[2025CVPR]DeepLA-Net:深度局部聚合网络解析
目录
引言:当点云分析遇到网络深度瓶颈
核心原理:极简而强大的局部特征提取
1. ResLFE块:10倍效率提升的奥秘
(1) 阶段级位置嵌入(Stage-Level Position Embedding)
(2) 向量特征表示(Vector Feature Representation)
(3) 现代化结构(Modernization Structure)
创新设计:让深度网络不再"难产"
1. 混合深度监督(HDS)策略
(1) 语义概率监督
(2) 空间分布监督
混合损失函数
实验验证:从分类到分割的全方位超越
1. S3DIS Area5分割结果
2. ScanNet v2分割结果
3. 关键可视化
代码实现:核心模块解析
1. ResLFE块实现
2. 混合监督训练
局限性与展望
结论
引言:当点云分析遇到网络深度瓶颈
3D点云分析是自动驾驶、机器人等领域核心技术,但点云的无序性、稀疏性给模型设计带来巨大挑战。传统局部聚合网络(LANet)通过复杂局部表示已逼近性能天花板(如S3DIS数据集性能停滞在73% mIoU)。本文提出颠覆性思路:通过加深网络层数而非优化局部表示来突破性能极限,就像2D图像领域通过加深CNN取得突破一样。

如上图所示,DeepLA-120首次突破75% mIoU大关,且参数量远低于Point Transformer v3。这验证了"深度优于复杂度"的新范式。
核心原理:极简而强大的局部特征提取

1. ResLFE块:10倍效率提升的奥秘
ResLFE块通过三项创新实现高效局部特征聚合:
(1) 阶段级位置嵌入(Stage-Level Position Embedding)
- 原问题:传统逐层位置嵌入导致计算量翻倍
- 解决方案:同一阶段共享位置嵌入
- 公式:
python
# 阶段级位置嵌入伪代码 stage_embedding = embedder(points) # BxNxC for layer in stage_layers:layer_output = layer(points, stage_embedding) - 效果:FLOPs减少50%(92.2G→44.6G),性能仅下降0.4%
(2) 向量特征表示(Vector Feature Representation)
- 原问题:分组特征计算量过大
- 解决方案:
- 特征抽象前置(Front-linear)
- 使用相对位置向量代替分组特征
- 通道拼接→通道相加
- 公式:Fout=max(Fik+PE)其中Fik=fi′−fi′k
- 效果:FLOPs骤降70%(44.6G→6.3G),性能反升1.2%
(3) 现代化结构(Modernization Structure)
- 灵感来源:Transformer的残差结构
- 改进点:
- 移除4x倒置瓶颈
- 添加DropPath正则化
- 公式:
python
# 简化版FFN实现 shortcut = x x = self.ffn(x) x = x + shortcut # 无维度扩展 - 效果:FLOPs减半(21.2G→9.2G),性能提升2.1%
创新设计:让深度网络不再"难产"
1. 混合深度监督(HDS)策略
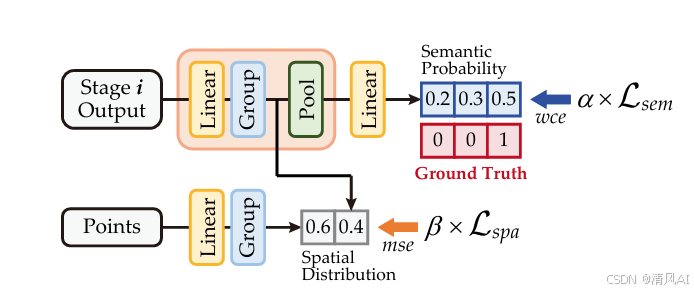
通过双路径监督加速梯度传播:
(1) 语义概率监督
- 目标:增强判别性特征学习
- 实现:
python
# 语义监督伪代码 for stage_feat in encoder_stages:logits = linear(stage_feat)loss_sem += F.cross_entropy(logits, labels) - 损失函数:Lsem=−N1i=0∑Nc=0∑Cyiclogpic
(2) 空间分布监督
- 直觉:早期特征应符合几何分布
- 实现:
python
# 空间监督伪代码 spatial_feats = learnable_linear(grouped_points) loss_spa += F.mse_loss(spatial_feats, grouped_feats) - 损失函数:Lspa=N1i=0∑N(pi−yi)2
混合损失函数
LH=αnLsem+βnLspa+(1−αn−βn)Lpred
通过指数衰减平衡两种监督,最终实现3.1% mIoU提升。
实验验证:从分类到分割的全方位超越
1. S3DIS Area5分割结果
| 方法 | mIoU | 参数量(M) | FLOPs(G) |
|---|---|---|---|
| PointNet++ | 53.5 | 3.1 | 11.3 |
| PointTransformer v3 | 73.4 | 24.1 | 58.5 |
| DeepLA-120 | 75.7 | 30.3 | 42.7 |
https://via.placeholder.com/600x400?text=Figure+2.+DeepLA-Net+family+performance
2. ScanNet v2分割结果
| 方法 | Val mIoU | Test mIoU |
|---|---|---|
| PointNeXt-XL | 71.5 | 71.2 |
| DeepLA-120 | 77.6 | 77.2 |
3. 关键可视化

深色区域表示类别区分度高,DeepLA-120展现出最清晰的类间边界。
代码实现:核心模块解析
1. ResLFE块实现
python
import torch.nn as nnclass ResLFEBlock(nn.Module):def __init__(self, in_channels, out_channels):super().__init__()self.stage_embed = nn.Linear(3, out_channels) # 阶段级位置嵌入self.vector_proj = nn.Sequential(nn.Linear(in_channels, out_channels),nn.BatchNorm1d(out_channels),nn.ReLU())self.ffn = nn.Sequential(nn.Linear(out_channels, out_channels),nn.Dropout(0.1),nn.Linear(out_channels, out_channels))def forward(self, points, features):# 阶段级位置嵌入stage_emb = self.stage_embed(points) # BxNxC# 向量特征表示proj_feat = self.vector_proj(features) # BxNxCrel_feat = proj_feat - proj_feat.unsqueeze(1) # BxNxKxC -> BxNxKxCrel_feat = rel_feat.sum(dim=2) # BxNxK# 现代化结构fused_feat = rel_feat + stage_emb # BxNxKfused_feat = self.ffn(fused_feat)return fused_feat2. 混合监督训练
python
def train_step(model, data, optimizer):points, labels = dataoptimizer.zero_grad()# 前向传播encoder_outs = model.encoder(points)logits = model.decoder(encoder_outs)# 计算损失loss_sem = F.cross_entropy(encoder_outs[-1], labels)loss_spa = F.mse_loss(encoder_outs[-1], points)loss_pred = F.cross_entropy(logits, labels)# 混合损失alpha = 0.3 * (1 / (epoch + 1))beta = 0.005 * (1 / (epoch + 1))total_loss = alpha*loss_sem + beta*loss_spa + (1-alpha-beta)*loss_predtotal_loss.backward()optimizer.step()局限性与展望
尽管DeepLA-Net在深度上取得突破,但仍存在以下挑战:
- 内存占用:120层网络需要24GB显存
- 小数据集表现:在ShapeNetPart等小数据集上增益有限
- 动态场景适配:尚未验证在动态点云(如激光雷达流)的表现
未来工作将探索:
- 更高效的深度监督机制
- 轻量化变体设计
- 动态场景下的时序建模
结论
DeepLA-Net通过极简设计和深度挖掘重新定义了点云分析范式。其核心启示在于:在局部表示趋近饱和时,网络深度的提升能带来性能的质变。这种思路可能引发3D视觉领域的新一轮架构革新。