AI智能推荐实战之RunnableParallel并行链
导读:在现代AI应用开发中,如何高效处理多维度数据分析始终是开发者面临的核心挑战。当您需要同时进行情感分析、关键词提取和实体识别,或者要对比多个AI模型的输出结果时,传统的串行处理方式往往效率低下。
本文将深入解析LangChain框架中的RunnableParallel组件,这一专为并行任务执行而设计的核心工具。文章不仅详细阐述了RunnableParallel的工作原理和自动转换机制,更重要的是通过实际案例展示了如何将原本需要累计6秒的三个任务压缩至2秒内完成。
您将了解到RunnableParallel如何实现统一输入分发、类型安全校验等关键特性,以及在数据并行处理、多模型对比系统和智能文档分析等实际场景中的应用策略。文章特别提供了一个完整的实战案例,演示同时生成城市景点推荐和相关书籍推荐的具体实现过程。
简介
RunnableParallel是LangChain框架中的核心组件,专门用于实现并行执行多个Runnable任务的功能。本文将深入探讨RunnableParallel的原理、特性以及实际应用场景。
RunnableParallel 核心概念
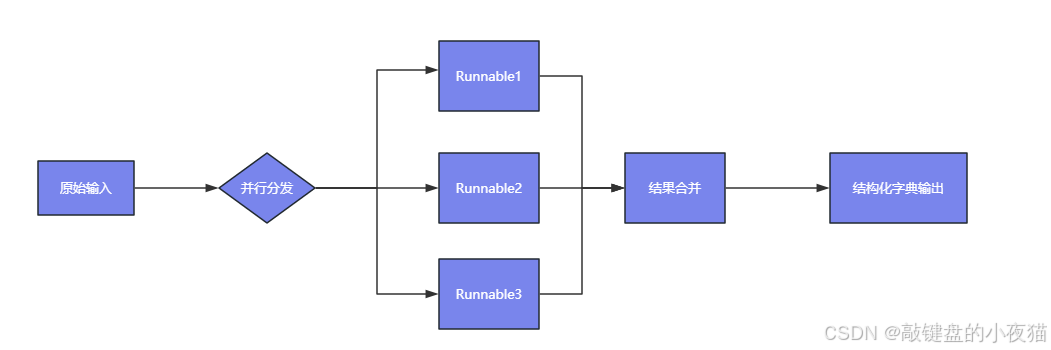
基本定义
RunnableParallel是一个容器类,能够并行执行多个Runnable组件,并将结果合并为一个字典结构。字典的键为子链名称,值为对应的输出结果。
class RunnableParallel(Runnable[Input, Dict[str, Any]]):"""并行执行多个Runnable的容器类输出结果为字典结构:{key1: result1, key2: result2...}"""
自动转换机制
在LCEL(LangChain Expression Language)链式调用中,字典结构会自动转换为RunnableParallel实例,以下两种写法在功能上完全等价:
显式使用RunnableParallel:
multi_retrieval_chain = (RunnableParallel({"context1": retriever1, # 数据源一"context2": retriever2, # 数据源二"question": RunnablePassthrough()})| prompt_template| llm| outputParser
)
隐式转换(推荐写法):
multi_retrieval_chain = ({"context1": retriever1, # 数据源一"context2": retriever2, # 数据源二"question": RunnablePassthrough()}| prompt_template| llm| outputParser
)
核心特性
RunnableParallel具备以下重要特性:
| 特性 | 说明 | 示例 |
|---|---|---|
| 并行执行 | 所有子Runnable同时运行,提升处理效率 | 3个任务耗时2秒(而非累加的6秒) |
| 类型安全 | 强制校验输入输出类型,确保数据一致性 | 自动检测字典字段类型 |
| 统一输入 | 所有子链接收相同的输入参数 | 一个输入源分发到多个处理器 |
API 使用方法
构造函数
from langchain_core.runnables import RunnableParallelrunnable = RunnableParallel(key1=chain1,key2=chain2
)
构造函数的核心原则是所有子链都会接收相同的输入数据,这使得RunnableParallel特别适合需要对同一数据进行多维度处理的场景。
应用场景
数据并行处理器
同时处理多个数据流,实现高效的数据处理管道:
analysis_chain = RunnableParallel({"sentiment": sentiment_analyzer, # 情感分析"keywords": keyword_extractor, # 关键词提取"entities": ner_recognizer # 命名实体识别
})
多模型对比系统
并行调用多个AI模型,便于性能比较和结果验证:
model_comparison = RunnableParallel({"gpt4": gpt4_chain,"claude": claude_chain,"gemini": gemini_chain
})
智能文档处理系统
对文档进行多维度分析,生成全面的处理结果:
document_analyzer = RunnableParallel({"summary": summary_chain, # 摘要生成"toc": toc_generator, # 目录提取"stats": RunnableLambda(lambda doc: {"char_count": len(doc),"page_count": doc.count("PAGE_BREAK") + 1})
})# 处理200页PDF文本
analysis_result = document_analyzer.invoke(pdf_text)
案例实战:并行生成景点与书籍推荐
场景描述
本案例演示如何使用RunnableParallel同时生成指定城市的景点推荐和相关书籍推荐,展现并行处理的实际应用价值。
完整代码实现
from langchain_core.runnables import RunnableParallel
from langchain_core.prompts import ChatPromptTemplate
from langchain_openai import ChatOpenAI
from langchain_core.output_parsers import JsonOutputParser# 定义模型
model = ChatOpenAI(model_name="qwen-plus",base_url="https://dashscope.aliyuncs.com/compatible-mode/v1",api_key="sk-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx",temperature=0.7
)# 构建解析器
parser = JsonOutputParser()# 景点推荐提示模板
prompt_attractions = ChatPromptTemplate.from_template("""
列出{city}的{num}个景点。返回 JSON 格式:
{{"num": "编号","city": "城市","introduce": "景点介绍"
}}
""")# 书籍推荐提示模板
prompt_books = ChatPromptTemplate.from_template("""
列出{city}相关的{num}本书,返回 JSON 格式:
{{"num": "编号", "city": "城市","introduce": "书籍介绍"
}}
""")# 构建子链
chain1 = prompt_attractions | model | parser
chain2 = prompt_books | model | parser# 创建并行链
chain = RunnableParallel(attractions=chain1,books=chain2
)# 执行并行调用
result = chain.invoke({"city": "北京", "num": 3})
预期输出结果
{"attractions": [{"num": 1,"city": "北京","introduce": "故宫 - 明清两代皇宫,中国古代宫廷建筑的杰出代表"},{"num": 2,"city": "北京","introduce": "天坛 - 明清皇帝祭天的场所,中国古代建筑艺术的瑰宝"},{"num": 3,"city": "北京","introduce": "长城 - 中国古代军事防御工程,世界文化遗产"}],"books": [{"num": 1,"city": "北京","introduce": "《北京往事》- 描述老北京风土人情的经典作品"},{"num": 2,"city": "北京","introduce": "《北京故事》- 展现北京历史变迁的文学作品"},{"num": 3,"city": "北京","introduce": "《北京文化》- 深入解析北京文化内涵的学术著作"}]
}
总结
RunnableParallel作为LangChain框架中的重要组件,为开发者提供了高效的并行处理能力。通过合理运用RunnableParallel,可以显著提升AI应用的处理效率,特别是在需要多维度数据分析或多模型对比的场景中。其简洁的API设计和强大的功能特性,使其成为构建复杂AI应用管道的理想选择。