selenium-自动更新谷歌浏览器驱动
1、简介
selenium最初是一个自动化测试工具,而爬虫中使用它主要是为了解决requests无法直接执行JavaScript代码的问题,因为有些网页数据是通过JavaScript动态加载的。selenium本质是通过驱动浏览器,完全模拟浏览器的操作,比如输入、点击、跳转等,来拿到网页渲染之后的结果,可以支持多种浏览器。
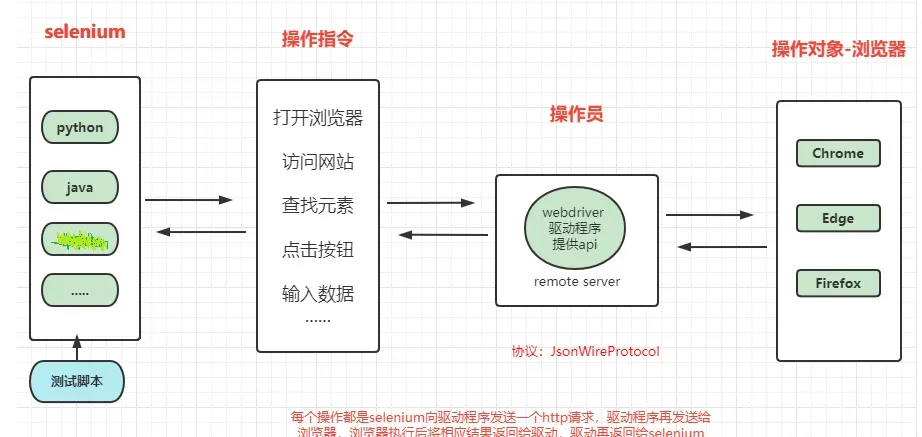 2、环境安装
2、环境安装
2.1、安装selenium库
pip install selenium2.2、安装浏览器驱动
我一般使用谷歌浏览器,因为谷歌浏览器的检查功能很好用。
1、查看本地Chrome浏览器版本
在浏览器的地址栏输入chrome://version,即可查看浏览器版本号
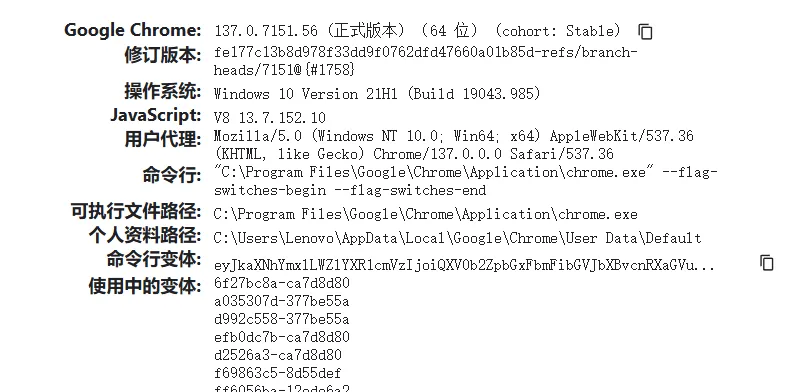
2、根据浏览器版本号下载对应的驱动程序
驱动程序下载地址:ChromeDriver 下载 - 最新版本 | ChromeDriver 驱动
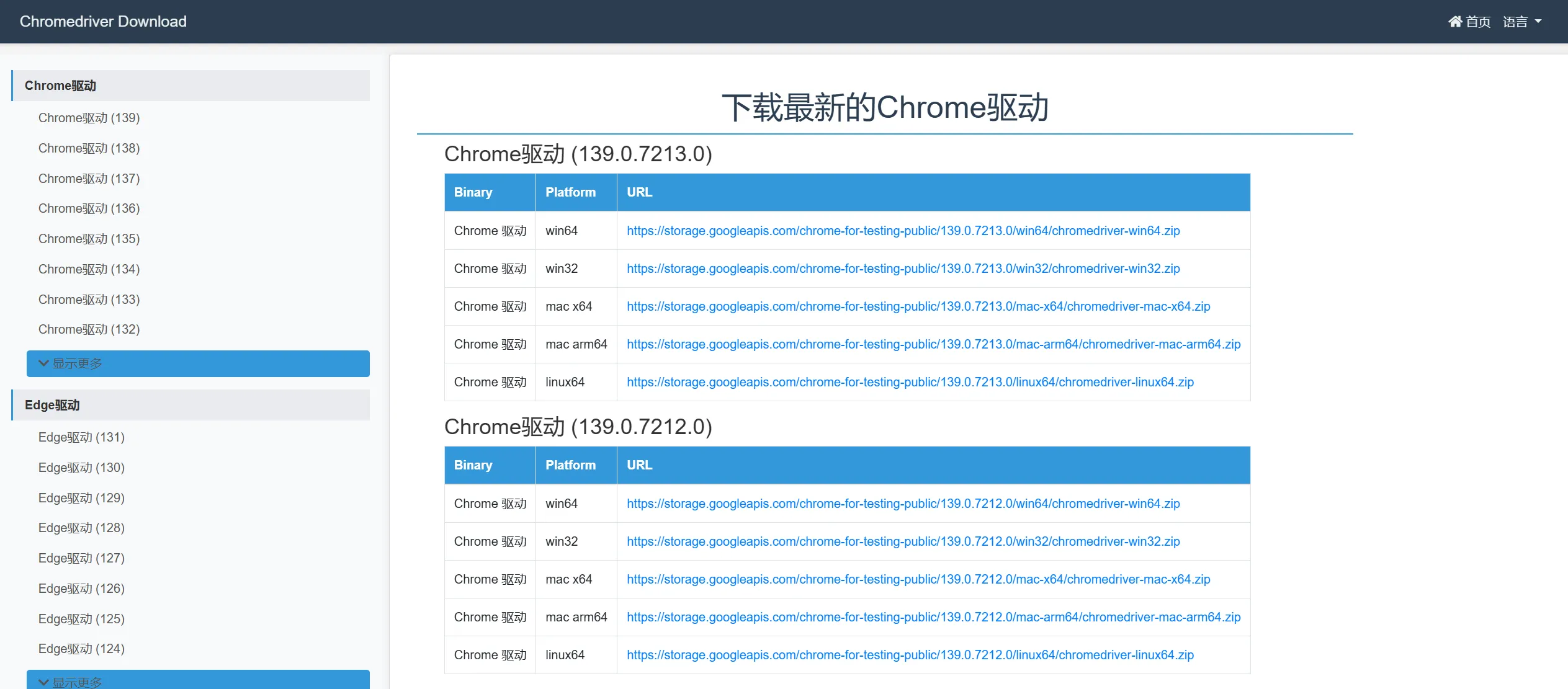
下载压缩包后解压到对应的文件夹
2.3、测试
运行下面的python脚本,观察到谷歌浏览器自动打开并且访问百度首页停留10s退出即表示selenium环境安装完成。
import timefrom selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Servicechrome_options = Options()
# 设置浏览器窗口最大化
chrome_options.add_argument("--start-maximized")
# 设置驱动路径
chromedriver_path = '你的chromedriver.exe文件所在的路径'
service = Service(executable_path=chromedriver_path)driver = webdriver.Chrome(service=service, options=chrome_options)url = 'https://www.baidu.com/'driver.get(url)time.sleep(10)driver.quit()3、自动更新谷歌浏览器驱动
selenium程序的正确运行需要谷歌浏览器和浏览器驱动版本号匹配,由于谷歌浏览器会自动更新导致需要经常手动更换浏览器驱动。
我在网上搜索尝试了很多关闭谷歌浏览器自动更新的办法,一直没有起作用。我们从另一个角度:编写程序自动更新浏览器驱动来解决需要手动更新的问题。
3.1、检查当前谷歌浏览器和浏览器驱动是否匹配
def test_chrome_driver():# 当前谷歌浏览器的驱动路径driver_path = '你的chromedriver.exe文件所在的路径'# 初始化chrome浏览器的选项chrome_options = Options()# 设置浏览器窗口最大化chrome_options.add_argument("--start-maximized")service = Service(executable_path=driver_path)driver = Nonetry:# 创建webdriver对象,传入配置好的options和servicedriver = webdriver.Chrome(service=service, options=chrome_options)url = "https://www.baidu.com/"driver.get(url)print("当前谷歌浏览器版本号和驱动版本号匹配")except Exception as e:# 使用正则表达式从异常信息中提取谷歌浏览器版本号pattern = r"Current browser version is (\d+\.\d+\.\d+\.\d+)"match = re.search(pattern, str(e))if match:browser_version = match.group(1)print(f"当前谷歌浏览器版本号和驱动版本号不匹配,谷歌浏览器版本号为:{browser_version}")return browser_versionfinally:if driver:driver.quit()匹配运行结果:

不匹配运行结果:

3.2、自动下载对应的谷歌浏览器驱动程序
3.2.1、方法一
解析ChromeDriver 下载 - 最新版本 | ChromeDriver 驱动,找到对应版本的驱动程序下载地址
1、浏览器版本号和驱动版本号不一定完全相同,一般版本号前三部分相同即可。与浏览器版本号前三部分相同的驱动一般有多个,为了保险起见,我们通过一个列表存储可能匹配的驱动程序下载位置。
2、该网站提供适用于不同系统的驱动程序下载地址,我需要的是后缀为"chromedriver-win64.zip"的下载地址,你可以根据需求自行修改。因为可以下载的驱动版本号有多个,所以可以下载的地址也有多个,保存到一个列表中。
def find_chromedriver_url(browser_version):parts1 = browser_version.split('.')url = "https://www.chromedriverdownload.net/zh/"headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'}response = requests.get(url=url,headers=headers)# 检查请求是否成功if response.status_code == 200:tree = etree.HTML(response.text)# 存储满足浏览器版本号的驱动下标matching_indices = []chromedriver_download_url = []try:h2_div_list = tree.xpath('.//h2[@class="h3"]/text()')for index,h2_item in enumerate(h2_div_list):chromedriver_version = h2_itemmatch_version = re.search(r'\((\d+\.\d+\.\d+\.\d+)\)', chromedriver_version)if match_version:chromedriver_version = match_version.group(1) # 获取匹配到的版本号parts2 = chromedriver_version.split('.')# 比较前三个部分if parts1[:3] == parts2[:3]:matching_indices.append(index) # 如果满足条件,将索引添加到结果列表中for index in matching_indices:chromedriver_table = tree.xpath('/html/body//div[@class="row"]//div[@class="manual-article"]/div[@class="article-content"]')[0]target_table = chromedriver_table.xpath(f'./table[{index+1}]')[0]chromedriver_tr_list = target_table.xpath('./tbody/tr')for chromedriver_tr in chromedriver_tr_list:if "chromedriver-win64.zip" in chromedriver_tr.xpath('.//text()')[5]:chromedriver_download_url.append(chromedriver_tr.xpath('.//text()')[5])return chromedriver_download_urlexcept Exception as e:print(f"程序发生了异常:{e}")return Noneelse:print("请求chromedriver下载链接页失败")3、解压到本地指定文件夹
def download_chromedriver(chromedriver_download_url,browser_version):if chromedriver_download_url:for url in chromedriver_download_url:# 指定保存压缩文件的本地路径zip_file_path = f"chromedriver{browser_version}-win64.zip"# 指定解压后的文件夹路径extract_folder_path = f"chromedriver{browser_version}"try:# 发起请求下载文件headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'}response = requests.get(url=url,headers=headers)response.raise_for_status() # 检查请求是否成功# 将下载的文件写入本地with open(zip_file_path, "wb") as file:file.write(response.content)# 创建解压文件夹(如果不存在)if not os.path.exists(extract_folder_path):os.makedirs(extract_folder_path)# 解压文件with zipfile.ZipFile(zip_file_path, "r") as zip_ref:zip_ref.extractall(extract_folder_path)# 获取解压文件夹的子文件夹subfolders = [f for f in os.listdir(extract_folder_path) ifos.path.isdir(os.path.join(extract_folder_path, f))]# 获取子文件夹的路径subfolder_path = os.path.join(extract_folder_path, subfolders[0])# 构造chromedriver.exe的绝对路径chromedriver_path = os.path.join(subfolder_path, "chromedriver.exe")# 检查chromedriver.exe文件是否存在if os.path.exists(chromedriver_path):print("chromedriver.exe的绝对路径为:", chromedriver_path)else:print("子文件夹下没有找到chromedriver.exe文件")print(f"文件已成功下载并解压到 {extract_folder_path} 文件夹中,路径为{chromedriver_path}。")break # 有一个压缩包下载成功即跳出循环except requests.exceptions.RequestException as e:print(f"下载文件时出错:{e}")print("请检查网页链接的合法性,适当重试。")except zipfile.BadZipFile:print("下载的文件不是有效的zip文件。")print("请检查网页链接的合法性,适当重试。")except Exception as e:print(f"发生错误:{e}")之后将chromedriver_path写入到项目的配置文件中,提供给使用selenium的脚本读取。
3.2.2、方法二
使用webdriver_manager,它的核心功能是自动检测已安装的浏览器版本,并下载匹配的驱动程序。
1、安装方法
pip install webdriver-manager2、基本使用
from webdriver_manager.chrome import ChromeDriverManager# 安装 ChromeDriver
driver_path = ChromeDriverManager().install()print(driver_path)
此时下载的浏览器驱动、下载位置均为默认,一般情况下直接在selenium创建driver对象时使用,但是会拖慢程序运行速度。
from webdriver_manager.chrome import ChromeDriverManager
from selenium import webdriver# 自动下载并配置ChromeDriver
driver = webdriver.Chrome(ChromeDriverManager().install())# 使用driver进行测试
driver.get("https://www.baidu.com/")
print(driver.title)
driver.quit()