SQL Server 如何实现高可用和读写分离技术架构

关键词: SQL Server 高可用、读写分离、Always On 可用性组、数据库架构、故障转移
📚 文章目录
- 1. 前言:为什么需要高可用?
- 2. SQL Server 高可用方案概览
- 3. Always On 可用性组:现代化高可用方案
- 4. 读写分离架构设计
- 5. 实战部署指南
- 6. 性能优化与监控
- 7. 总结:选择适合的方案
1. 前言:为什么需要高可用?
想象一下,你的电商网站在双十一当天突然数据库挂了,用户无法下单,老板的脸色比锅底还黑… 这时候你就会深刻理解什么叫"高可用性"了!😅
现代企业对数据库的要求越来越高:
- 99.9% 可用性:每年停机时间不超过 8.76 小时
- 秒级故障恢复:用户几乎感知不到故障
- 读写分离:缓解主库压力,提升查询性能
2. SQL Server 高可用方案概览
SQL Server 提供了多种高可用方案,各有特色:

方案对比
| 方案 | 可用性 | 复杂度 | 读写分离 | 推荐指数 |
|---|---|---|---|---|
| Always On 可用性组 | 99.99% | 中等 | ✅ | ⭐⭐⭐⭐⭐ |
| 故障转移集群 | 99.9% | 高 | ❌ | ⭐⭐⭐ |
| 数据库镜像 | 99.9% | 低 | 有限 | ⭐⭐ (已弃用) |
| 日志传送 | 99% | 低 | ✅ | ⭐⭐ |
3. Always On 可用性组:现代化高可用方案
Always On 可用性组是微软推荐的现代化高可用方案,它就像是给你的数据库买了一份"全险"。
核心特性
- 多副本同步:支持最多 9 个副本
- 自动故障转移:主副本故障时自动切换
- 读写分离:辅助副本可处理只读查询
- 灵活的同步模式:同步/异步可选
架构图
4. 读写分离架构设计
读写分离的核心思想是"各司其职":主库专心处理写操作,从库负责查询,就像餐厅里主厨负责炒菜,服务员负责上菜一样。
分离策略
连接字符串配置
写操作连接(指向主副本):
Server=AG-Listener,1433;Database=MyDB;Integrated Security=true;
读操作连接(指向辅助副本):
Server=AG-Listener,1433;Database=MyDB;Integrated Security=true;
ApplicationIntent=ReadOnly;
5. 实战部署指南
5.1 环境准备
首先确保你的环境满足以下条件(这些是硬性要求,不满足就像开车不系安全带):
- Windows Server 故障转移集群 (WSFC)
- SQL Server Enterprise 版本(Standard 版本功能受限)
- 至少 3 个节点(奇数个节点避免脑裂)
5.2 部署步骤
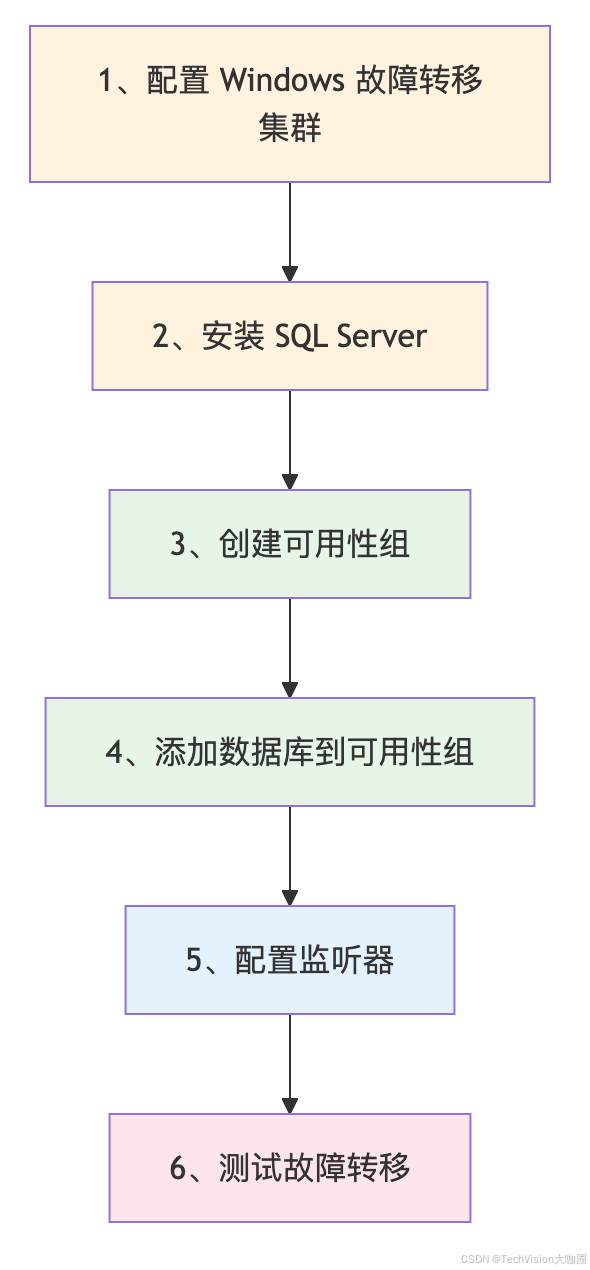
5.3 关键配置
创建可用性组的 T-SQL 示例:
-- 创建可用性组
CREATE AVAILABILITY GROUP [MyAG]
WITH (AUTOMATED_BACKUP_PREFERENCE = SECONDARY,DB_FAILOVER = ON,DTC_SUPPORT = NONE
)
FOR DATABASE [MyDatabase]
REPLICA ON 'SQL01' WITH (ENDPOINT_URL = 'TCP://SQL01.domain.com:5022',AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,FAILOVER_MODE = AUTOMATIC,SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY)),'SQL02' WITH (ENDPOINT_URL = 'TCP://SQL02.domain.com:5022',AVAILABILITY_MODE = SYNCHRONOUS_COMMIT,FAILOVER_MODE = AUTOMATIC,SECONDARY_ROLE(ALLOW_CONNECTIONS = READ_ONLY));
6. 性能优化与监控
6.1 性能调优要点
同步模式选择:
- 同步提交:数据一致性高,但性能略低
- 异步提交:性能好,但可能丢失少量数据
网络优化:
- 使用专用网络进行副本间通信
- 适当的网络带宽(建议 10Gbps 以上)
6.2 监控指标
关键监控 SQL:
-- 查看可用性组状态
SELECT ag.name AS AvailabilityGroup,r.replica_server_name,r.role_desc,rs.synchronization_state_desc,rs.synchronization_health_desc
FROM sys.availability_groups ag
JOIN sys.availability_replicas r ON ag.group_id = r.group_id
JOIN sys.dm_hadr_availability_replica_states rs ON r.replica_id = rs.replica_id;
7. 总结:选择适合的方案
选择高可用方案就像选择交通工具,要根据实际需求来:
方案选择建议
| 业务场景 | 推荐方案 | 理由 |
|---|---|---|
| 大型电商/金融 | Always On 可用性组 | 需要极高可用性和读写分离 |
| 中小企业 | Always On + 异步副本 | 成本与可用性平衡 |
| 简单应用 | 日志传送 | 实现简单,成本较低 |
最佳实践总结
- 规划先行:根据 RTO/RPO 要求选择合适方案
- 网络为王:确保副本间网络稳定高速
- 监控保障:建立完善的监控告警体系
- 定期演练:不要等到故障发生才测试恢复流程
记住,高可用架构不是一劳永逸的,需要持续的维护和优化。就像健身一样,三分靠练,七分靠坚持!💪
原创文章,转载请注明出处 📝