使用阿里自家的LRM模型QwQ-Plus来一步一步生成。(该模型的训练数据里只有action和observation,没有thought,所以这里不将thought进入到该模型输入里;该模型输出里有"reasoning_content"字段,将其作为thought加入最终的结果链里)
过滤:
1. valid: 过滤掉格式不符的CoT链;
2. correct: 过滤掉CoT最终回复结果和QA中的A不相等的链;用GPT-4o来做裁判判断是否相等;
3. quality: 过滤掉输出里一步里包含不止一个action的链;使用LLM进行3个过滤:1. 信息不冗余;2.目标对齐;3.逻辑推理;4.正确性;
经过这些过滤,有的QA是有valid trajectory的;有的QA没有valid trajectory(也会被后续用到)。
Train
注意:现在LLM的标签体系,主流是<think>、<tool_call>、<tool_response>、<answer>这种!
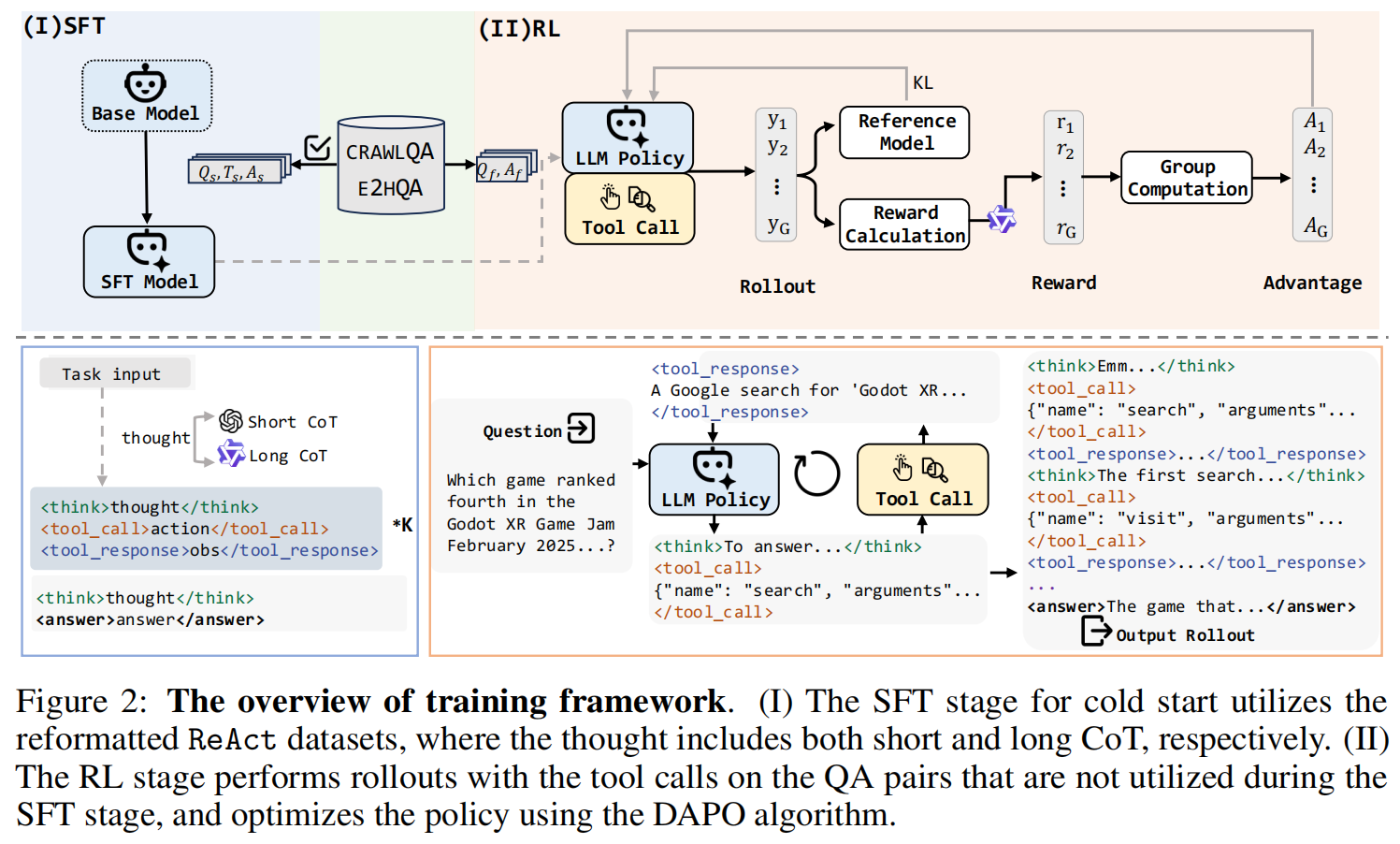
(I) SFT
SFT阶段是作为RL的冷启动阶段。
SFT作为冷启动起到的作用:
The cold start enhances the model’s capability to couple multiple reasoning and action steps, teaching it a behavioral paradigm of alternating reasoning with action, while preserving its original reasoning capabilities as much as possible.(让模型学会推理和调工具轮流进行这个pattern,同事保留模型原有的推理能力)复用前人经验:observation(即tool的输出结果)不加入到loss里。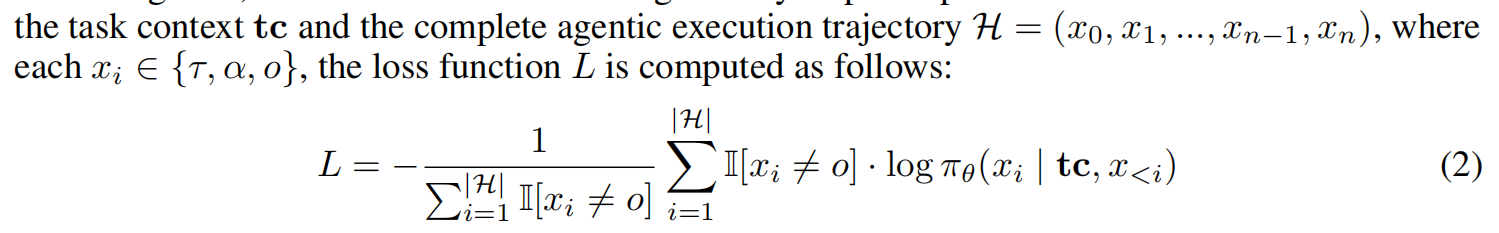
(Ⅱ) RL注意:RL所需要的数据,只要是QA就行,不需要带有trajectory。因为他自己生成trajectory,只需要Answer来做reward用即可。所以,trajectory有效性过滤那里,被淘汰掉的QA,仍可以在这里被使用。用的DAPO算法。最大化目标函数: G是采样多少条trajectory。对于G个r全是0或者全是1的i,因为G个trajectory之间没有相对优势了,所以扔弃这些。
G是采样多少条trajectory。对于G个r全是0或者全是1的i,因为G个trajectory之间没有相对优势了,所以扔弃这些。 r似乎是和base model的差异reward,R以答对答错为主的reward:
r似乎是和base model的差异reward,R以答对答错为主的reward: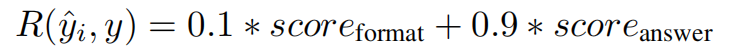
score(format),是trajectory格式正确,且<tool_call>内部的json格式正确。
score(answer),是LLM做出的判断,为0/1值。
pure SFT-based agents often exhibit limited generalization performance