[论文阅读]RaFe: Ranking Feedback Improves Query Rewriting for RAG
RaFe: Ranking Feedback Improves Query Rewriting for RAG
RaFe: Ranking Feedback Improves Query Rewriting for RAG - ACL Anthology
EMNLP 2024
RaFe,一个无需标注即可训练查询改写模型的框架。
直接使用原始查询进行检索并不总是能获得正确且相关的文档,因此查询改写已被广泛应用于重新表述查询,以扩展检索到的文档,从而获得更好的响应


【从图尝试读取方法:先拿普通query交给大模型输出一些重写结果,这些结果用于监督微调一个重写模型。还添加了反馈机制:离线反馈机制,拿LLM重写结果直接取检索,得到对应的检索结果,检索结果重排序,构造好-坏查询对,排序结果反馈给重写模型,再训练;在线反馈机制:重写模型的重写结果检索文档使用一个外部重排序器后,将排序结果返回给重写模型,然后再训练。】
【初看这个图存在一些疑问:①所谓的好-坏查询对是什么?为什么要这样构造?按理来说不是只拿好的结果反馈回去就可以了吗?②在线反馈机制里面,重排序结果是以什么样的内容返回给重写模型以反馈的?】
方法
目标是获得一个更好的重写模型
1.初始监督微调
首先使用冷启动监督微调来初始化重写模型,以获得重写能力:使用Qwen-max模型来获取重写数据
从大型语言模型生成的重写表示为Tall={(q,q′)|q′∈Q′},其中Q′是原始查询q的重写集。 将训练实例分成两部分Tall=[Tsft:Tf],其中Tsft和Tf分别表示用于监督微调和反馈训练的实例。 使用标准监督微调损失来训练重写模型ℳθ,如下所示:
![]()
【监督微调就是让小模型的结果向大模型的结果对齐】
对于每个查询,把所有相应的重写混合到一起进行训练,以增强训练模型的生成多样性,因为在实际应用中,需要针对单个搜索查询进行不同的重写以解决不同的方面或解释。
2.反馈训练
重新排序器可以作为查询重写的自然反馈。给定一个重新排序模型ℳr,用查询q对文档d进行评分的过程可以表示为ℳr(q,d)。 重写q′的排名得分可以表示为:

【意思是用重排序器对检索结果进行一个排名,这里用q而不是q‘是有讲究的,因为用户侧的输入始终是q本体,只有后台执行的时候会重写,然后用重写结果和对应的检索结果,再用户看来是问题q本身得到的检索结果是d',因此评估二者的排名得分,表征为q’的得分。每个文档的得分聚合后取平均】
离线反馈
利用重写查询检索到的每个文档的排名分数来构建偏好数据。
设置一个阈值来区分好的和坏的重写,表示为μ,计算方法如下,它是所有训练实例的平均排名分数:

对于每个得分超过阈值μ的重写q′,将其视为原始查询q的一个好的重写;否则,它被认为是一个坏的重写。 通过这种方式获得开放域问答的所有偏好对,形式为(q,qg′,qb′)。
离线反馈训练使用DPO(Direct preference optimization: Your language model is secretly a reward model,直接利用偏好对来优化模型)和KTO (Human-centered loss functions (halos))
KTO是一种可以根据反馈优化模型的方法,只需要重写q′是否良好的信号,而不需要成对的数据,其公式表示为(q,q′;ρ),ρ∈[good, bad]。
DPO损失:β 是 DPO 的温度参数,ℳθ 是待更新的重写模型,而 ℳref 是训练阶段的固定模型。

【这个就回答了我的第一个疑问:直接偏好优化方案需要正例和负例,目的是使模型更倾向于生成高分重写结果】
KTO损失函数:只需要一个信号来指示重写q′是否良好,其公式为(q,q′;ρ),ρ∈[good, bad]

λgood 和 λbad 的默认值设置为 1。 当好样本和坏样本的数量之间存在不平衡时,特定值将根据以下公式确定:

【这个KTO损失就不需要构造好-坏对了,因为只需要单个重写的好坏标签,上面的ρ就是标签】
在线反馈
排名分数也可以作为在线反馈信号。 利用近端策略优化 (PPO) 算法(一种强化学习算法)来实现在线反馈训练。 训练过程包括重写、检索、评分并最终提供反馈,如图2(2b)所示。
PPO损失:

【我的第二个疑问对应的回答:PPO策略这里就像是猜词游戏,每次猜词(生成重写结果)后,都会有一个重排序器告诉系统当前结果的得分(目标是让这个得分更大),相当于“接近”还是“远离”既定目标,根据当前反馈调整下一次的生成策略。
强化学习需要奖励机制:奖励=重排序器的打分-模型的变化程度(用KL散度防止模型突然对重写结果乱改。
广义优势估计(GAE):通过价值网络 Vϕ(st) 计算优势函数,平衡即时奖励与未来奖励的累积效应,就是公式9。目标函数有策略损失和价值损失组成,通过clip操作限制策略更新范围,避免性能退化,对应公式10】

实验设置
英文数据集:NQ,TriviaQA,HotpotQA。从这三个数据集的训练集中随机收集6w个实例来进行Tall(LLM的重写结果)训练重写模型。使用NQ和TriviaQA的测试集、HotpotQA的dev集作为评估著聚集,使用FreshQA进行域外评估
中文数据集:使用WebQA进行域内评估,FreshQA(翻译版)进行域外评估:首先翻译了全部 500 个 FreshQA 测试问题,然后手动审查和过滤每个翻译结果,以识别那些与中文互联网相对更相关的翻译。 最终获得了一个包含 293 个中文翻译 FreshQA 数据集。

评估设置:
实际的检索场景中,查询重写技术通常用来扩展原始查询得到的对应文档,然后把扩展的文档集合重排序,因此两种实验设置来验证RaFe:
- 替换:直接把查询改写后结果得到的检索文档D'替换原始的查询得到的检索文档D(只使用重写后得到的检索结果)
- 扩展:生成两个改写后的查询,分别对应检索到D0'和D1',把D和D'共计三个问题检索的结果全都拿来用
两种应用检索文档的设置:
- 直接原样使用,按照默认顺序链接前5个检索得到的文档,对扩展操作,从D,D0',D1'顺序循环选择top文档来组合。
- 重排序:把所有检索到的文档合并后重新排名,取top5
使用精确匹配EM指标来评估一般问答性能。使用Rouge-L分数评估FreshQA中的false premise集合
这个工作重点关注的是开放域问答,没有golden document或者相关的标注,因此通过确定检索到的文档中是否包含正确答案来评估检索效果,使用Precision@K和平均倒数排名MRR
baseline:
- 原始查询检索Origin Query Retrieval,OQR:使用原查询检索,利用搜索引擎返回的默认排序结果中的文档
- 大模型改写:few-shot方案改写原始查询(使用Qwen-max)
- Query2Doc:用LLM的few shot创建伪文档,用生成的伪文档扩展查询进行检索 提示词如下
- SFT有监督微调:使用预生成的改写结果直接训练改写模型。SFT(Tsft)表示专门针对Tsft训练的改写模型,而SFT(Tall)表示针对Tall训练的模型。

检索器:使用一个用于开放领域的匿名内部搜索引擎来为中文数据集检索文档,并使用Google搜索来检索英文数据集。利用搜索结果页面的标题和摘要片段作为检索增强文档。
基础模型:Qwen-max生成响应,Qwen1.5-32b-chat进行评估。查询重写模型用Qwen-7b-base训练
重排序器:使用公开可用的 bge-reranker来进行开放域问答实验
结果
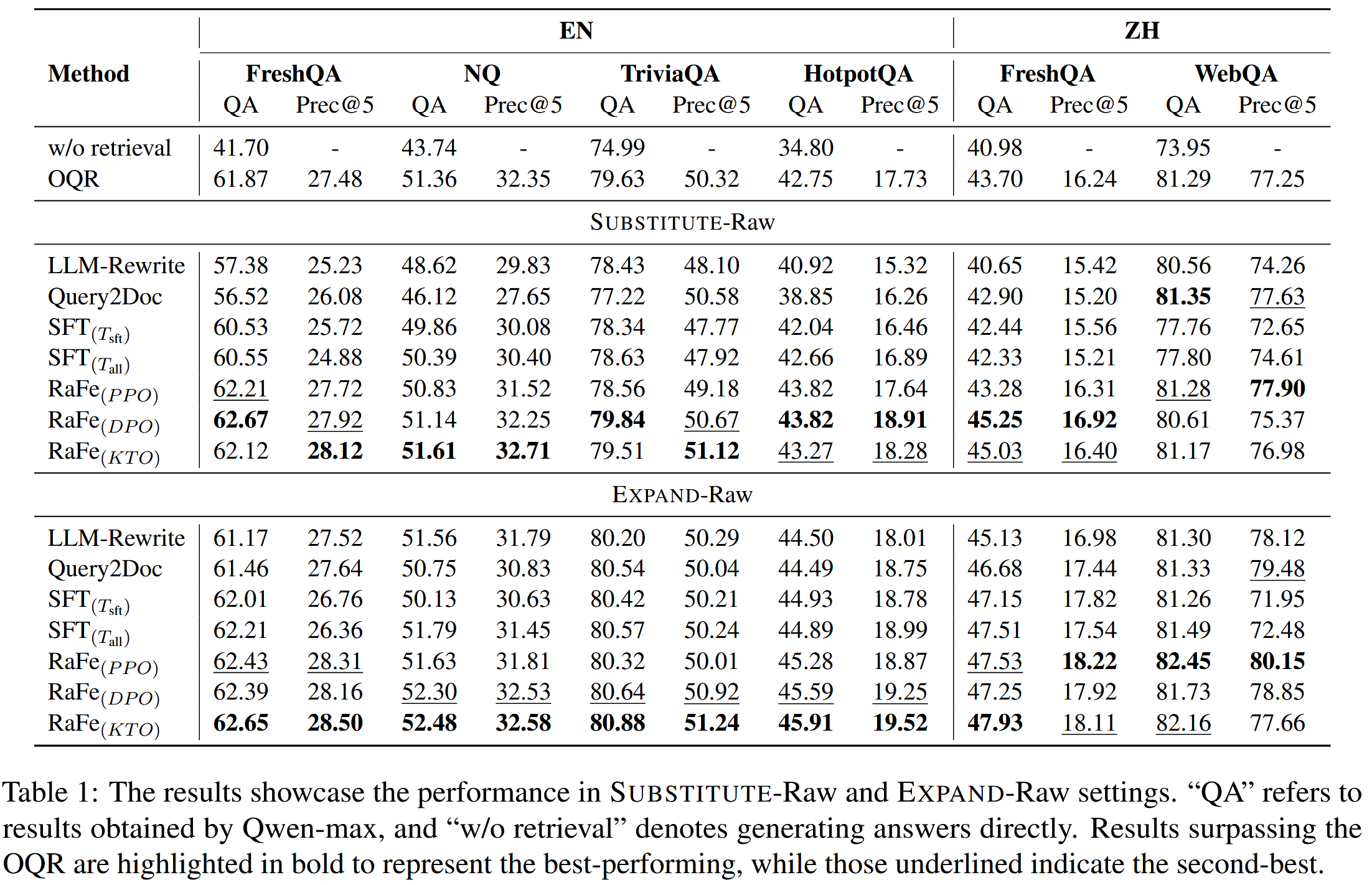

在检索和问答指标方面,RaFe 在几乎所有设置下都优于其他查询重写基线和 OQR。
在SUBSTITUTE-Raw设置下,RaFe的性能提升较小,但在EXPAND-Raw和EXPAND-Ranked设置下,RaFe的性能显著优于其他方法,包括原始查询检索(OQR)。


与其他类型的反馈进行了比较,包括基于LLMs的QA结果反馈和基于检索精度的反馈。结果表明,RaFe在大多数情况下优于这些方法,并且在成本上更具优势。

RaFe的优势可以概括为三种类型。
(A):RaFe在保留原始查询的语义方面表现更好。 如图3(A)所示,可以观察到,RaFe在经过reranker对齐后,可以以更好地保留原始查询语义的方式改写查询。 相比之下,SFT的改写直接将查询的重点从哪个运动员转移到哪个比赛。
(B):RaFe的改写改进了查询的格式,以便于检索。 RaFe的改写能够将不常见的术语“recipient”(接受者)转换为“winner”(获胜者)。 虽然SFT改写也用“winner”替换了“recipient”,但它将“team”(团队)从体育比赛的语境改为“squad”(小队),这是一个通常用于军事、警察或其他语境的术语,从而引入了潜在的歧义。
(C): RaFe重写句子以提高理解度。 这类案例仅凭直觉难以判断好坏;然而,RaFe的重写结果在检索结果中表现更好。 此类案例表明了为什么我们需要反馈来增强QR的有效性,因为我们总是无法清晰表达如何格式化查询以更好地适应检索器。

在所有数据集上对文档进行排序后,所有方法的QA性能都得到了提高。 这表明重新排序器的文档排序模式对检索系统起到了积极作用。观察到RaFe在排序后取得了更好的改进,这进一步证明了重新排序器反馈的有效性。

比较了不同查询检索到的文档的精确度。验证了重新排序器在Tf中构建优劣样本对的有效性。与原始查询检索到的文档相比,通过好的改写检索到的文档的精确度显著提高,这表明重新排序器能够有效地区分能够检索高质量文档和无法检索高质量文档的改写。

当有 4-5 次改写时,QA 结果达到峰值,这表明采用更多改写可以通过检索更多相关的顶级文档来产生可观的收益。 然而,Prec@5 在 2-3 次改写左右就接近最佳值。 对所有段落进行排序时,只需 2 次改写即可达到性能上限。 考虑到时间成本,2-3 次改写可能对实际 RAG 最有益。
结论
提出了一种名为RaFe的新型反馈训练框架,用于查询重写,该框架基于重排序器在信息检索过程中增强文档排序的有效性。 通过利用来自重排序器的反馈信号,RaFe能够有效且普遍地对重写模型进行反馈训练,从而产生巨大的改进。